Amazon Marketing Cloud (AMC)とTreasure Data CDPを統合することで、広告主はAmazon Adsを使用して、Treasure DataからAMCに戦略的なCDPセグメントを仮名化された形式で渡すことができます。広告主は、CDPの入力とAmazon Adsのシグナルを組み合わせて、メディアの影響、オーディエンスセグメンテーション、セグメントの重複、カスタマージャーニーなどのトピックに関する独自のインサイトをプライバシー保護された方法で取得できます。Treasure Data CDPとAMCを統合することで広告キャンペーンをより効果的に推進する方法について詳しく学んでください。
このAmazon Marketing Cloud Export Integrationを使用すると、Treasure Dataからジョブ結果を書き込み、仮名化されたオーディエンスデータセットをAmazon Marketing Cloudに直接アップロードできます。
個人を特定できる情報(PII)フィールドは、SHA-256を使用してプログラムで正規化およびハッシュ化されます。PIIフィールドがすでにハッシュ化されている場合は、そのまま転送されます。ハッシュ化される識別子タイプ:EMAIL、FIRST_NAME、LAST_NAME、PHONE、ADDRESS、CITY。
- 仮名化されたオーディエンスデータセットをAmazon Marketing Cloudにアップロードする
- 既存のすべてのデータセット内のIDを削除する
- ルールベースのオーディエンスを作成し、Amazon DSPで直接アクティベートする
Amazon Marketing Cloudは、ハッシュ化または仮名化された情報のみを受け入れます。広告主のAMCインスタンス内のすべての情報は、Amazonのプライバシーポリシーに厳密に従って処理され、広告主のシグナルはAmazonによってエクスポートまたはアクセスされることはありません。広告主は、AMCから集約された匿名の出力のみにアクセスできます。
- TD Toolbeltを含むTreasure Dataの基本的な知識
- Amazon Marketing Cloud account
- Amazon Marketing Cloud accountへのアクセスを許可するS3 bucket
- AMCインスタンスに招待されたAmazon DSP account
- (オプション)Amazon Marketing Cloud Export Integrationを使用する前にdataset定義を作成する。dataset作成workflowの例については、Treasure Boxesを参照してください。このintegrationは、最初のactivation実行時にdatasetを作成することをサポートしています。
- Queryのカラムは、正確なカラム名(大文字小文字を区別しない)とデータタイプで指定する必要があります
- AMCインスタンスに紐づく既存のS3 bucketの使用は推奨されません。データアップロード用に新しいS3 bucketを作成してください
- Amazon DSPの最小オーディエンスサイズは2,000 identitiesです
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
https://advertising.amazon.com/marketing-cloudにログインします。
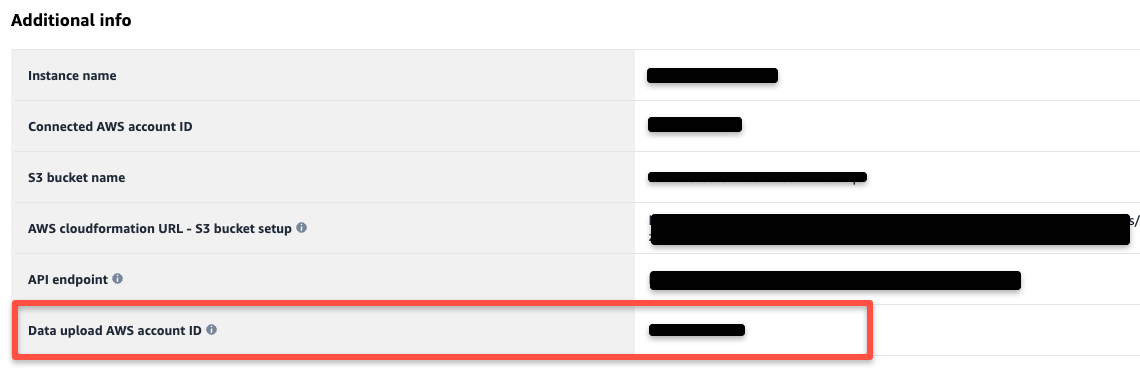
Amazon Marketing Cloudインスタンスにログイン後、以下の手順でAmazon Marketing CloudのInstance ID、Account ID、Data upload AWS account ID情報を取得します。
