Mailchimp Import Integrationの詳細。
Treasure Dataに保存されたデータからMailchimpリストを作成できます。使用例には以下が含まれます:
- セグメンテーションによるパーソナライゼーション: Webサイトやモバイルアプリからユーザーの行動を取得し、すべてのユーザーイベントをTreasure Dataに収集します。その後、SQLでパーソナライゼーションロジックを記述し、セグメント化されたメーリングリストをMailChimpにエクスポートしてターゲットキャンペーンを実施します。
- 顧客維持: SaaSやサブスクリプションeコマースビジネスでは、顧客維持が成長を促進します。Treasure Dataに保存されたユーザーイベントで「リスクのある」ユーザーを特定し、MailChimpにプッシュします。リスクのあるユーザーにターゲットプロモーションを送信して再エンゲージメントを図ります。
Mailchimpへのエクスポートのサンプルワークフローについては、Treasure Boxesをご覧ください。
以下のトピックに進んでください:
- TD Toolbeltを含むTreasure Dataの基本知識
- MailChimpアカウント
- Mailchimpへのアクセスが承認されたTreasure Dataアカウント
TD Consoleを使用して接続を設定できます。新しい接続を作成するか、すでにMailchimpデータコネクタ(入力転送または認証)を設定している場合は、データ接続でのエクスポート結果の設定にスキップできます。
Integrations Hub > Catalogに移動して検索します。Mailchimpタイルを見つけて選択します。
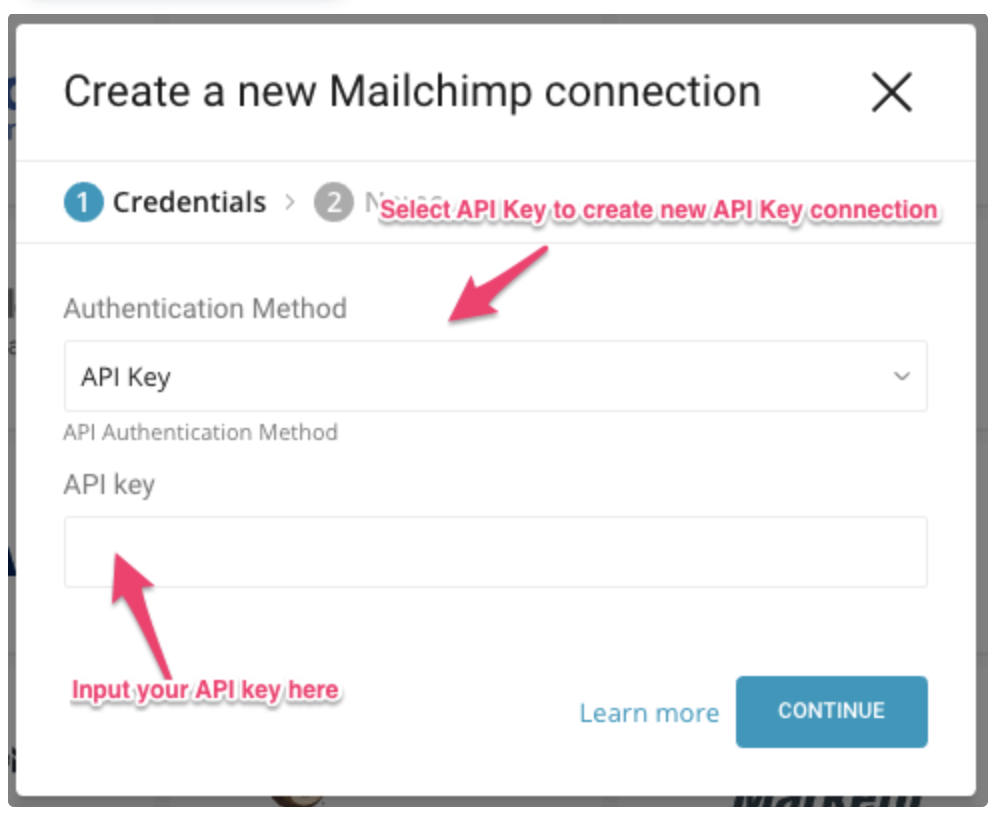
必要な認証情報を入力するダイアログが開きます。認証方法を指定します。
Treasure DataをMailChimpで認証する方法は、データコネクタを有効にするために実行する手順に影響します。以下を使用して認証することを選択できます:
