Treasure Dataでは、td importコマンドの代わりにEmbulkの使用を推奨しています。td importコマンドで実行されるLegacy Bulkは保守されていますが、更新や機能強化は行われていません。
tdバージョン0.10.84以降では、td importコマンドを使用してデータを一括インポートできます。
- Toolbeltを含む、Treasure Dataの基本的な知識
- Java runtime(6以降)
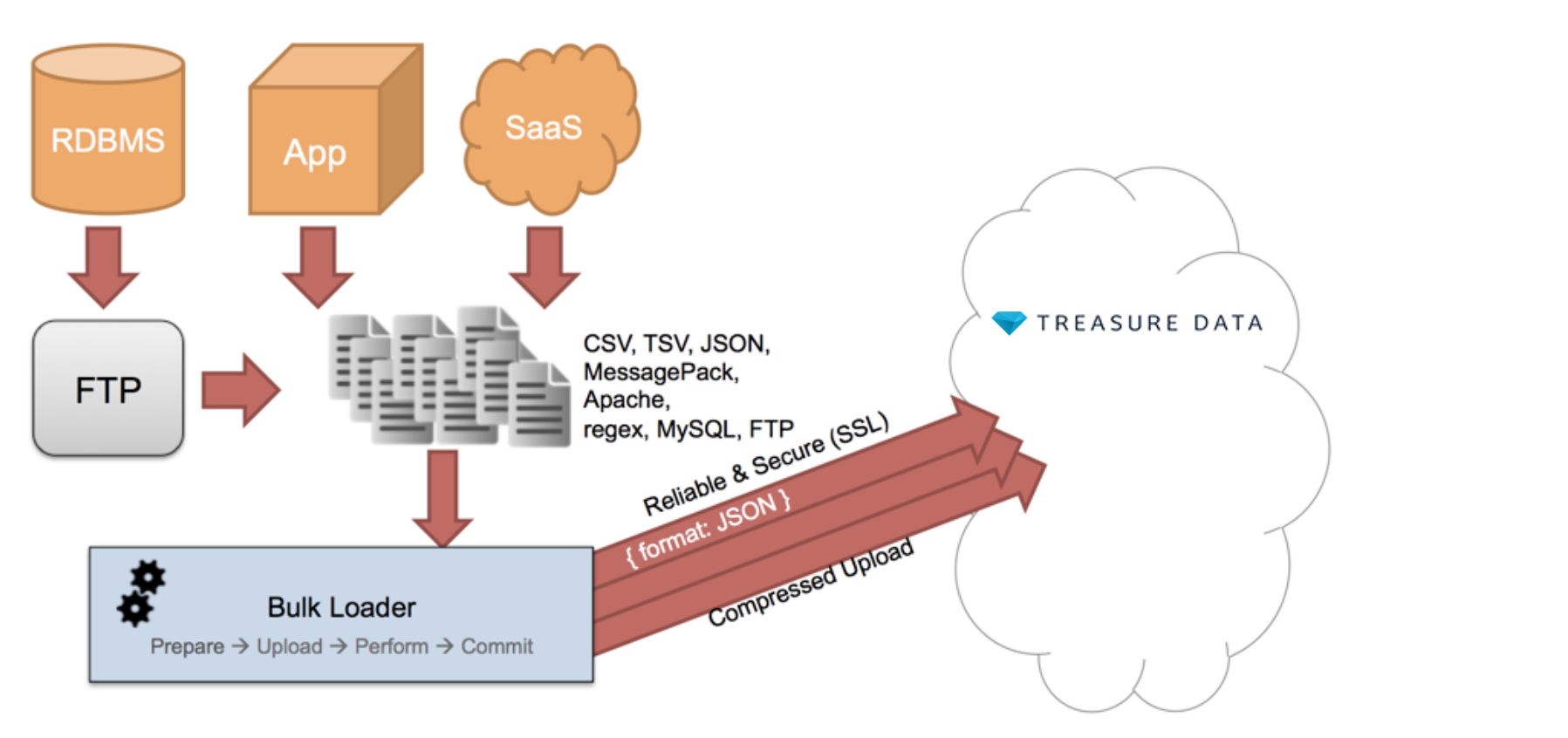
Treasure Dataはクラウドサービスであるため、データはインターネットネットワーク接続を介して転送する必要があります。データサイズが大きくなると(100MB以上)、これが難しくなることがあります。いくつかのケースを考えてみましょう。
- ネットワークが不安定になると、データ転送の途中でインポートが失敗する可能性があります。中断した場所から再開する簡単な方法はなく、最初からアップロードをやり直す必要があります。
- 企業によっては、単一のストリームで大量のデータを転送する際に帯域幅の制限がある場合があります。また、TCP/IPプロトコルの制限により、アプリケーションがネットワーク接続を飽和させることが困難になります。
これらの問題を克服するために、Bulk Import機能を設計しました。大きなデータセットを小さなチャンクに分割し、それらを並列にアップロードできるようになりました。特定のチャンクのアップロードが失敗した場合は、そのチャンクのみのアップロードを再開できます。この並列処理により、全体的なアップロード速度が向上します。
Bulk Importはパフォーマンスと信頼性を実現するための複雑な方法であるため、目的を達成するためにこれらのショートカットを使用できます。
- JSONファイルからのLegacy Bulk Import
- Amazon S3からのLegacy Bulk Import
- MySQLからのLegacy Bulk Import
- MongoDBからのLegacy Bulk Import
Bulk Importの内部構造やヒントとコツを理解するには、以下のドキュメントを参照してください。