- Instance listからAmazon Marketing CloudのInstance IDを取得します。

- パラメータentityIdに割り当てられたAmazon Marketing CloudのAccount IDを確認します。

- Instance InfoページからData upload AWS account IDを取得できます。
最初のactivation時に、その場でデータセットを作成できます。その後の実行では、手動介入なしでdatasetが再利用されます。これには、dataset定義が設定されている必要があります。
以下は、dataset定義の例です。ターゲットdatasetが存在する場合は、このセクションをスキップできます。
ハッシュ化されたPIIカラムを含まないシンプルなDimension datasetの例
このdatasetには、product_asinとproduct_skuの2つのカラムがあります。queryからのスキーマがこれと一致しない場合、アップロードはエラーになります。
{ "dataSet": {"columns":[{"name": "product_asin","columnType": "DIMENSION","dataType": "STRING"},{"name": "product_sku","columnType": "METRIC","dataType": "STRING"}],"dataSetId": "mydemosimledimensionds","description": "my demo dimension dataset"}}ハッシュ化されたPIIとしてのemailとconsent typeとしてのTCFを含むfact datasetの例
この例では、3つのカラムがあります:email(hashedPIIとして)、record_date(isMainEventTime = Trueはこれがfact datasetであることを示します)、tcf_string(consentのtcf文字列)。
{"dataSet": {"dataSetId": "mydemofactdswithidentity","columns": [{"columnType": "DIMENSION","dataType": "STRING","externalUserIdType": {"hashedPii": "EMAIL"},"name": "email"},{"columnType": "DIMENSION","dataType": "DATE","isMainEventTime": true,"name": "record_date"},{"columnType": "DIMENSION","dataType": "STRING","name": "tcf_string","consentType": "TCF"}],"countryCode": "US"}}詳細なAmazonガイドラインについては、External Referenceセクションを確認してください。サポートが必要な場合は、テクニカルサポートチームにお問い合わせください。
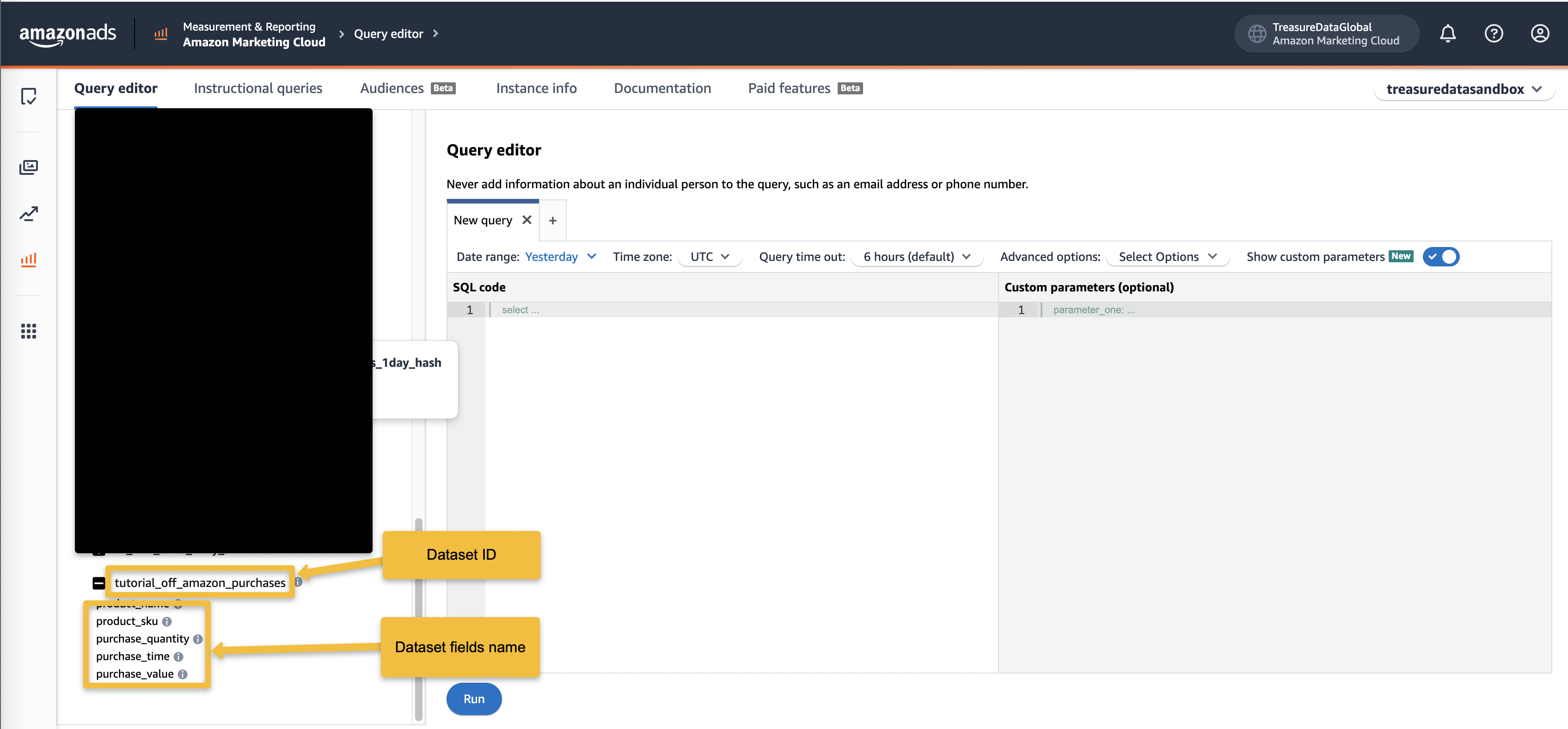
このintegrationを使用してdatasetを作成する場合、指定されたDataset IDは次回のactivation実行で再利用されます。Amazon Query editorページから取得する必要はありません。
- Amazon Query editorページから、Dataset IDとDataset Fields Nameを取得できます。
 2. infoアイコンを選択して、各filenameのデータタイプを取得します。
2. infoアイコンを選択して、各filenameのデータタイプを取得します。 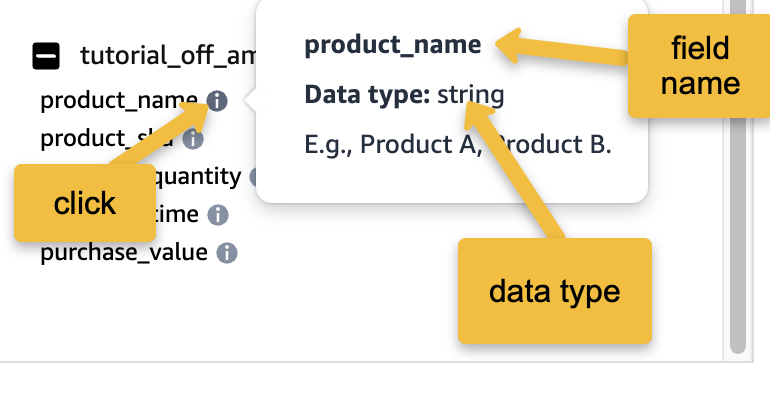