- API
- OAuth
MailChimp APIキーと認証情報を指定して、Treasure Dataアクセスを承認できます。APIキーは、Mailchimpアカウントへの完全なアクセス権を付与します。
OAuth方式は、JPおよびIDCFのお客様にはサポートされていません。
ドロップダウンからMailChimpの既存のOAuth接続を選択するか、OAuth connectionの下のリンクを選択して新しい接続を作成できます。
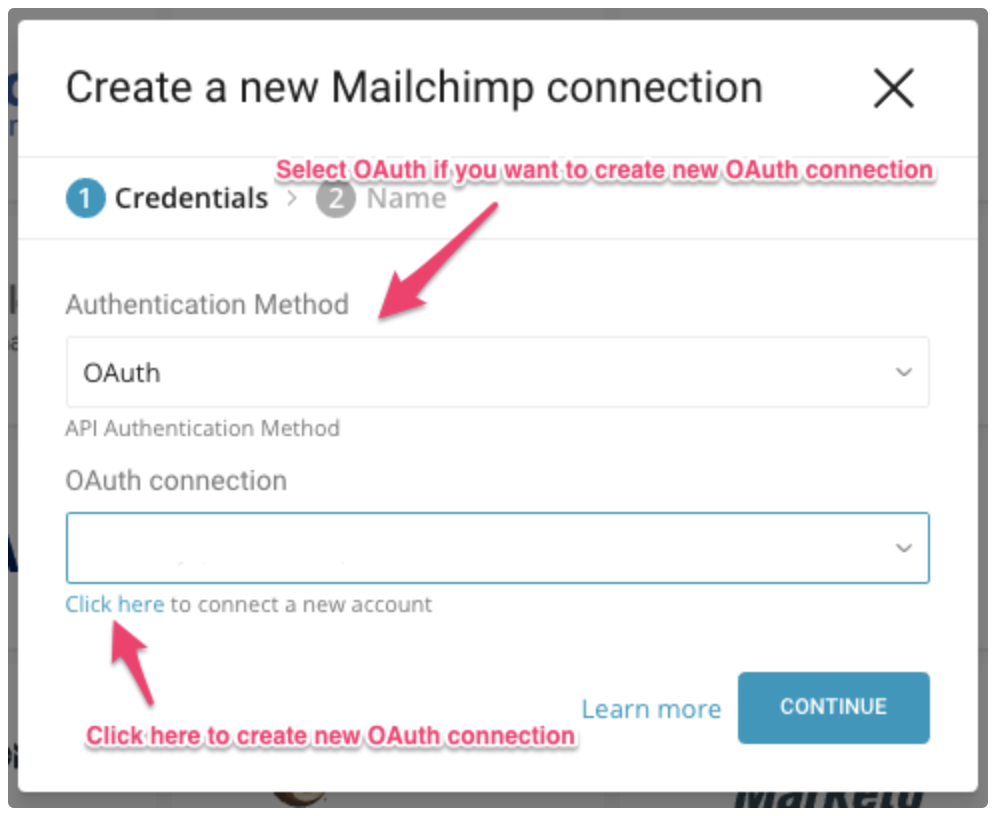
Click here to connect a new accountを選択すると、ポップアップウィンドウでMailChimpアカウントにサインインする必要があります
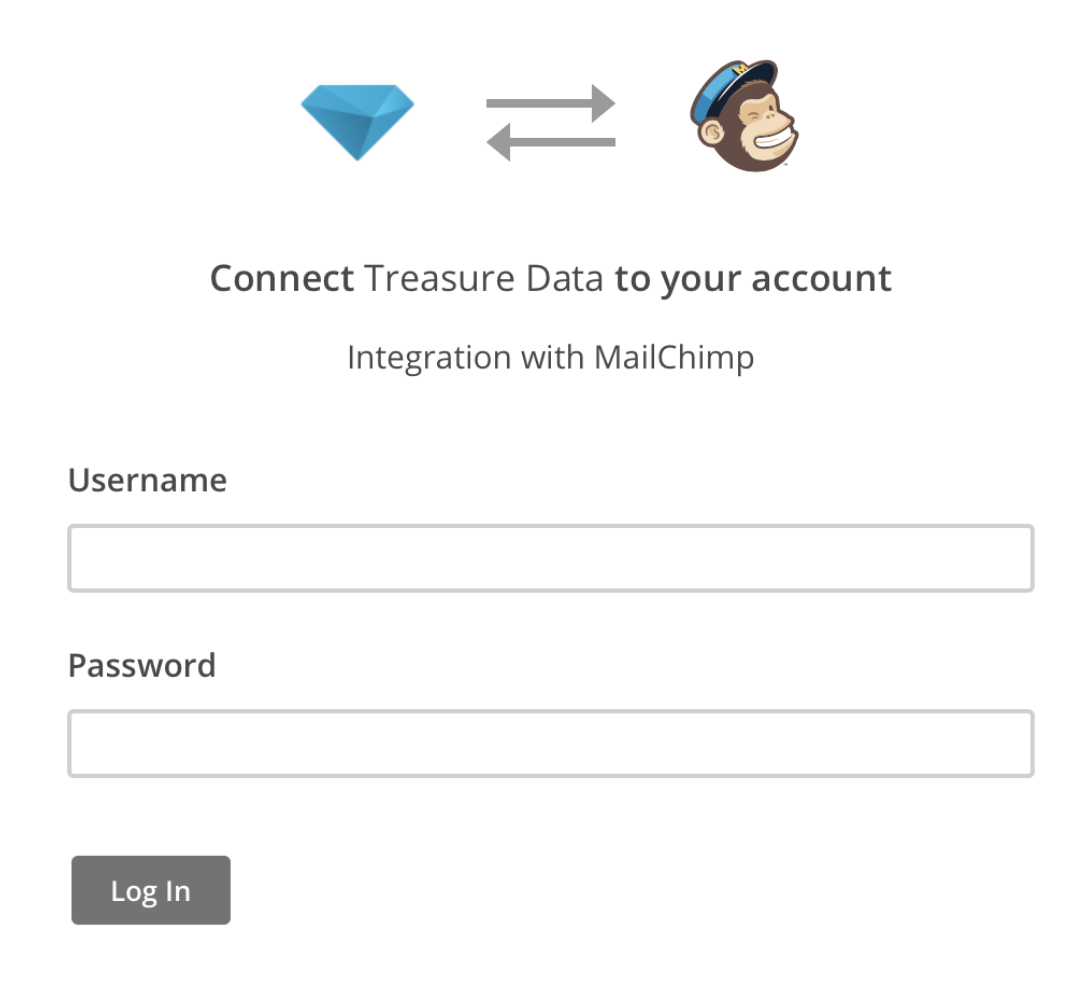
MailChimpにサインインすることで、認証を行います。Mailchimpにサインインするアクションにより、OAuth認証が生成されます。
Treasure Dataの接続ページにリダイレクトされます。最初のステップ(新しい接続の作成)を繰り返し、新しいOAuth接続を選択してから、接続の作成を完了します。
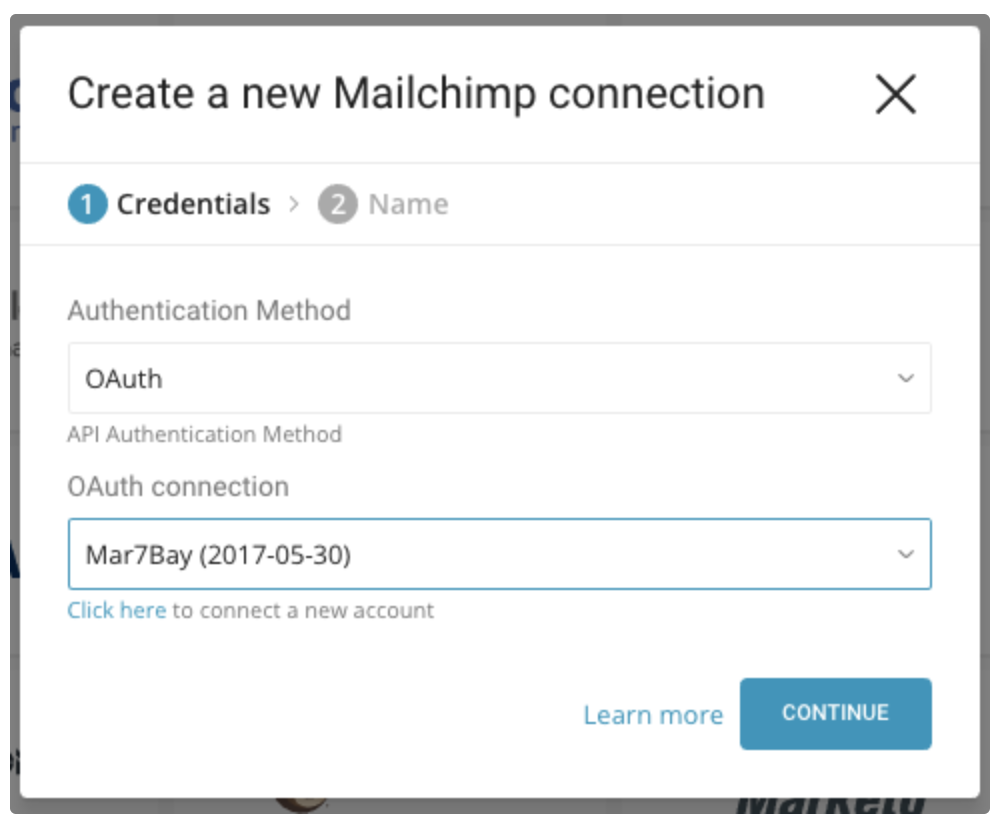
これで、次のステップでデータ出力の設定を完了するために使用する認証済みコネクタができました。
Continueを選択します。コネクタの名前を入力します。
エクスポートしてMailchimpリストに配置するデータを取得するクエリを作成するか、既存のクエリを使用します。クエリでは、Treasure Data Mailchimpデータコネクタを指定します。
TD Consoleに移動し、クエリエディタに移動します。データをエクスポートするために使用する予定のクエリにアクセスするか、クエリを記述します。Output resultsを選択します。
次の画像で簡単なサンプルクエリを確認できます:
