Sansan Data Hubは、社内の顧客データを整理・統合し、マーケティング目的に最適なデータに変換することを支援します。この連携により、Sansan Data HubのコンテンツをTreasure Dataにインポートできます。
- Treasure Data™の基礎知識
- Sansan Data Hubの基礎知識
- 90日以前のデータの取得のみをサポート
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
- 認証情報のセットを使用して新しい認証を作成するには、次の手順を実行します。
- Integrations Hubを選択します。
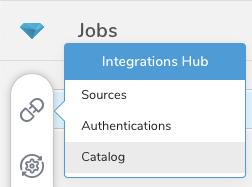
- Catalogを選択します。
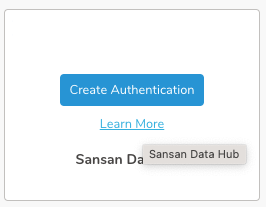
- カタログで連携を検索し、アイコンの上にマウスを置いてCreate Authenticationを選択します。
- Credentialsタブが選択されていることを確認し、連携の認証情報を入力します。
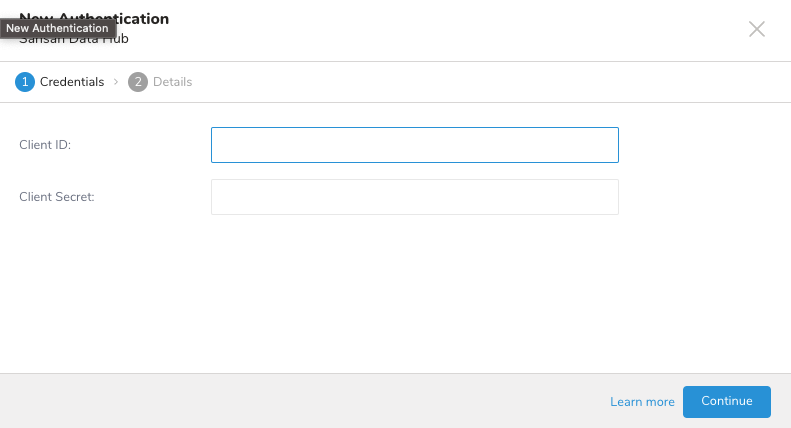
| パラメータ | 説明 |
|---|---|
| Client ID | アカウントのクライアントID |
| Client Secret | アカウントのクライアントシークレット |
- 認証の名前を入力し、Doneを選択します。
- TD Consoleを開きます。
- Integrations Hub > Authenticationsに移動します。
- 新しい認証を見つけて、New Sourceを選択します。
| パラメータ | 説明 |
|---|---|
| Data Transfer Name | 転送の名前を定義できます。 |
| Authentication | 転送に使用する認証名。 |
- Data Transfer Nameフィールドにソース名を入力します。
- Nextを選択します。
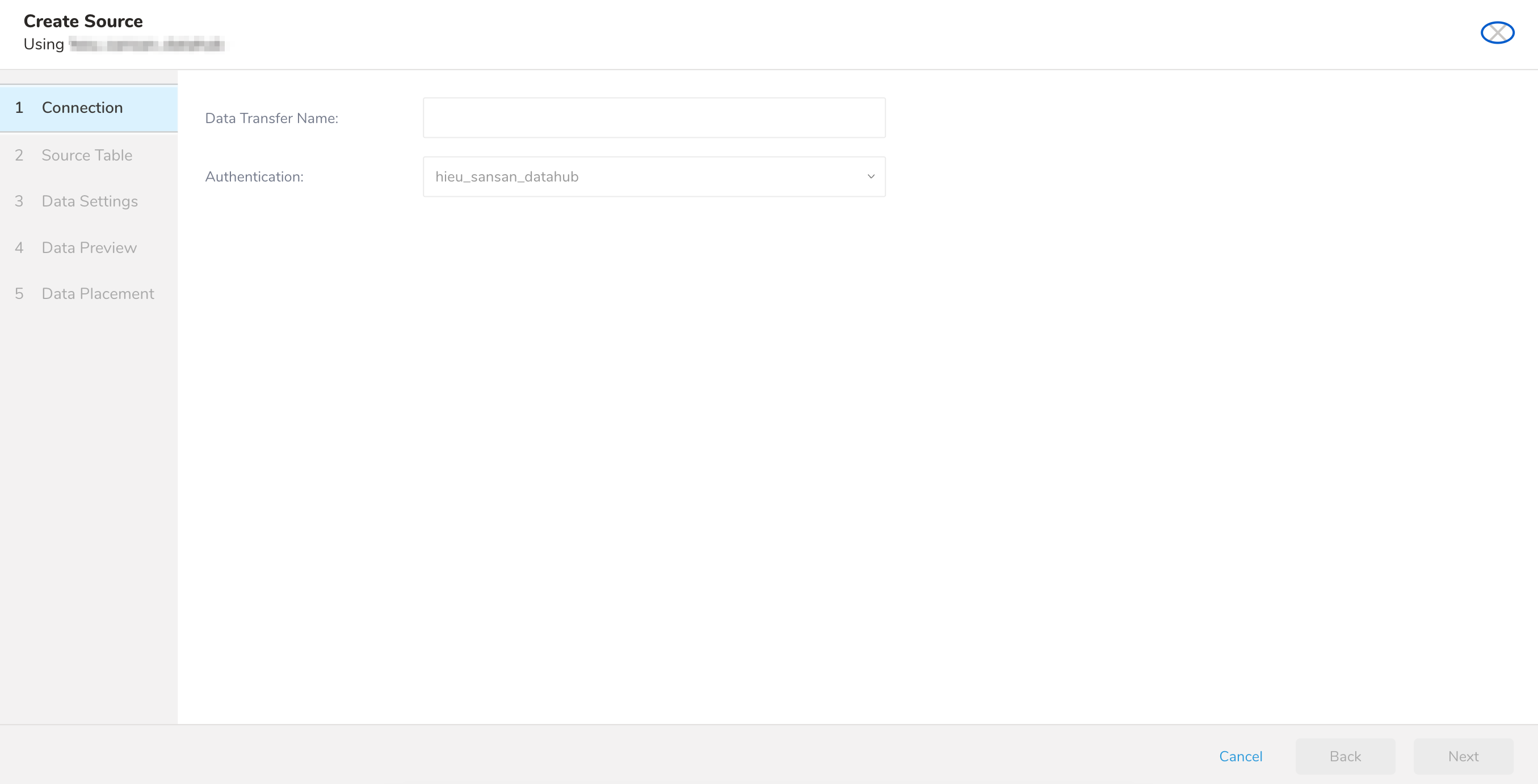
Source Tableタブが選択された状態で、Create Sourceページが表示されます。
- パラメータを編集します
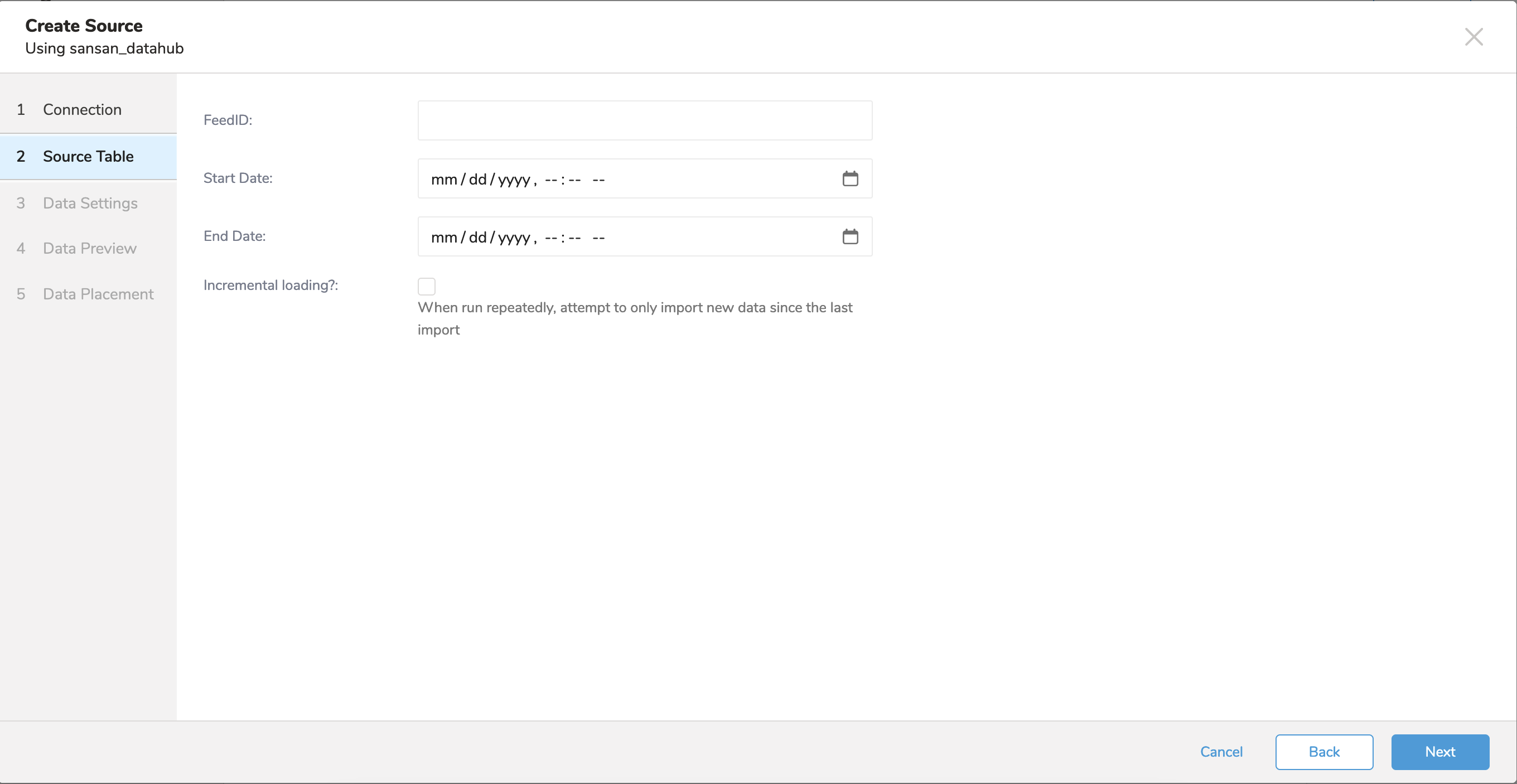
顧客は、データ連携の前に設定シート(Change Feed API)で出力設定を完了し、Sansanに提出する必要があります。Sansanは、feedIDやクライアントIDとクライアントシークレットの取得方法などを含む設定シートを返します。Integration hubの認証にクライアントIDとクライアントシークレットを設定し、インポートしたい設定シートに従ってfeedIDを設定する必要があります。各設定シートには5種類のfeedIDがあります: - 会社(法人・組織)単位 (Organization Unit) - 拠点単位 (Branch/Location Unit) - 人物単位 (Individual Unit) - 名刺単位 (Name Card Unit) - 取込CSV (Import CSV)
| パラメータ | 必須 | 説明 |
|---|---|---|
| Feed ID | はい | インポートするオブジェクトのID |
| Start Date | はい | 開始日 |
| End Date | いいえ | 終了日 |
| Incremental | いいえ | 増分モードでジョブを実行することを有効化 |
- Nextを選択します。
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示できます。Data preview はオプションであり、選択した場合はダイアログの次のページに安全にスキップできます。
- Next を選択します。Data Preview ページが開きます。
- データをプレビューする場合は、Generate Preview を選択します。
- データを確認します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
ワークフローのtd_load>: オペレータを使用して、Sansan Data Hubからデータをインポートできます。すでにSOURCEを作成している場合は実行できます。SOURCEを作成したくない場合は、ymlファイルを使用してインポートできます。