- S3にログインし、bucket > permissionタブに移動し、Bucket policyの下のEditを選択します。
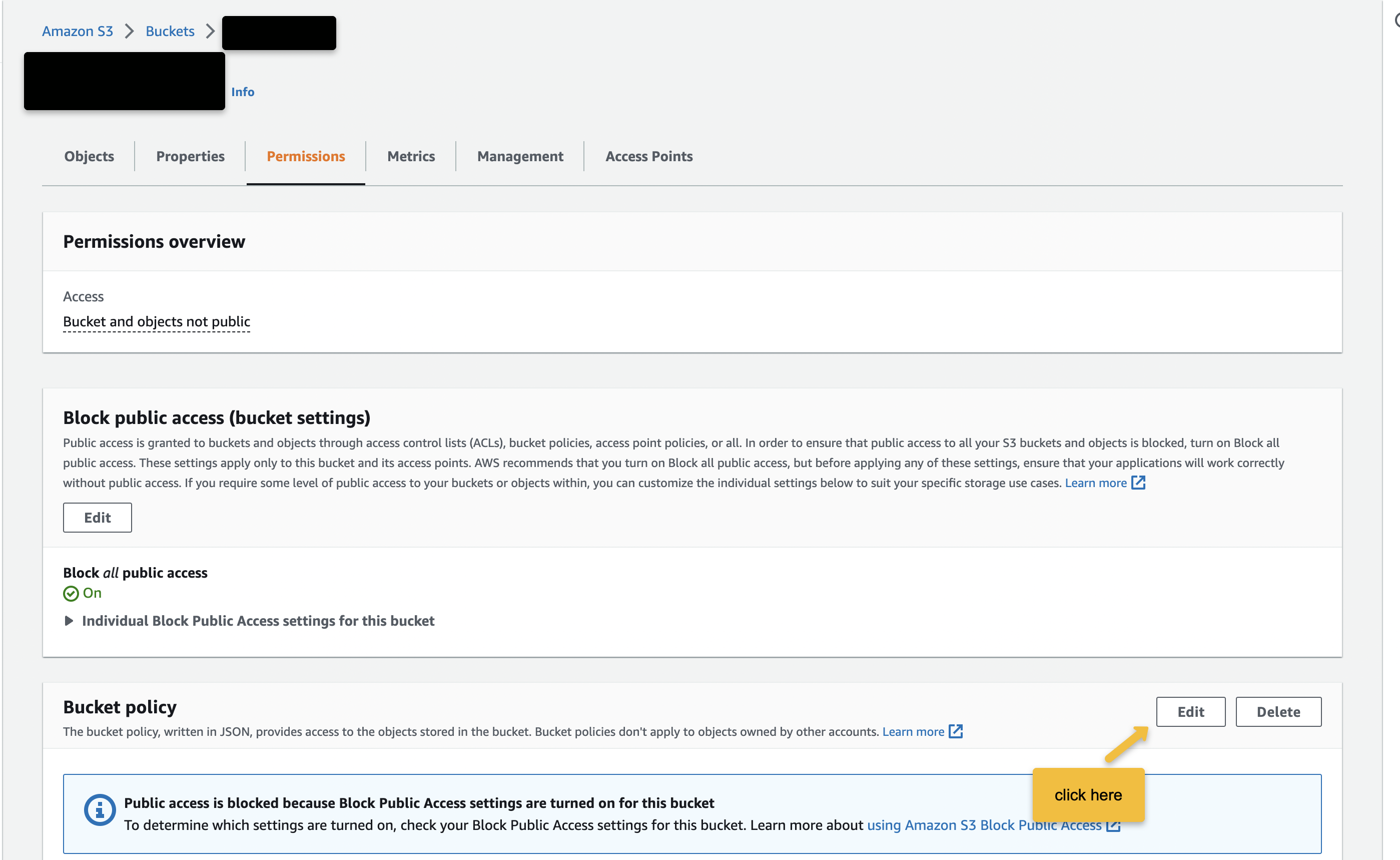 2. Data upload AWS account IDとBucket nameを置き換えた後、この設定をコピー&ペーストし、Saveを選択します。
2. Data upload AWS account IDとBucket nameを置き換えた後、この設定をコピー&ペーストし、Saveを選択します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::{{Data upload AWS account ID}}:root"
},
"Action": [
"s3:GetObject",
"s3:GetObjectVersion",
"s3:ListBucket",
"s3:PutObject",
"s3:PutObjectAcl",
"s3:GetObjectTagging",
"s3:GetBucketTagging"
],
"Resource": [
"arn:aws:s3:::{{bucket name}}/*",
"arn:aws:s3:::{{bucket name}}"
]
}
]
}- bucketのtagを定義する
インスタンスのtagを定義するには、以下の手順を実行します:
- Amazon S3コンソールに移動し、tagを関連付けるbucket名をクリックします。
- Propertiesをクリックし、Tagsセクションまでスクロールします。Editをクリックします。
- Add tagをクリックしてtagのkeyを定義し、keyの値を入力します。この目的では、key" "instance"d"と定義し、データのアップロードに使用するインスタンスの識別子をkeyの値として入力します。
- Saveをクリックします。
詳細については、https://advertising.amazon.com/API/docs/en-us/guides/amazon-marketing-cloud/advertiser-data-upload/advertiser-data-s3-bucketを参照してください。
queryを実行する前に、Treasure Dataでデータconnectionを作成して設定する必要があります。データconnectionの一部として、integrationにアクセスするためのauthenticationを提供します。
- TD Consoleを開きます。
- Integrations Hub > Catalogに移動します。
- Amazon Marketing Cloudを検索し、Amazon Marketing Cloudを選択します。

- New AuthenticationのClick hereリンクを選択して、新しいAmazon Accountに接続します。
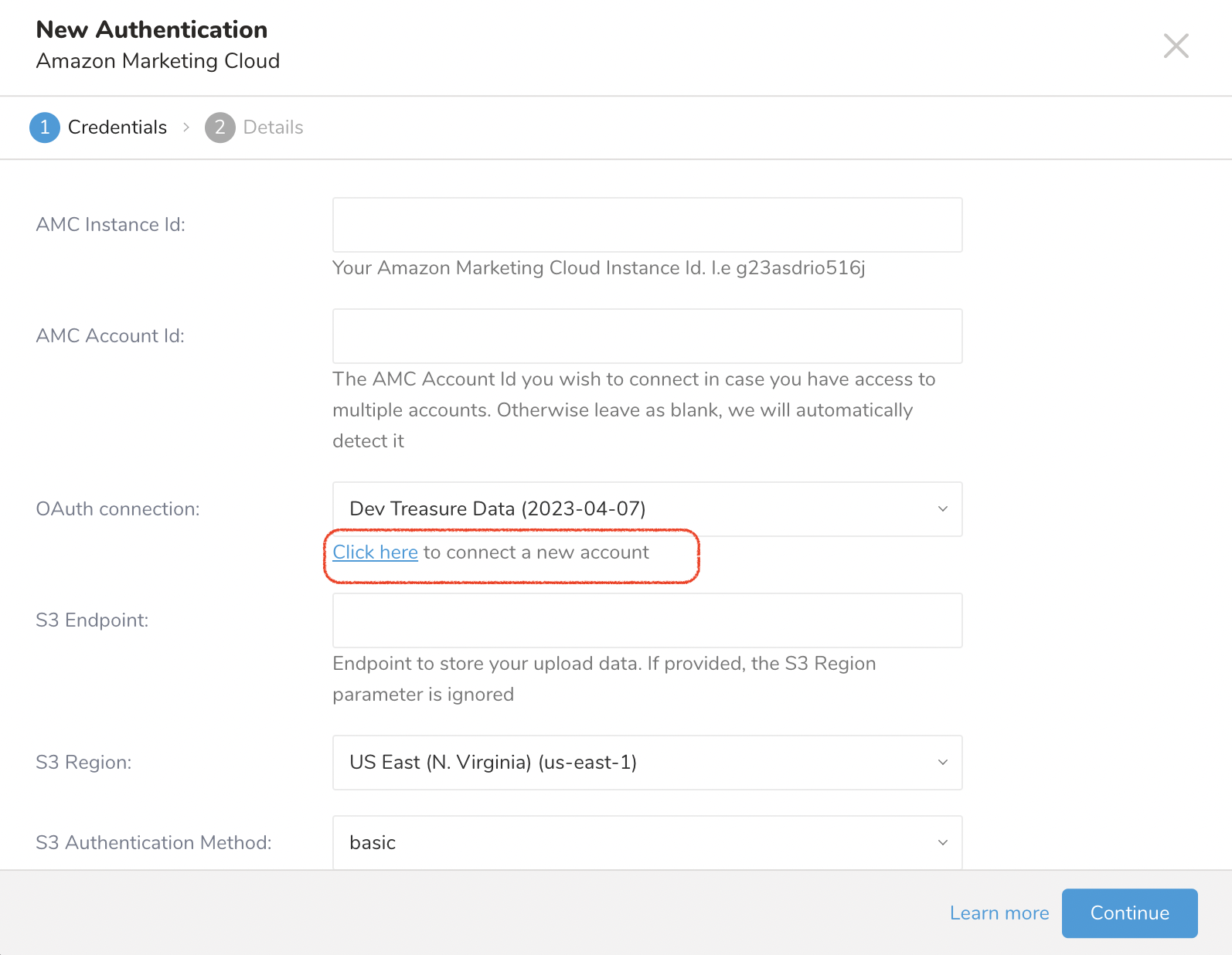
- Amazon Marketing Cloudインスタンスにリダイレクトされ、OAuthを使用してログインできます。usernameとpasswordを入力します。
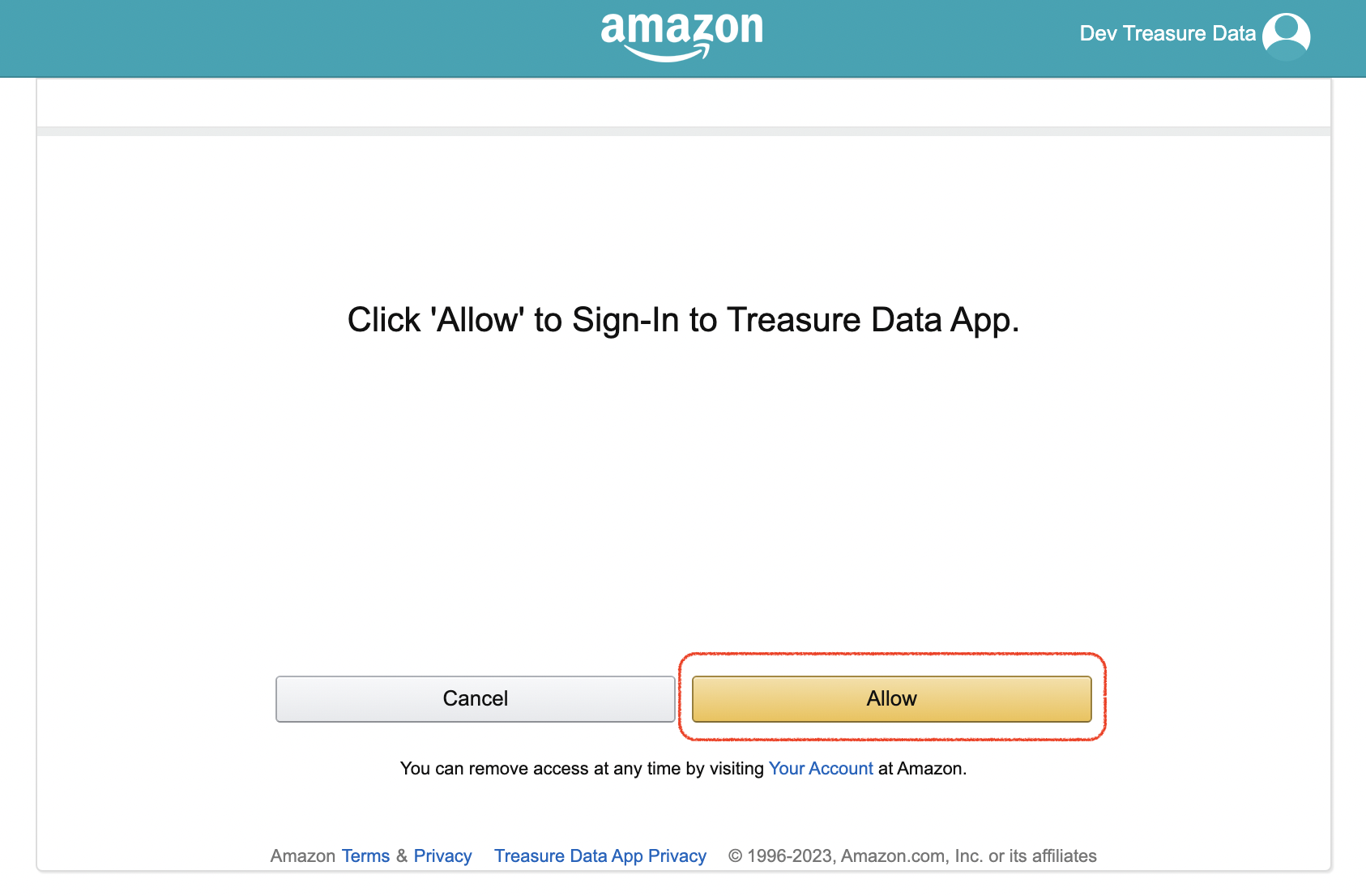
- Allowを選択してconsent screenを承認します。これにより、TD consoleにリダイレクトされます。
- 必要なcredentialsフィールドに入力します。
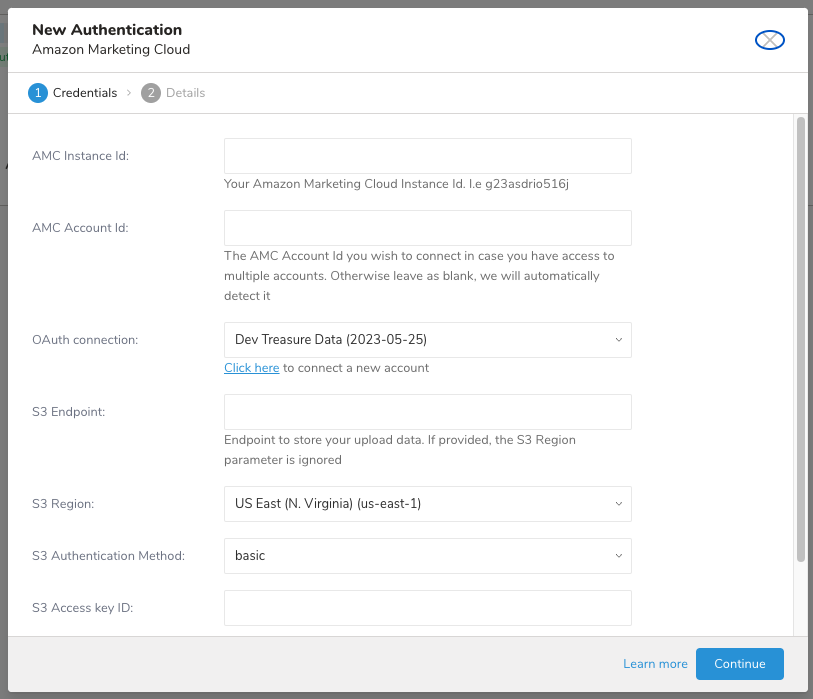
- Continueを選択します。
- authenticationの名前を入力します。
- Doneを選択します。