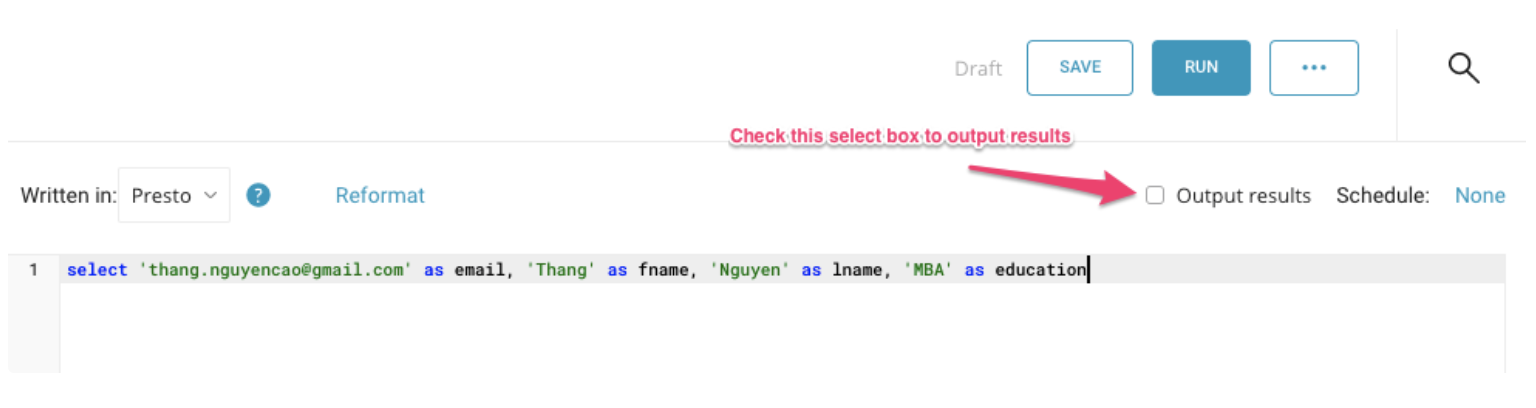
Mailchimp用のクエリの記述の詳細については、付録をご覧ください。
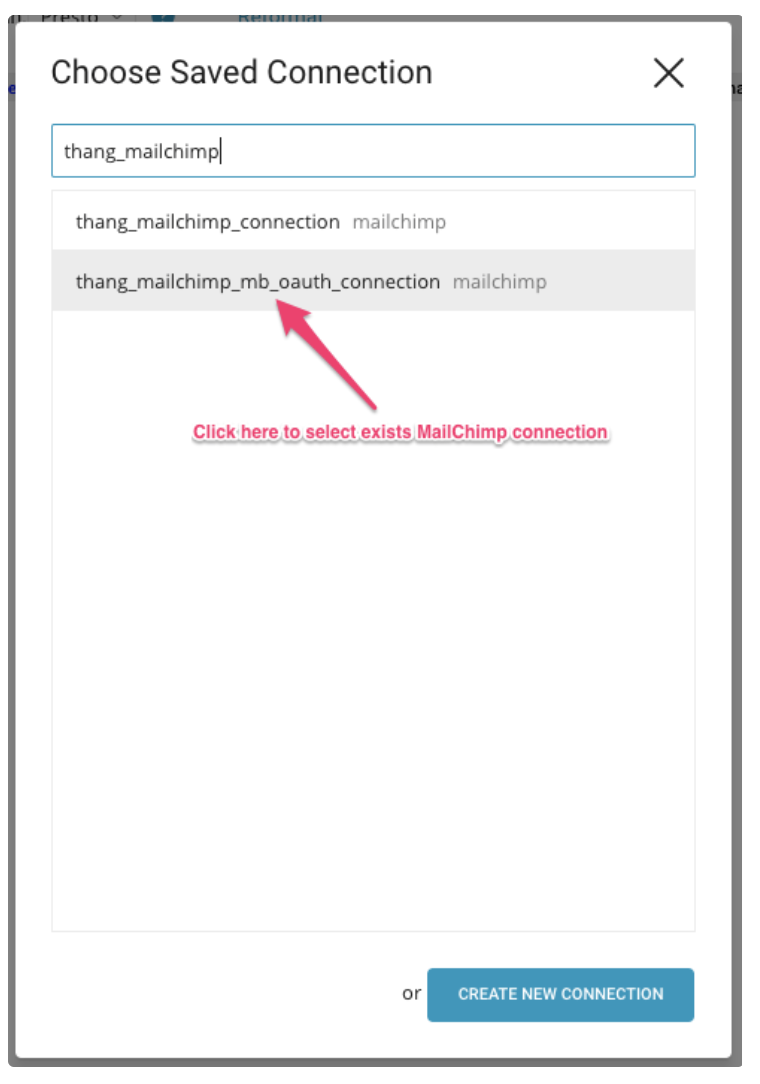
Output Resultsチェックボックスを選択してSaveを選択すると、Choose Saved Connectionダイアログが開きます。
Choose Saved Connectionダイアログが開きます。検索ボックスに接続名を入力してフィルタリングし、接続を選択します。
Create New Connectionを選択します。
以下はサンプル設定です。
この例では、デフォルトの列名が「last_name」と「first_name」で上書きされます。また、Mailchimpの「グループ詳細の列名」を値として指定できます。次の例では、列名の値は「region, age」です。Mailchimpグループの詳細については、付録:「Mailchimpグループカテゴリの詳細」を参照してください。
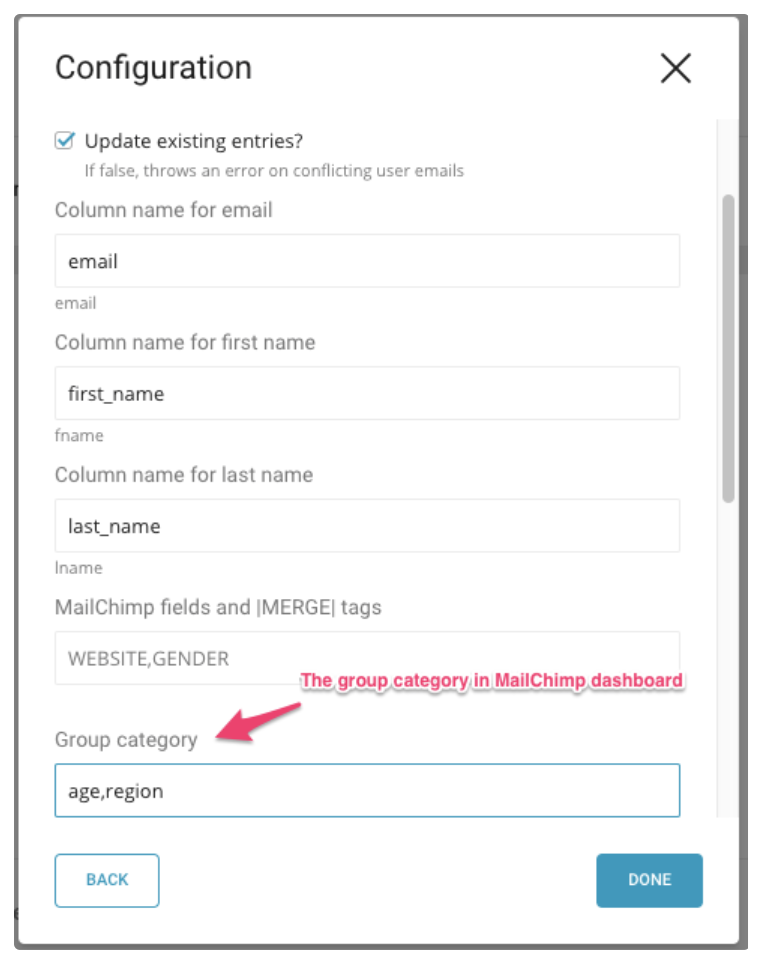
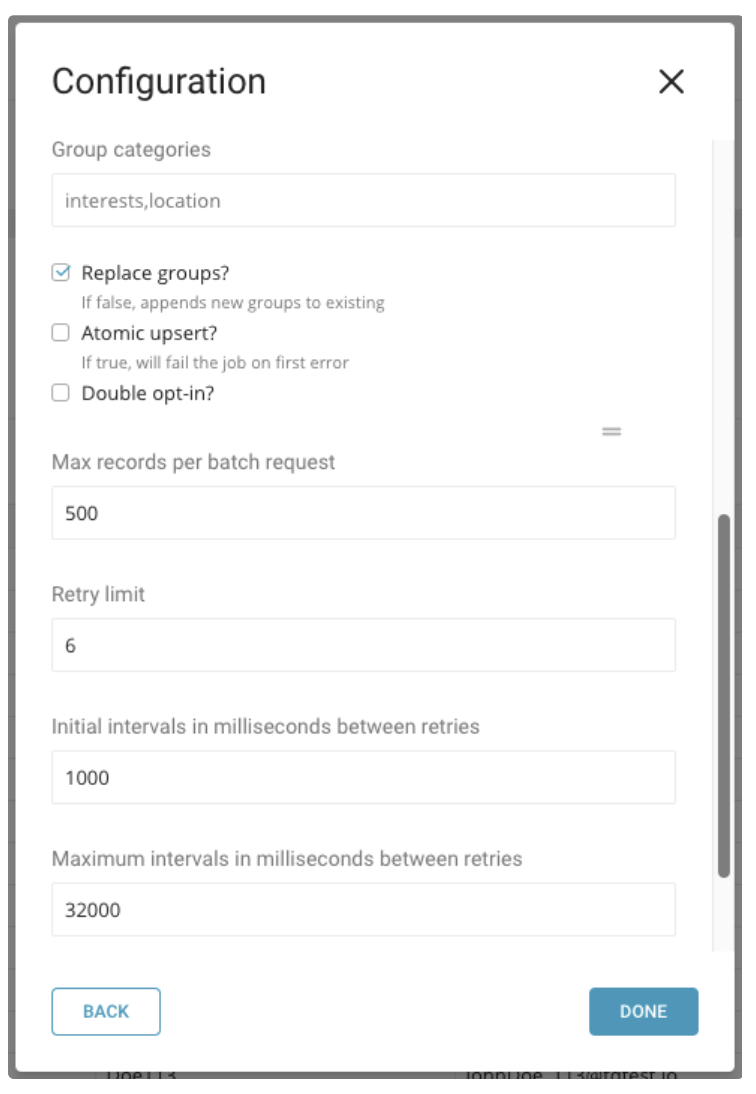
パラメータを指定します。
| パラメータ | 説明 | デフォルト値 |
|---|---|---|
| MailChimp list ID | これは、Treasure Dataのクエリ結果を入力したいMailchimpリストのIDです。検索方法はこちら | |
| Update existing entries? | オンに切り替えると、既存のエントリがメールアドレスをキーとして更新されます。そうでない場合、新しいエントリがMailChimpリストに追加されます | Yes |
| Column name for email | この列の値は、ターゲットMailChimpリストのemailフィールドの入力に使用されます | email |
