Amazon Demand-Side Platform (DSP)は、広告主がAmazon上またはAmazon外でディスプレイ、ビデオ、オーディオ広告をプログラマティックに購入できるようにします。Amazon DSPは、Amazonで製品を販売しているかどうかに関係なく、Amazon上の広告主が利用できます。AmazonのDSPを使用して、Amazonのサイト、アプリ、パブリッシングパートナー、サードパーティ取引所を通じてオーディエンスにリーチできます。
Amazon DSP Data Provider Export Integrationを使用すると、ハッシュ化されたメールや顧客情報などのセグメントデータをAmazon DSPにエクスポートできます。
- Amazon DSPの基本的な知識と広告主アカウント。
- Authentication、Queries、Results Export、および(オプションで)WorkflowなどのTreasure Data機能の基本的な知識。
External Audience IDは、Amazonでターゲットオーディエンスを指定するためのキーです。(すべてのオーディエンスに対して一意です。)このフィールドの値は、各広告主アカウントに対して一意になります。- ジョブが結果セットを複数のバッチに分割する場合があります。1つのバッチが失敗した場合、インテグレーションは正常にアップロードされたバッチを元に戻しません。
- インテグレーションは、Amazon DSP APIごとに必要なプレフィックス(COOKIE-またはMAID-)を追加します。結果セットにこれらのプレフィックスを手動で追加しないでください。
- インテグレーションはAudience Metadataを更新しません。
- Nullまたは空の列データは無視されます。
- 結果出力スキーマには、メタデータにcookieまたはmaid列、あるいはその両方が必要です。
Maidおよびcookie列はstringデータタイプである必要があります。cookieフィールドの最大長は1999文字です。- Amazon DSPへのPIIデータのエクスポートには、Amazon Ads Export Integrationの使用をお勧めします。このコネクタは異なるAPIパスウェイを使用し、より良いマッチパフォーマンスをもたらす可能性があります。
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
- external identifierを含むHashed Records Datasourceを準備します
- External identifier (external_id): ターゲット広告主の顧客プロファイルを表す一意のID。広告主IDとメール(または電話)の組み合わせから生成されたハッシュ番号の使用が推奨されます。 複数の顧客プロファイルが同じexternal identifier(例: ID: 12345)を使用すると、Amazon DSPのマッチングプロセスで上書きされ、マッチング率が低くなります。advertiser_idとemailの組み合わせを使用してexternal_idを生成する例:
- External_idはadvertiser_idとemailの組み合わせです:
SELECT