以下の表は、Amazon Marketing Cloud Export Integrationを設定するためのパラメータを説明しています。
| Parameter | Description |
|---|---|
| AMC Instance Id | Amazon Marketing Cloud Instance ID |
| AMC Account Id | Amazon Marketing Cloud Account ID。空白のままにすると、instance IDの最初のaccountが使用されます。 |
| S3 Endpoint | S3 service endpointオーバーライド。regionとendpoint情報は、AWS service endpointsドキュメントから確認できます(例:s3.ap-northeast-1.amazonaws.com)。指定すると、region設定を上書きします。 |
| S3 Region | AWS Region |
| S3 Authentication Method | 以下のauthenticationメソッドから選択します:
|
| Access Key ID | AWS S3から発行されたAccess Key ID |
| Secret Access Key | AWS S3から発行されたSecret Access Key |
| S3 Session token | 一時的なAWS Session Token |
| TD's Instance Profile | TD Consoleがこの値を提供します。値の数値部分が、IAM roleを作成するために使用するAccount IDを構成します。 |
| Account ID | AWS Account ID |
| Your Role Name | AWS Role Name |
| External ID | Secret External ID |
| Duration In Seconds | 一時的なCredentialsの期間 |
- Data Workbench > Queriesに移動します。
- New Queryを選択します。
- queryを実行して、結果セットを検証します。
- Export Resultsを選択します
既存のintegration authenticationを選択します。

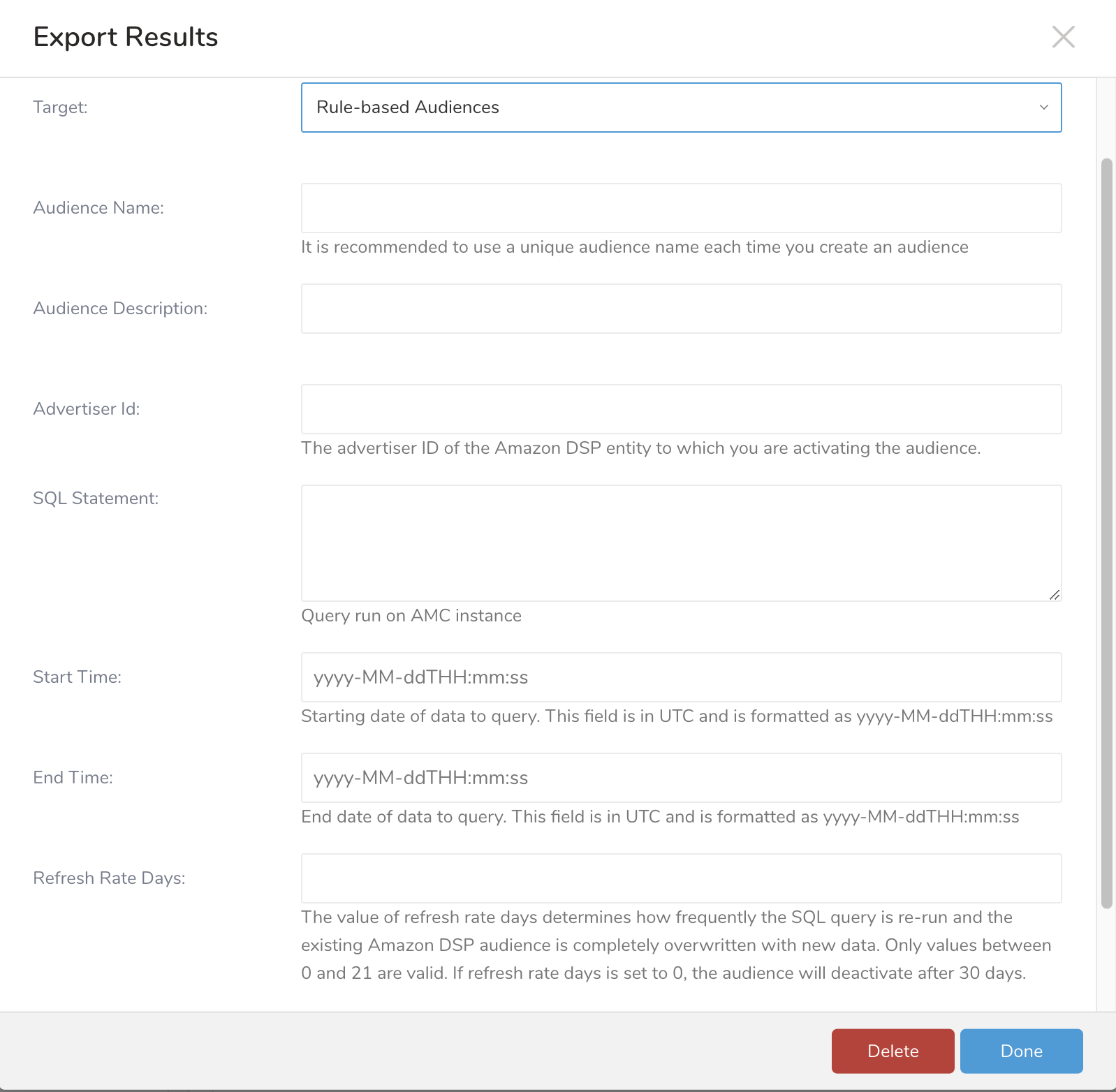
追加のExport Resultsの詳細を定義します。export integrationコンテンツで、integrationパラメータを確認します。
- Dataset Operationに対してUploadまたはDeleteを選択します。
"Create new dataset if it does not exist"をチェックして、その場で新しいdatasetを作成します。"Prepare Dataset as upload target"セクションで説明されているdataset定義を提供します。
以下の表は、Amazon Marketing Cloud export integrationの設定パラメータを説明しています。
| Parameter | Required | Description |
|---|---|---|
| Target | yes | 2つのtarget typeをサポート:
|
| For "AMC Data" Type | ||
| API version | yes、デフォルトはLatest | AMC version。値にはLatestのみが含まれます |
Dataset Operation | yes、targetがAMC datasetの場合 | Dataset operation: Upload: datasetにデータをアップロードする Delete: 既存のすべてのデータセットからidentitiesを削除する |