| Column name for fname | この列の値は、ターゲットMailChimpリストのfnameフィールドの入力に使用されます | fname |
| Column name for lname | この列の値は、ターゲットMailChimpリストのlnameフィールドの入力に使用されます | lname |
| Additional MailChimp fields and MERGE tags | 追加のマージフィールドの値は、ターゲットMailChimpリストのグループの入力に使用されます。複数のフィールドは「,」で区切って設定できます。例: WEBSITE,GENDER | |
| Group categories | インタレストカテゴリの値は、ターゲットMailChimpリストのグループの入力に使用されます。複数のグループは「,」で区切って設定できます。例: interests,location | |
| Replace group? | オンに切り替えると、各サブスクライバのグループの値が置き換えられます。そうでない場合、新しい値がサブスクライバのインタレストグループに追加されます。 | Yes |
| Double opt-in? | オンに切り替えると、各サブスクライバは確認メールを受信し、サブスクリプションを確認する必要があります。そうでない場合、各サブスクライバは自動的にサブスクライブされます | No |
| Atomic Upsert? | UPDATEとINSERT操作の複合です。ターゲット行が存在しないためにUPDATEが失敗した場合、INSERTが自動的に実行されます。'yes'(true)の場合、すべてのレコードがMailChimp内で正常に処理されると、クエリ結果はジョブのステータスを'success'として返します。(エラーは、ターゲット行が存在せず、INSERTが自動的に実行されたが失敗したことを示します。) | No |