TO_HEX(SHA256(TO_UTF8(CONCAT(advertiser_id, email)))) AS external_id
FROM
table_name;- データコネクタ設定で、
hashed recordsデータソースを選択して、上記のデータをAmazon DSPに送信してマッチングします。 - マッチングプロセスはAmazon DSP内で開始されます。SLA (Service Level Agreement)は48時間に設定されています。この期間は、オーディエンス作成のためにアップロードされたexternal IDを利用するためにhashed record APIが呼び出されたときに開始されます。処理されるレコードの量に関係なく、SLAは一定であり、変更されないことに注意してください。
- オーディエンスへの追加またはオーディエンスからの削除:
- 追加または削除するオーディエンスのexternal_user_idテーブルを準備します。external_user_idはステップ1のexternal_idです
SELECT
external_id as external_user_id
FROM
TABLE_NAME- 次に、「Audiences」データソースを選択して結果をエクスポートします。
Treasure Dataでは、クエリを実行する前に、エクスポート中に使用するデータ接続を作成して設定する必要があります。データ接続の一部として、インテグレーションにアクセスするための認証を提供します。
- TD Consoleにログインします。
- Integrations Hub > Catalogに移動します。
- Catalog画面の右端にある検索アイコンを選択し、Amazon DSPと入力します。
- Amazon DSP Data Providerコネクタの上にマウスを置いて、Create Authenticationを選択します。
または、TD Consoleでcreate an activation(認証情報を含む)を実行します。
次のダイアログが開きます:
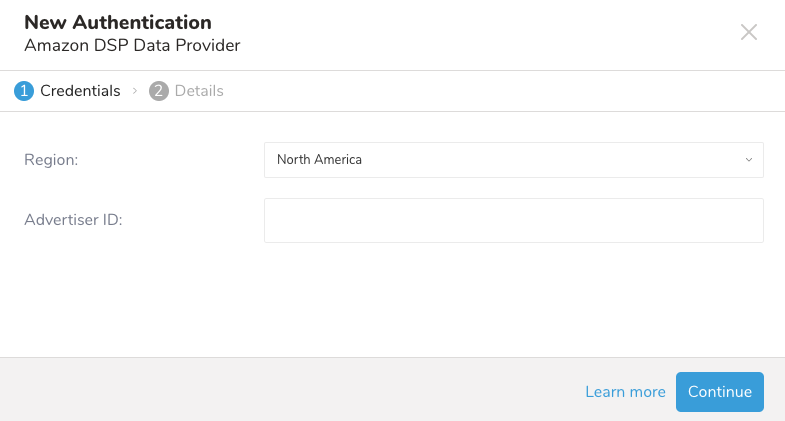
- 広告主アカウントのRegionを選択します。
- Advertiser IDを入力します。次に、Continueを選択します。
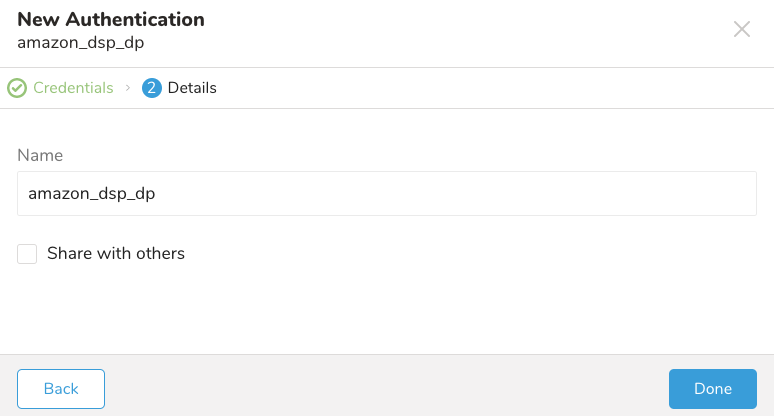
- 接続の名前を入力します。
- Doneを選択します。
- Data Workbench > Queriesに移動します。
- New Queryを選択します。
- クエリを実行して結果セットを検証します。
- Export Resultsを選択します。
- 既存の認証を選択するか、出力に使用する外部サービスの新しい認証を作成できます。次のいずれかを選択します:
Amazon DSP Data Providerデータコネクタは、次の列とデータタイプのみを理解して解釈します。エイリアス列名を次の指定された列と一致するように変更することをお勧めします:
Data Source: Audiences (以下の列のうち少なくとも1つが必要)
| Column name | Type | Required | Description |
|---|---|---|---|