| Dataset Identifier | yes、targetがAMC datasetでdataset operationがuploadの場合 | データがアップロードされるdataset ID |
| Dataset Definition | "Create dataset if not exist"オプションがtrueの場合に必要 | ターゲットdatasetをJSON形式で定義する |
Update Strategy | yes、API versionがlatestの場合 | 値にはADDITIVE、FULL REPLACE、OVERLAP REPLACE、OVERLAP KEEPが含まれます 詳細については、https://advertising.amazon.com/API/docs/en-us/guides/amazon-marketing-cloud/advertiser-data-upload/advertiser-data-uploadを参照してください。 |
Country Code | アップロードされたデータのソース国はISO_3166-1_alpha-2形式です。 詳細については、https://en.wikipedia.org/wiki/ISO_3166-1_alpha-2#Officially_assigned_code_elementsを参照してください。 | |
| S3 Bucket | yes、targetがAMC datasetでdataset operationがuploadの場合 | S3 bucket名 |
| S3 Path | yes、targetがAMC datasetでdataset operationがuploadの場合 | データアップロードを保存するS3パス |
| File Name Prefix | ファイルアップロード名のprefix | |
| Wait Until The Operation Finish? | yes、targetがAMC datasetでdataset operationがuploadの場合 | AMC側でoperationが完了するまで待機する |
| Failed On Upload Status Error | チェックすると、AMCからのアップロードステータスレスポンスにエラーがある場合、オペレーションが失敗します。Wait Until The Operation Finish?がチェックされている場合のみ適用されます | |
| Clean Uploaded Files After Done? | 完了後、S3上のすべてのアップロードされたファイルを削除する | |
| Add The IAB European Transparency & Consent Framework (TCF) | チェックすると、TCF同意カラム(tcf_string)がまだ存在しない場合、データセットに追加されます。詳細はこちらを参照。 | |
| Add The Global Privacy Protocol (GPP) | チェックすると、GPP同意カラム(gpp_string)がまだ存在しない場合、データセットに追加されます。詳細はこちらを参照。 | |
| Add The Amazon Consent Signal (ACS) | チェックすると、ACS同意カラム(amazon_ad_storage、amazon_user_data)がまだ存在しない場合、データセットに追加されます。詳細はこちらを参照。 | |
| For "Rule-based Audiences" Type | ||
| Audience Name | yes、targetがRule-based Audiencesの場合 | |
| Audience Description | ||