| The timeout expires in Milliseconds | MailChimp APIからの応答を待機する時間。この値は、ネットワークの問題が発生した場合に役立ちます | 60000 |
| Max records per request | MailChimp APIからのバッチリクエストあたりの最大レコード数です。MailChimp APIでは、バッチリクエストあたり最大500レコードを使用できます。この値は、大量のデータをアップロードする場合に便利です。 | 500 |
Scheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
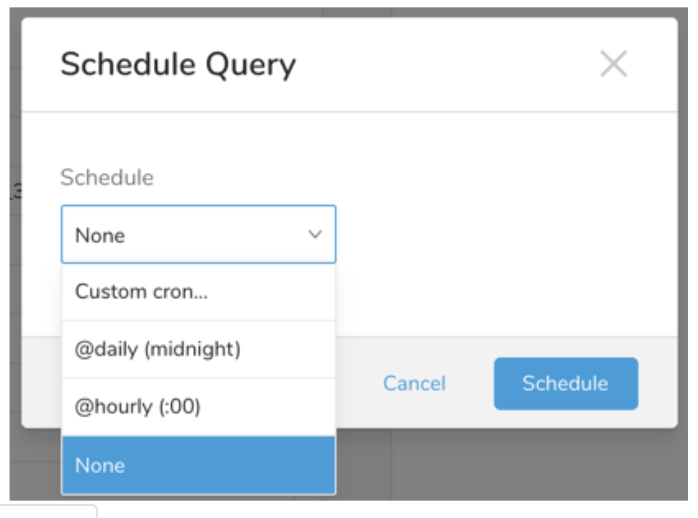
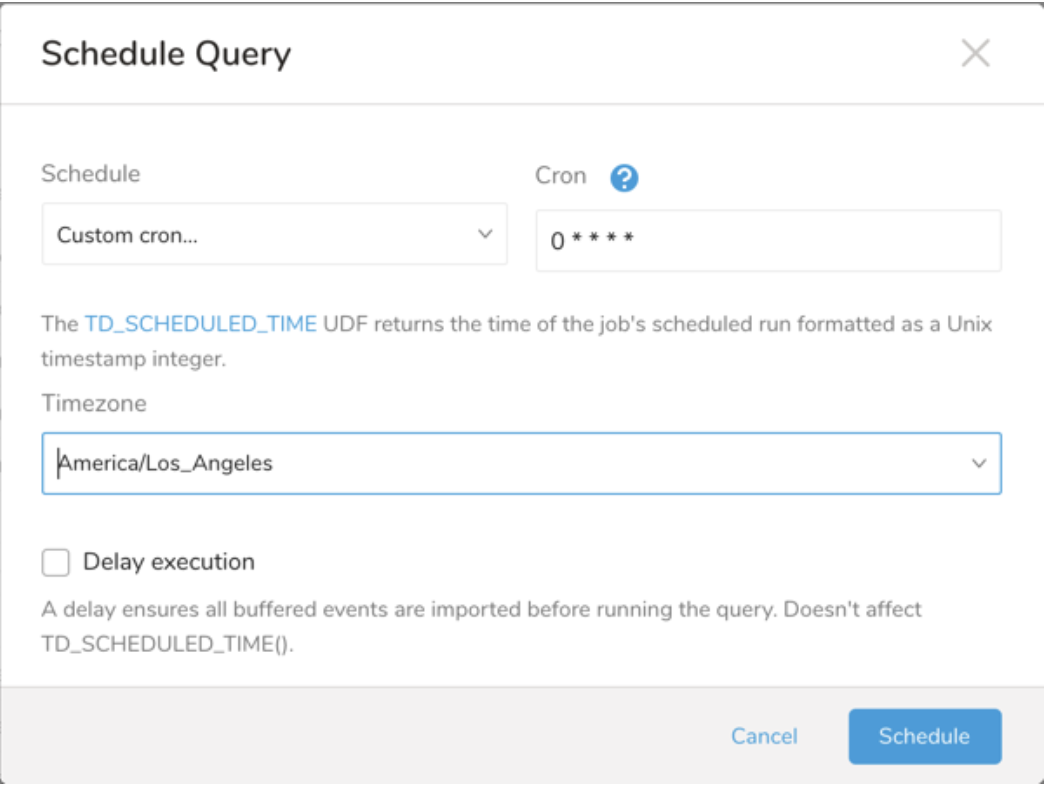
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
クエリに名前を付けて保存して実行するか、単にクエリを実行します。クエリが正常に完了すると、クエリ結果は指定された宛先に自動的にエクスポートされます。
設定エラーにより継続的に失敗するスケジュールジョブは、複数回通知された後、システム側で無効化される場合があります。
(オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
Treasure Workflowで作業する場合、このデータコネクターを使用してデータを出力するように指定できます。
timezone: UTC
_export:
td:
database: sample_datasets
+td-result-into-target:
td>: queries/sample.sql
result_connection: your_connections_name
result_settings:
list_id: your_list_id
email_column: email
fname_column: first_name
lname_column: last_name