- ソースを特定します。
- 一意のIDを取得するには、ソースリストを開き、Sansan Data Hubでフィルタリングします。
- メニューを開き、「Copy Unique ID」を選択します。
- td_load>オペレータを使用してワークフロータスクを定義します。
+load:
td_load>: unique_id_of_your_source
database: ${td.dest_db}
table: ${td.dest_table}- ワークフローを実行します。
- ymlファイルを特定します。ymlファイルを作成する必要がある場合は、参考としてAmazon S3 Import Integration Using CLIを確認してください。
- td_load>オペレータを使用してワークフロータスクを定義します。
+load:
td_load>: unique_id_of_your_source
database: ${td.dest_db}
table: ${td.dest_table}- ワークフローを実行します
| 名前 | 説明 | 値 | デフォルト値 | 必須 |
|---|---|---|---|---|
| client_id | クライアントID | true | ||
| client_secret | クライアントシークレット | true | ||
| feed_id | データを取得したいフィードのID | true | ||
| start_date | データを取得する開始日 | true | ||
| end_date | データを取得する終了日 | false | ||
| incremental | 増分モードで実行することを有効化 | false | false | |
| columns | カラム名とデータ型 | true |
サンプルワークフローコードについては、Treasure Boxesを参照してください。
コネクタを設定する前に、最新のTD Toolbeltをインストールしてください。
in:
type: sansan_datahub
client_id: ***
client_secret: ***
feed_id: feed_id
start_date: "2023-07-22T00:00:00.000Z"
end_date: "2023-08-22T00:00:00.000Z"
incremental: false
out:
mode: append| 名前 | 説明 | 値 | デフォルト値 | 必須 |
|---|---|---|---|---|
| client_id | クライアントID | true | ||
| client_secret | クライアントシークレット | true | ||
| feed_id | データを取得したいフィードのID | true | ||
| start_date | データを取得する開始日 | true | ||
| end_date | データを取得する終了日 | false | ||
| incremental | 増分モードで実行することを有効化 | false | false | |
| columns | カラム名とデータ型 | true |
データコネクタは、指定されたプレフィックスに一致するすべてのファイルをインポートします。
path_prefix: path/to/sample_ –> path/to/sample_201501.csv.gz, path/to/sample_201502.csv.gz, …, path/to/sample_201505.csv.gz
connector:guessを使用します。このコマンドは、ソースファイルを自動的に読み取り、ロジックを使用してファイル形式とそのフィールド/カラムを推測します。
$ td connector:guess seed.yml -o load.ymlload.ymlを開いて、ファイル形式、エンコーディング、カラム名、型などのファイル形式定義を確認できます。
in:
type: sansan_datahub
client_id: ***
client_secret: ***
feed_id: feed_id