| Advertiser Id | yes、targetがRule-based Audiencesの場合 | Amazon DSP上のAdvertiser ID |
SQL Statement | yes、targetがRule-based Audiencesの場合 | AMCインスタンス上で実行されるquery。 user_id(大文字小文字を区別)は常にSELECT文の一部である必要があります。オーディエンスはuser_idsから構築されます。 例: select user_id from tbl; |
| Start Time | yes、targetがRule-based Audiencesの場合 | queryするデータの開始日 |
| End Time | yes、targetがRule-based Audiencesの場合 | queryするデータの終了日 |
Refresh Rate Days | refresh rate daysの値は、SQL queryが再実行される頻度と、既存のAmazon DSPオーディエンスが新しいデータで完全に上書きされる頻度を決定します。0〜21の値のみが有効です。refresh rate daysが0に設定されている場合、オーディエンスは30日後に非アクティブになります。 デフォルト値: 21 | |
Time Window Relative | time window relativeパラメータを使用すると、refresh rate daysの値によってSQL queryの日付範囲をインクリメントできます。 デフォルト値: false |
- datasetにデータをアップロードするには、queryの結果にフィールド名(大文字小文字を区別)と一致するカラム名が必要です。queryカラムとdatasetフィールド間のすべての不一致は無視されます。
- FACT datasetにデータをアップロードする場合、メインイベント時刻カラムが必要です。
- datasetのすべてのnon-nullableフィールドがqueryに必要です。
- datasetフィールドがnon-nullableで、このフィールドのresult queriesの行にnull値がある場合、その行はスキップされます。例:
- メインイベント時刻フィールドとしてpurchase_timeを持つFACT dataset tutorial_off_amazon_purchasesがあります。すべてのフィールドはnon-nullableです。
サンプルquery:
SELECT
product_name,
product_sku,
product_quantity,
purchase_time,
purchase_value
FROM
table_name;また、aliasを使用してqueryカラム名をdatasetフィールドと一致させることもできます。サンプルquery:
SELECT
column_a AS product_name,
column_b AS product_sku,
column_c AS product_quantity,
column_d AS purchase_time,
column_e AS purchase_value
FROM
table_name注意:
- Add The IAB European Transparency & Consent Framework (TCF)がチェックされている場合、tcf_stringフィールドがqueryから文字列データ型で必要です。
- Add The Global Privacy Protocol (GPP)がチェックされている場合、gpp_stringフィールドがqueryから文字列データ型で必要です。
- Add The Amazon Consent Signal (ACS)がチェックされている場合、amazon_ad_storageとamazon_user_dataフィールドがqueryから文字列データ型で必要です。amazon_ad_storageとamazon_user_dataフィールドは文字列値「GRANTED」、「DENIED」、または「NULL」を受け付けます。