update_existing: true
grouping_columns: age, regionresult_settingsパラメータを指定します。
| パラメータ | 説明 | デフォルト値 |
|---|---|---|
| list_id | Treasure Dataのクエリ結果を入力するMailchimpリストのIDです。IDの確認方法はこちら | |
| update_existing | オンに設定すると、既存のエントリがメールアドレスをキーとして更新されます。オフの場合、新しいエントリがMailChimpリストに追加されます | false |
| email_column | この列の値は、ターゲットMailChimpリストのemailフィールドに入力されます | email |
| fname_column | この列の値は、ターゲットMailChimpリストのfnameフィールドに入力されます | fname |
| lname_column | この列の値は、ターゲットMailChimpリストのlnameフィールドに入力されます | lname |
| merge_fields | 追加のマージフィールドの値は、ターゲットMailChimpリスト内のグループに入力されます。複数のフィールドは「,」で区切って設定できます。例: WEBSITE,GENDER | |
| grouping_columns | インタレストカテゴリの値は、ターゲットMailChimpリスト内のグループに入力されます。複数のグループは「,」で区切って設定できます。例: interests,location | |
| replace_interests | オンに設定すると、各購読者のグループの値が置き換えられます。オフの場合、新しい値が購読者のインタレストグループに追加されます。 | true |
| double_optin | オンに設定すると、各購読者は確認メールを受信し、購読を確認する必要があります。オフの場合、各購読者は自動的に購読されます | false |