start_date: "2023-07-22T00:00:00.000Z"
end_date: "2023-08-22T00:00:00.000Z"
incremental: false
columns:
- {name: tdb.latestIncomeAccountingTerm, type: string}
- {name: nta.addressInside_postalCode, type: long}
...
out:
mode: appendデータをプレビューするには、td connector:preview コマンドを使用します。
$ td connector:preview load.yml
+-------+---------+----------+---------------------+
| id | company | customer | created_at |
+-------+---------+----------+---------------------+
| 11200 | AA Inc. | David | 2015-03-31 06:12:37 |
| 20313 | BB Imc. | Tom | 2015-04-01 01:00:07 |
| 32132 | CC Inc. | Fernando | 2015-04-01 10:33:41 |
| 40133 | DD Inc. | Cesar | 2015-04-02 05:12:32 |
| 93133 | EE Inc. | Jake | 2015-04-02 14:11:13 |
+-------+---------+----------+---------------------+guess コマンドは、ソースデータファイルのサンプル行を使用してカラム定義を評価するため、ソースデータに3行以上、2列以上が必要です。
システムがカラム名やカラム型を予期せず検出した場合は、load.yml ファイルを修正して再度プレビューしてください。
ロードジョブを送信します。 データのサイズによっては数時間かかる場合があります。データを格納する Treasure Data のデータベースとテーブルを必ず指定してください。
Treasure Data のストレージは時間で分割されているため(データパーティショニングを参照)、--time-column オプションを指定することを推奨します。このオプションが指定されていない場合、データコネクタは最初の long または timestamp カラムをパーティショニング時刻として選択します。--time-column で指定するカラムの型は、long または timestamp のいずれかである必要があります。
データに時間カラムがない場合は、add_time フィルタオプションを使用して時間カラムを追加できます。詳細については、add_time フィルタプラグインを参照してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table \
--time-column created_atconnector:issue コマンドは、database(td_sample_db) と table(td_sample_table) がすでに作成されていることを前提としています。TD にデータベースまたはテーブルが存在しない場合、このコマンドは失敗します。データベースとテーブルを手動で作成するか、td connector:issue コマンドで --auto-create-table オプションを使用してデータベースとテーブルを自動作成してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table
--time-column created_at --auto-create-tableデータコネクタはサーバー側でレコードをソートしません。時間ベースのパーティショニングを効果的に使用するには、事前にファイル内のレコードをソートしてください。
time というフィールドがある場合は、--time-column オプションを指定する必要はありません。