| cookie | string | optional | データプロバイダーからcookie syncによってAmazonに送信されるcookie ID |
| maid | string | optional | モバイル広告識別子 |
| external_user_id | string | optional | データプロバイダーによって定義された外部ID |
Data Source: Hashed_records (以下のすべての列が必須)
| Column name | Type | Required | Description |
|---|---|---|---|
| first_name | string | required | 名 |
| last_name | string | required | 姓 |
| address | string | required | 番地 |
| phone | string | required | 電話番号 |
| city | string | required | 市 |
| postal_code | string | required | 郵便番号 |
| state | string | required | 州または県 |
| string | required | メールアドレス | |
| external_id | string | required | このレコードの外部識別子 |
結果をエクスポートするには:
- TD Consoleにログインします。
- Data Workbench > Queriesに移動します。
- データのエクスポートに使用する予定のクエリを選択します。
- Audience Datasourceの例:
SELECT
a_cookie_column AS cookie,
a_maid_column AS maid
FROM
your_table;Hashed Records Datasourceの例: すべての列が必須であることに注意してください。データがないフィールドにはダミーデータ文字列を使用できます。例: "first_name"、"last_name_column"。(空の文字列""は使用しないでください)
SELECT
first_name_column AS first_name,
last_name_column AS last_name,
address_column AS address,
phone_column AS phone,
city_column AS city,
postal_code_column AS postal_code,
state_column AS state,
email_column AS email,
external_id_column AS external_id
FROM
your_table- クエリエディタの上部にあるExport Resultsを選択します。
- Choose Integrationダイアログボックスが開きます。
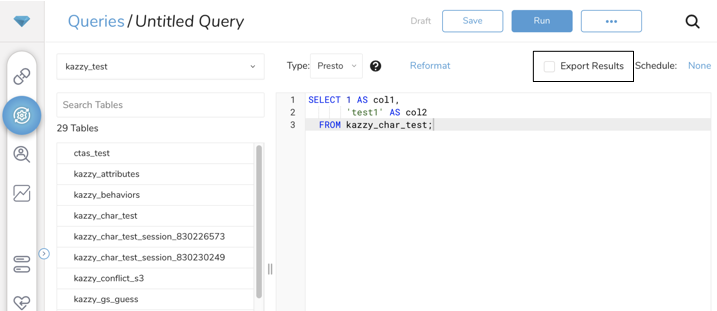
- 結果をエクスポートするために使用する接続を選択する際には、2つのオプションがあります:
- Use an Existing Integration
- Create New Integration