| atomic_upsert | UPDATEとINSERT操作の複合です。ターゲット行が存在しないためにUPDATEが失敗した場合、INSERTが自動的に実行されます。'yes'(true)の場合、クエリ結果は、すべてのレコードがMailChimp内で正常に処理されたときにジョブのステータスを'success'として返します。(エラーは、ターゲット行が存在せず、INSERTが自動的に実行されたが失敗したことを示します。) | false |
| sleep_between_requests_millis | MailChimp APIからの応答を待つ時間です。この値はネットワークの問題がある場合に便利です | 30000 |
| max_records_per_request | MailChimp APIからのバッチリクエストあたりの最大レコード数です。MailChimp APIでは、バッチリクエストあたり最大500レコードを使用できます。この値は、大量のデータをアップロードする場合に便利です。 | 500 |
ワークフローでデータコネクターを使用してデータをエクスポートする方法の詳細については、パラメータを使用したデータのエクスポートをご覧ください。
以下は、クエリ結果がMailchimpにエクスポートされる前のMailchimpリストの例です:
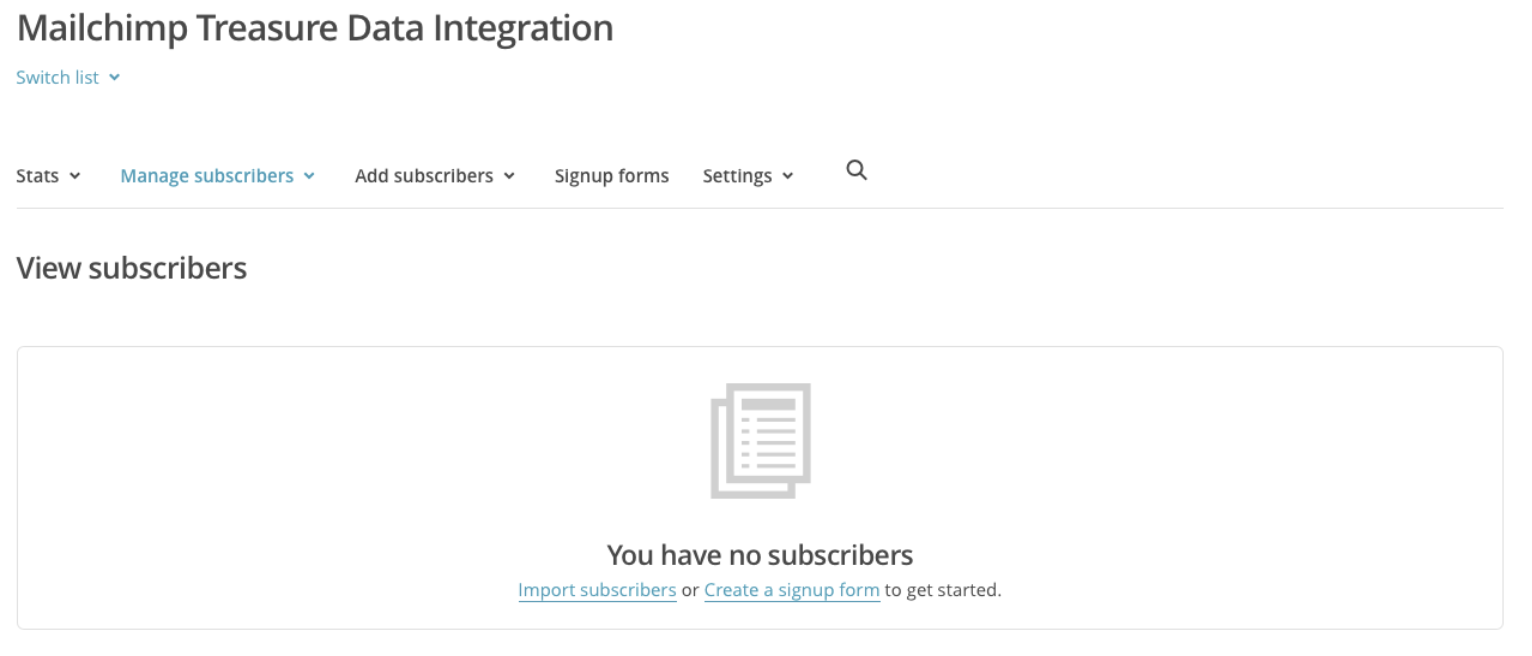
上記のリストは、2つのMailChimpグループ(AgeとRegion)で構成されています。これらには次のカテゴリがあります:
- 0-20
- 21-30
- 31-40
- 41 and above
- Americas
- Asia
- EMEA
Treasure DataのQueryページに戻り、MailChimpを結果エクスポートとして次のクエリを記述して実行します:
SELECT email, first_name, last_name, region, age FROM (