$ td connector:issue load.yml --database td_sample_db --table td_sample_tableload.yml ファイルの out セクションでファイルインポートモードを指定できます。out: セクションは、データを Treasure Data テーブルにインポートする方法を制御します。たとえば、Treasure Data の既存のテーブルにデータを追加するか、データを置き換えるかを選択できます。
| モード | 説明 | 例 |
|---|---|---|
| Append | レコードがターゲットテーブルに追加されます。 | in: ... out: mode: append |
| Always Replace | ターゲットテーブルのデータを置き換えます。ターゲットテーブルに対して手動で行われたスキーマ変更はそのまま保持されます。 | in: ... out: mode: replace |
| Replace on new data | インポートする新しいデータがある場合にのみ、ターゲットテーブルのデータを置き換えます。 | in: ... out: mode: replace_on_new_data |
増分ファイルインポートのために、定期的なデータコネクタの実行をスケジュールできます。Treasure Data は、高可用性を確保するためにスケジューラを慎重に構成しています。
スケジュールされたインポートでは、指定されたプレフィックスに一致し、次のいずれかのフィールドを条件とするすべてのファイルをインポートできます。
- use_modified_time が無効の場合、最後のパスが次回の実行のために保存されます。2回目以降の実行では、コネクタはアルファベット順で最後のパス以降のファイルのみをインポートします。
- それ以外の場合、ジョブが実行された時刻が次回の実行のために保存されます。2回目以降の実行では、コネクタはアルファベット順でその実行時刻以降に変更されたファイルのみをインポートします。
td connector:create コマンドを使用して新しいスケジュールを作成できます。
$ td connector:create daily_import "10 0 * * *" \
td_sample_db td_sample_table load.ymlTreasure Data のストレージは時間で分割されているため(データパーティショニングも参照)、--time-column オプションを指定することを推奨します。
$ td connector:create daily_import "10 0 * * *" \
td_sample_db td_sample_table load.yml \
--time-column created_atcron パラメータは、@hourly、@daily、@monthly の3つの特別なオプションも受け入れます。
デフォルトでは、スケジュールは UTC タイムゾーンで設定されます。-t または --timezone オプションを使用してタイムゾーンでスケジュールを設定できます。--timezone オプションは、'Asia/Tokyo'、'America/Los_Angeles' などの拡張タイムゾーン形式のみをサポートします。PST、CST などのタイムゾーン略語はサポートされておらず、予期しないスケジュールにつながる可能性があります。
td connector:list コマンドを実行すると、現在スケジュールされているエントリのリストを確認できます。
$ td connector:list
+--------------+--------------+----------+-------+--------------+-----------------+------------------------- ------+
| Name | Cron | Timezone | Delay | Database | Table | Config |
+--------------+--------------+----------+-------+--------------+-----------------+--------------------------------+
| daily_import | 10 0 * * * | UTC | 0 | td_sample_db | td_sample_table | {"in"=>{"type"=>"s3", "access_key_id"... |