- 検索ボックスに接続名を入力してフィルタします。
- 接続を選択します。
- Nextを選択します。
- Audience Name、Audience Description、External Audience ID、Time to live、Operation、およびIgnore Invalid Recordsの値を入力します。
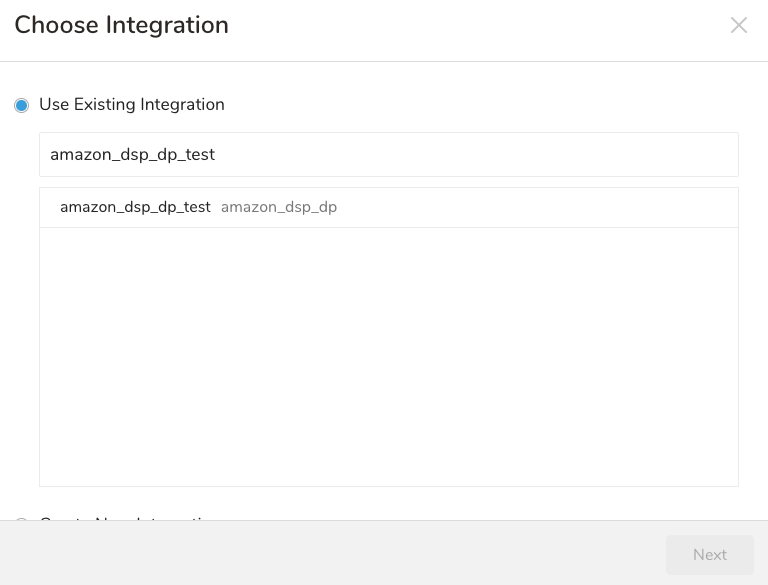
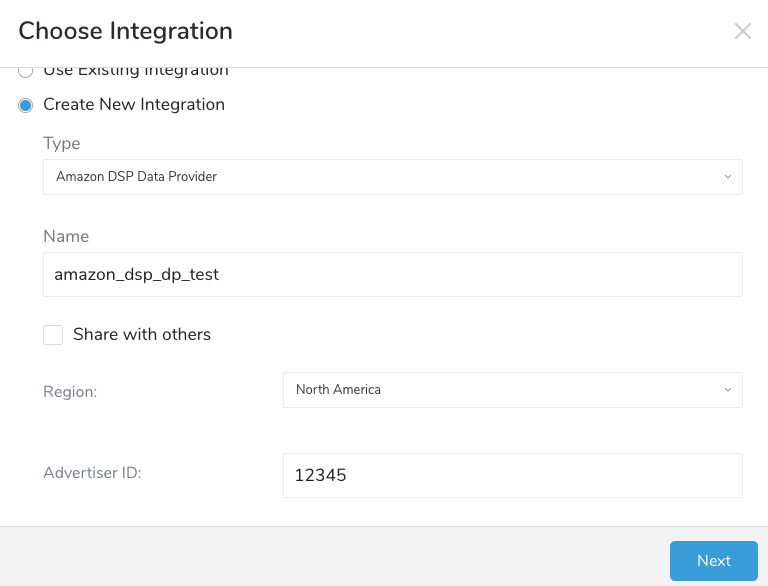
- Create New Integrationを選択します。
- 接続のNameを入力します。
- リージョンを選択します。
- Advertiser IDを入力します。
- Nextを選択します。
- Audience Name、Audience Description、External Audience ID、Time to live、Data Source Country、Operation、およびIgnore Invalid Recordsフィールドの値を入力します**。
- Doneを選択します。
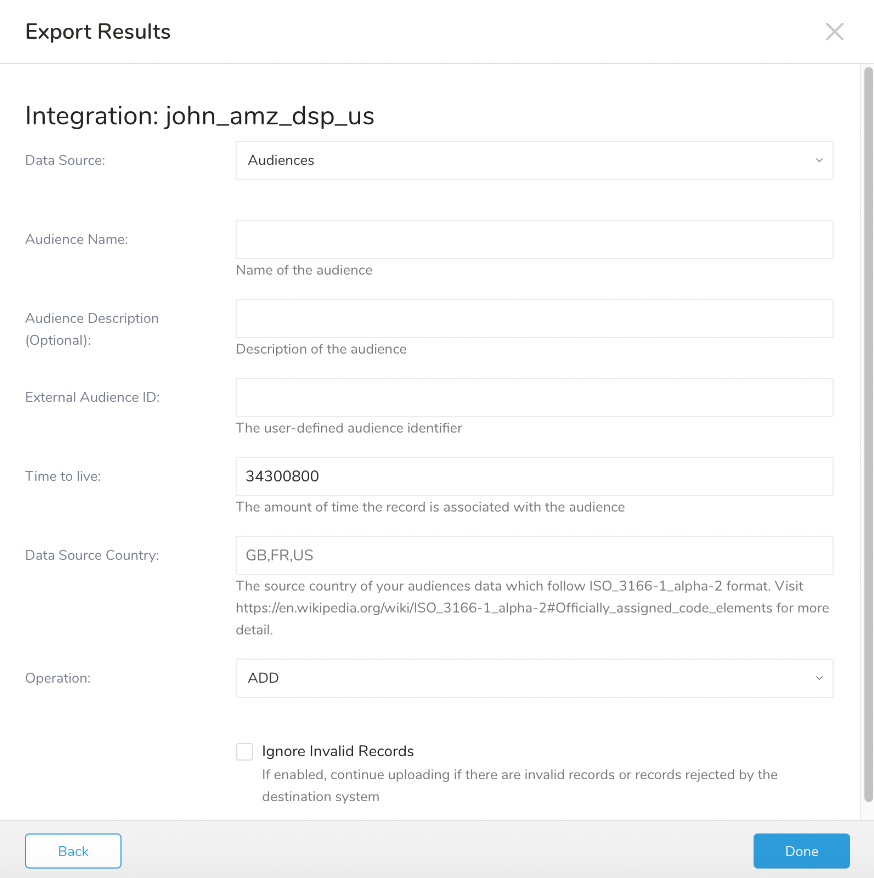
| Parameter | Description |
|---|---|
| Data Source (required) | データソースはaudiencesまたはhashed_recordsです。 |
| Audience Name (データソースがaudiencesの場合に必須) | 作成するオーディエンスの名前。 |
| Audience Description (optional) | オーディエンスの説明。 |
| External Audience ID (データソースがaudiencesの場合に必須) | オーディエンスの一意のキー。 |
| Time to live (データソースがaudiencesの場合に必須) | オーディエンスが有効である時間(秒単位)。 |
| Data Source Country (required) | オーディエンスデータが収集される国コード。例: "DE"、"JP"など。 DMA (Digital Markets Acts)はこれを要求します。2024年2月29日以降、すべてのオーディエンス作成/更新リクエストには、オーディエンスデータが収集された場所を示すフィールドを含める必要があります。 |
| Operation (データソースがaudiencesの場合に必須) | 出力データに対して実行する操作(addまたはremove)。 |
| Ignore Invalid Records | このチェックボックスが選択されている場合、時間データがAmazon DSPに送信されるときに、不正なレコードまたはエラーはスキップされ、残りのデータ行の送信が続行されます。このチェックボックスが選択されていない場合、不正なレコードまたはエラーが発生すると例外がスローされます。 |
Scheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
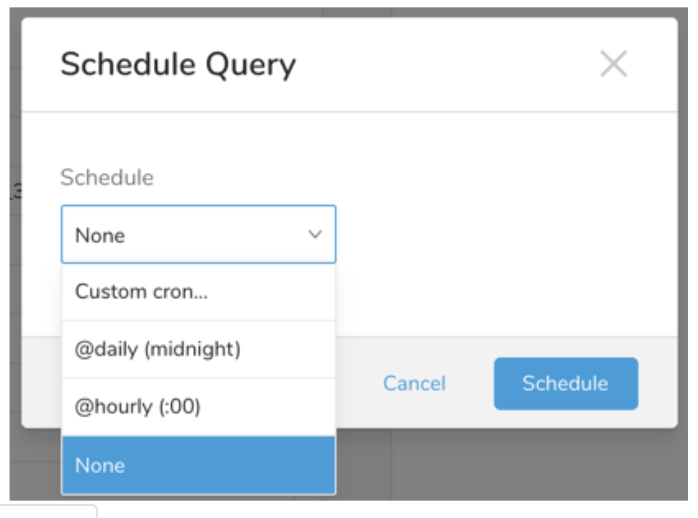
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