VALUES ('k@gmail.com', 'K', 'T', 'Asia', '41 and above'),
('r@gmail.com', 'R', 'P', 'Americas', '21-30'),
('m@gmail.com', 'M', 'C', 'EMEA', '41 and above')
) tbl (email, first_name, last_name, region, age)上記のクエリは、この機能をテストするためにソーステーブルを必要としませんが、それでもデータベースを選択する必要があるため、「sample_datasets」または他の任意のテーブルを選択してください。また、SQLダイアレクトとしてTrinoが選択されていることを確認してください。
クエリは数秒で完了します。その後、Mailchimpのリストを確認してください:
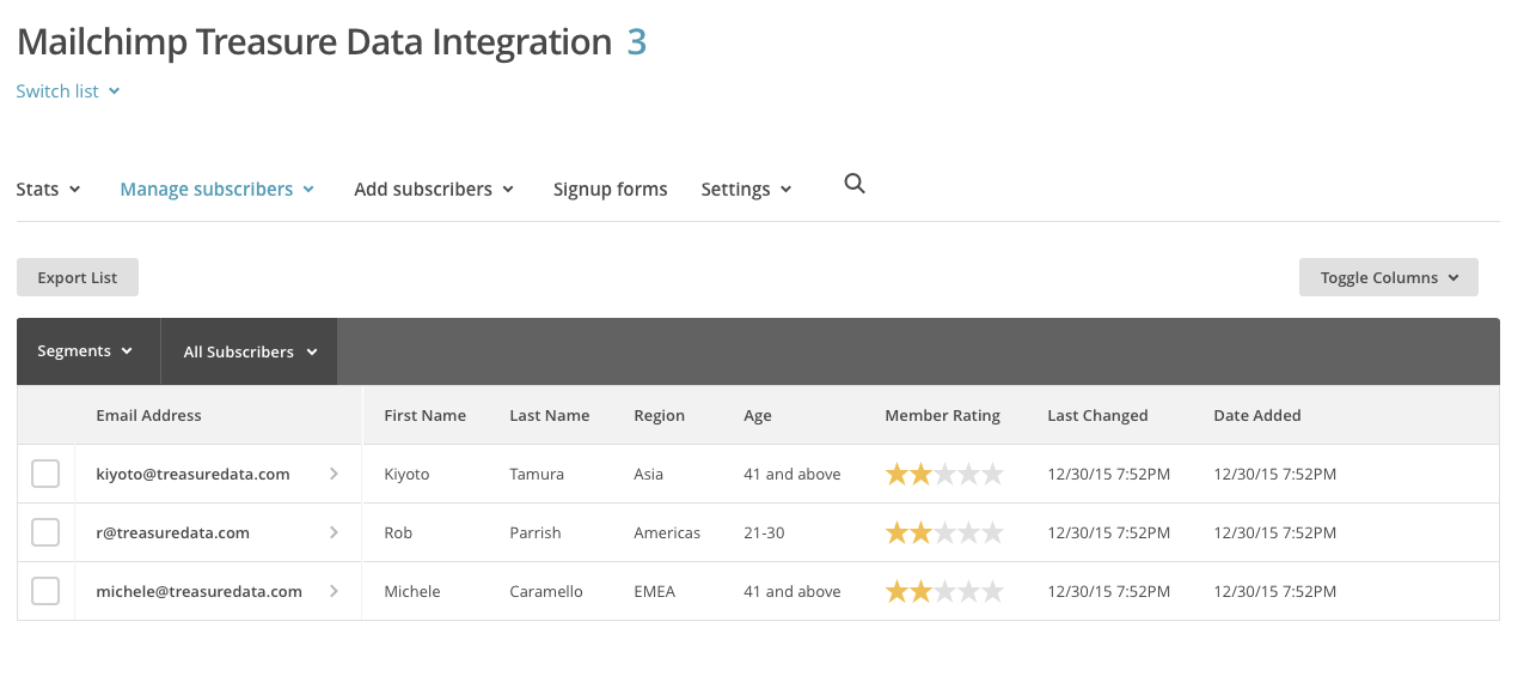
タイプaddressを使用しているMERGEフィールドがある場合は、値をJSON型に入れる必要があります。以下は、MERGEフィールドのタイプaddressでデータをエクスポートするMailChimpを使用したクエリです:
SELECT
'y@gmail.com' as email,
'y' as fname, 'L' as lname,
CAST(MAP(ARRAY['addr1', 'city', 'state', 'zip', 'country'], ARRAY['1234', 'mountain view', 'CA', '95869', 'US']) as JSON) as address,
'US' as locationMailchimpでは、ダッシュボードからリストにアクセスし、グループオプションを指定できます。
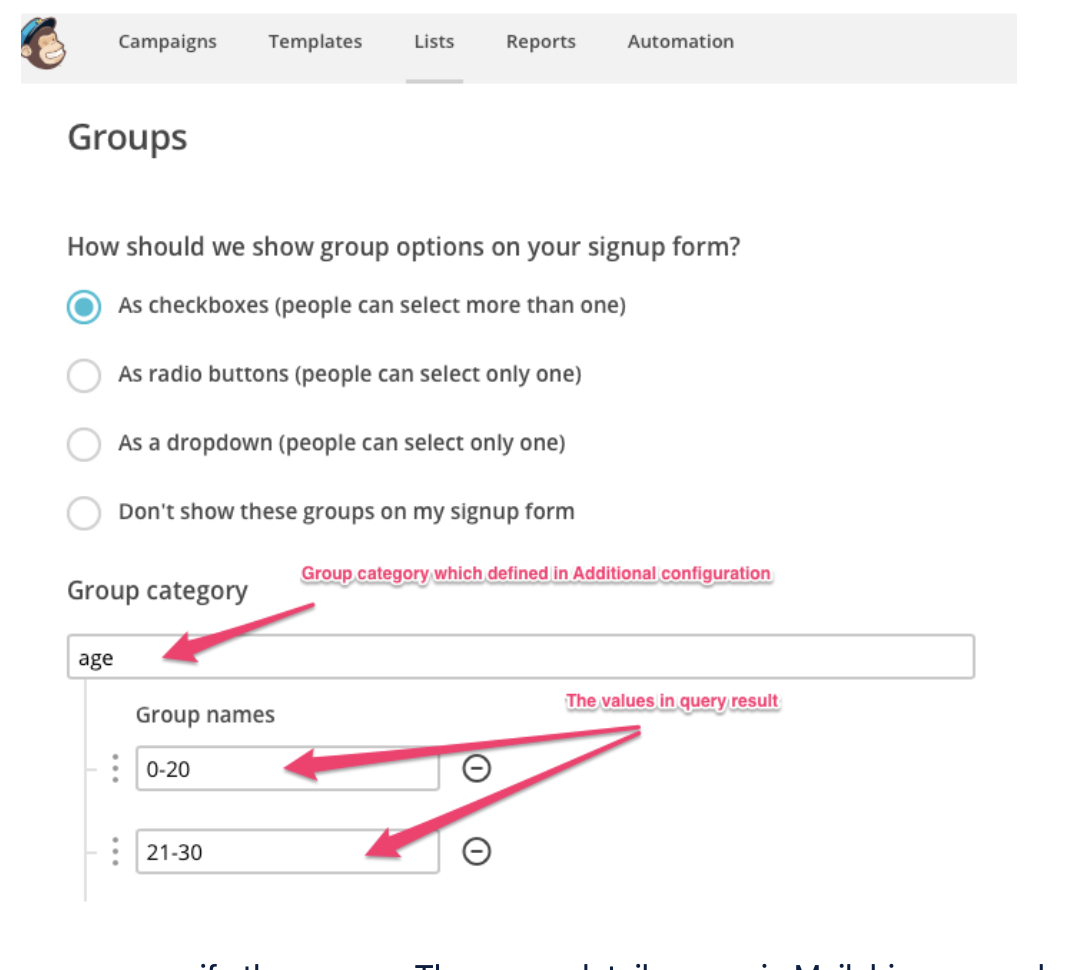
Treasure Dataでは、グループを指定できます。Mailchimpのグループ詳細名は、クエリの列名です。