+--------------+--------------+----------+-------+--------------+-----------------+--------------------------------+td connector:show は、スケジュールエントリの実行設定を表示します。
% td connector:show daily_import
Name : daily_import
Cron : 10 0 * * *
Timezone : UTC
Delay : 0
Database : td_sample_db
Table : td_sample_table
Config
---
in:
type: sansan_datahub
client_id: ***
client_secret: ***
feed_id: feed_id
start_date: "2023-07-22T00:00:00.000Z"
end_date: "2023-08-22T00:00:00.000Z"
incremental: false
columns:
- {name: tdb.latestIncomeAccountingTerm, type: string}
- {name: nta.addressInside_postalCode, type: long}
...td connector:history は、スケジュールされたエントリの実行履歴を表示します。各実行の結果を調査するには、td job jobid を使用します。
% td connector:history daily_import
+--------+---------+---------+--------------+-----------------+----------+---------------------------+----------+
| JobID | Status | Records | Database | Table | Priority | Started | Duration |
+--------+---------+---------+--------------+-----------------+----------+---------------------------+----------+
| 578066 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-18 00:10:05 +0000 | 160 |
| 577968 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-17 00:10:07 +0000 | 161 |
| 577914 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-16 00:10:03 +0000 | 152 |
| 577872 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-15 00:10:04 +0000 | 163 |
| 577810 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-14 00:10:04 +0000 | 164 |
| 577766 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-13 00:10:04 +0000 | 155 |
| 577710 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-12 00:10:05 +0000 | 156 |
| 577610 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-11 00:10:04 +0000 | 157 |
+--------+---------+---------+--------------+-----------------+----------+---------------------------+----------+
8 rows in settd connector:delete は、スケジュールを削除します。
$ td connector:delete daily_import