queryの結果の各カラムのデータタイプは、datasetフィールドと互換性がある必要があります。
| Column Data Type | Dataset Field Data type |
|---|---|
| STRING | STRING |
| DOUBLE | DECIMAL |
| LONG | INTEGER |
| LONG | LONG |
| TIMESTAMP | TIMESTAMP (yyyy-MM-ddThh:mm:ssZ) |
| TIMESTAMP | DATE (yyyy-MM-dd) |
| LONG (epoch second) | TIMESTAMP (yyyy-MM-ddThh:mm:ssZ) |
| LONG (epoch second) | DATE (yyyy-MM-dd) |
既存のすべてのデータセットからidentitiesを削除するには、queryの結果に少なくとも1つのidentityカラム名が必要です。identityカラム名には、first_name、last_name、email、phone、address、city、state、zip、およびcountry_codeを含める必要があります。他の名前のカラムは無視されます。サンプルquery:
SELECT
first_name,
last_name,
email
FROM
table_nameAudienceの作成には、TDからのデータは必要ありません。datasetからqueryを実行し、queryの結果に基づいてaudienceを作成します。したがって、TD側からjobをトリガーするために"Select 1"のみを使用します。TD側から1行を超える行を返すqueryは許可されません。
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
Scheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
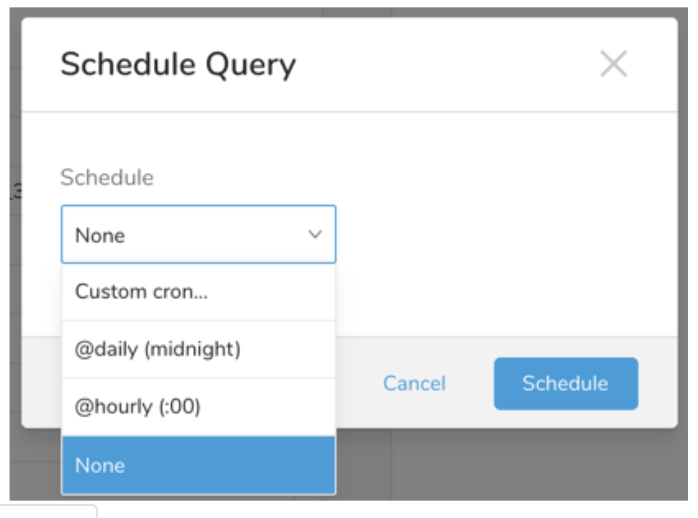
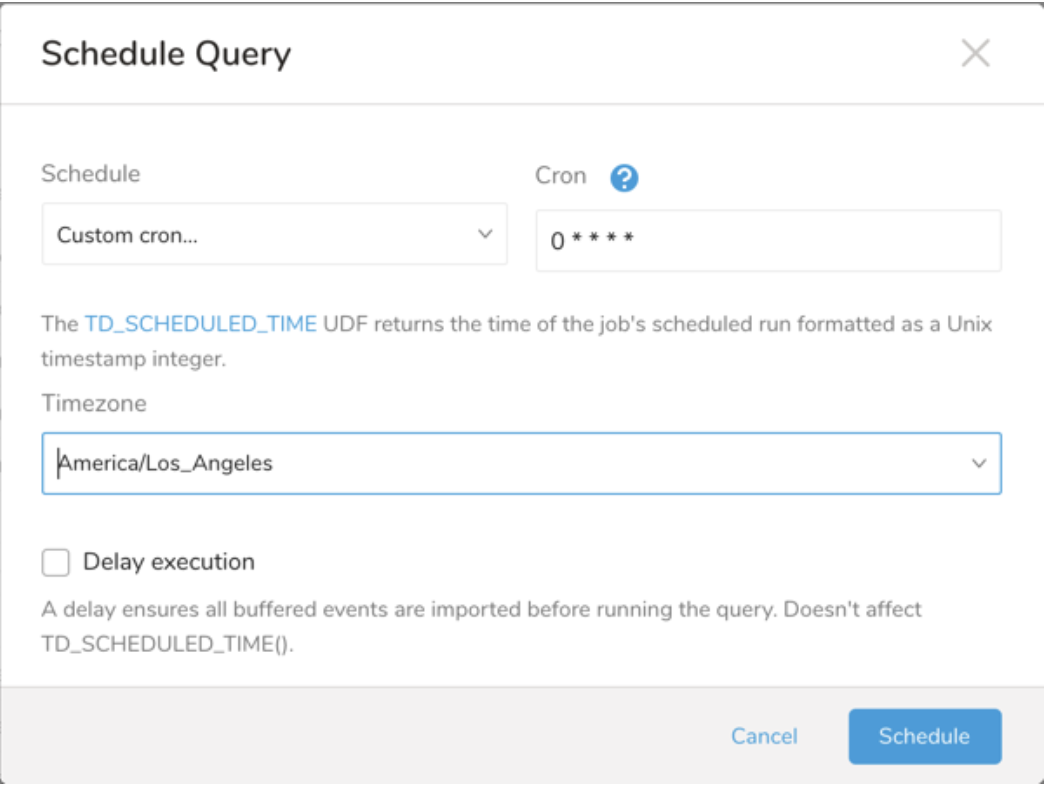
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
クエリに名前を付けて保存して実行するか、単にクエリを実行します。クエリが正常に完了すると、クエリ結果は指定された宛先に自動的にエクスポートされます。
設定エラーにより継続的に失敗するスケジュールジョブは、複数回通知された後、システム側で無効化される場合があります。
(オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
Treasure Workflow内で、このintegrationの使用を指定してデータをエクスポートできます。
Exporting Data with Parametersについて詳しく学んでください。
_export:
td:
database: amc_db
+amc_task:
td>: upload.sql
database: ${td.database}
result_connection: new_amc_auth
result_settings:
type: amazon_marketing_cloud
target: dataset
operation: upload
dataset_id: dataset_id
bucket: bucket_name
path_prefix: path_prefix/
file_name_prefix: file_name_prefix