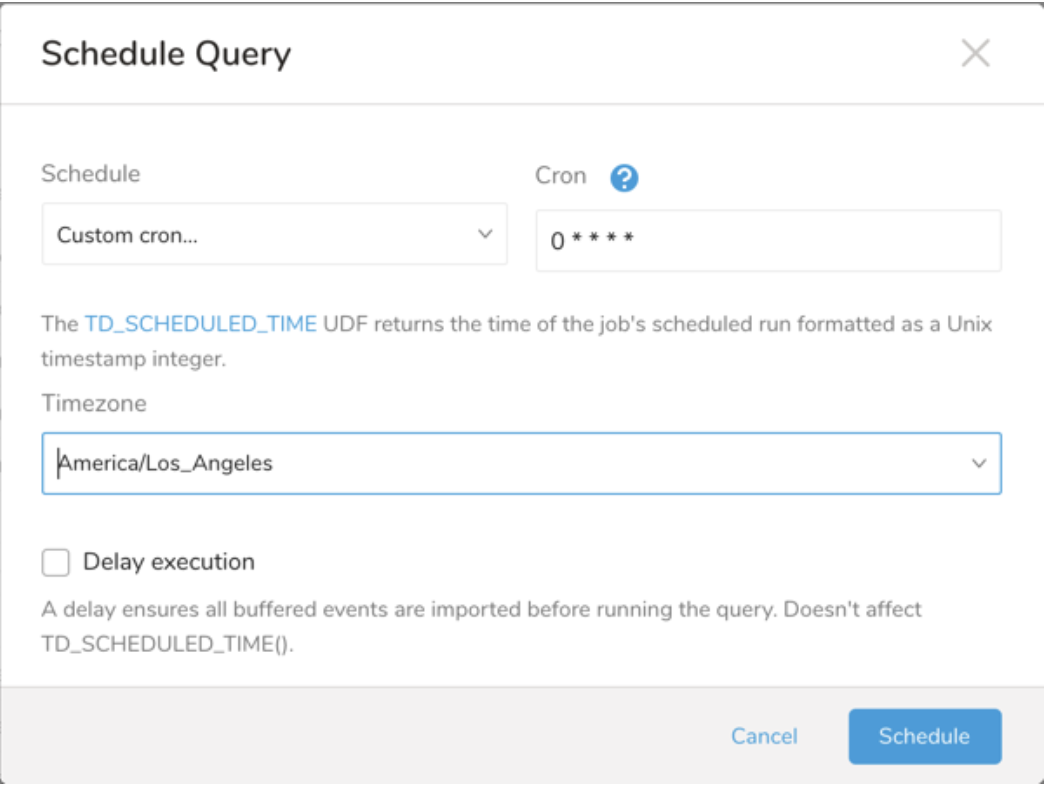
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
Audience Datasourceの例
timezone: UTC_export: td: database: sample_datasets+td-result-into-target: td>: queries/sample.sql result_connection: your_connections_name result_settings: datasource: audiences region: NA advertiser_id: 12345 audience_name: This is a test audience audience_description: This is for testing purpose external_audience_id: test_audiences time_to_live: 3600 data_source_country: GB,IN,DE operation: Add ignore_error: falseHashed Recordsの例:
timezone: UTC
_export:
td:
database: sample_datasets
+td-result-into-target:
td>: queries/sample.sql
result_connection: your_connections_name
result_settings:
datasource: hashed_records
region: NA
advertiser_id: 12345
time_to_live: 3600
ignore_error: falseWorkflow内でデータコネクタを使用する方法の詳細については、ドキュメントのWorkflowsセクションを参照してください。
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
TD Toolbelt CLIを使用してAmazon DSPに結果をエクスポートすることもできます。
td queryコマンドの--resultオプションを使用して、Amazon DSPサーバーへのエクスポートの情報を指定することをお勧めします。td queryの詳細については、TD Toolbelt Query Commandsを参照してください。
オプションの形式はJSONで、一般的な構造は次のとおりです:
{"type": "amazon_dsp_dp", "region": "NA", "advertiser_id": "12345", "audience_name": "This is a test audience", "audience_description": "This is for testing purpose", "external_audience_id": "test_audiences", "time_to_live": 3600, "data_source_country": "GB, IN, DE", "ignore_error": false}