wait_until_finish: true
failed_on_upload_status_error: false
clean_upload_file: true
add_consent_tcf: true
add_consent_gpp: true
add_consent_acs: true_export:
td:
database: amc_db
+amc_task:
td>: upload.sql
database: ${td.database}
result_connection: new_amc_auth
result_settings:
type: amazon_marketing_cloud
target: dataset
operation: upload
dataset_id: dataset_id
create_dataset: true
dataset_definition: dataset_definition_in_json_string
bucket: bucket_name
path_prefix: path_prefix
file_name_prefix: file_name_prefix
wait_until_finish: true
failed_on_upload_status_error: false
clean_upload_file: true
add_consent_tcf: true
add_consent_gpp: true
add_consent_acs: true_export:
td:
database: amc_db
+amc_task:
td>: delete.sql
database: ${td.database}
result_connection: new_amc_auth
result_settings:
type: amazon_marketing_cloud
target: dataset
operation: delete_export:
td:
database: amc_db
+amc_task:
td>: audience.sql
database: ${td.database}
result_connection: new_amc_auth
result_settings:
type: amazon_marketing_cloud
target: rule_based_audiences
amc_instance_id: amc_instance_id
amc_account_id: amc_account_id
audience_name: "test_audience"
audience_description: "test audience description"
advertiser_id: 123
query: "SELECT user_id FROM dsp_impressions"
time_window_start: "2023-06-25T00:00:00"
time_window_end: "2023-07-25T00:00:00"
refresh_rate_days: 1
time_window_relative: false- Fact vs. Dimension datasets: https://docs.aws.amazon.com/solutions/latest/amazon-marketing-cloud-uploader-from-aws/amc-fact-compared-with-dimension-datasets.html
- Dataset creation guideline: https://advertising.amazon.com/API/docs/en-us/guides/amazon-marketing-cloud/advertiser-data-upload/advertiser-data-sets