Lookerは、ビジネスインテリジェンスに対する全く新しいアプローチを提供します。LookerでSQLクエリを使用して、Treasure Dataに保存されたデータにアクセスできます。そのデータを使用してダッシュボードを作成し、Lookerでデータモデルを管理できます。
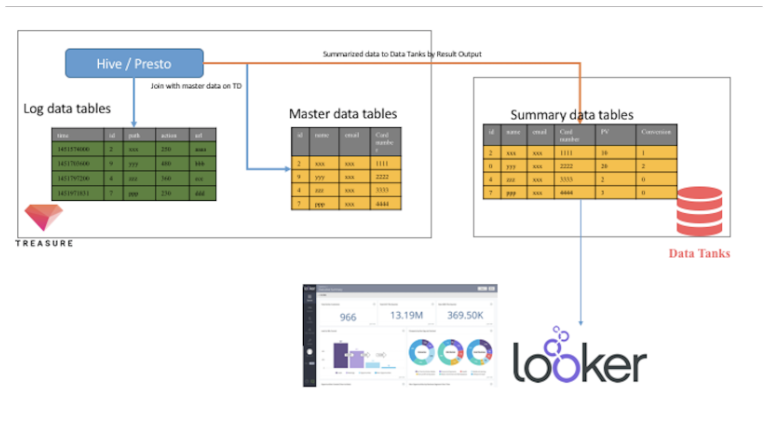
Treasure Dataを、異なるイベントデータソース(およびいくつかの低頻度で更新されるディメンション)が集約および処理され、より小さくクリーンなデータパッケージが作成されるイベントデータレイクとして考えてください。これらのデータパッケージは、さらなる処理、分析、または可視化に使用されます。
イベントデータレイクのサイズと範囲を考えると、スキーマの柔軟性を保ちながら、何兆ものデータポイントに対して高度に並行性のある対話的アクセスを提供することは、技術的に不可能に思えます(少なくとも、コスト面を考慮すると)。しかし、レイクショアデータマートと呼ばれる設計パターンを使用することで、この課題を回避できます。
データパイプラインが分析にどのように機能するかについての優れたメンタルモデルを提供するため、「水としてのデータ」の比喩を続けます。
Treasure Dataは、便利でアクセスしやすいメトリックストアを提供し、1つ以上の個別のデータマートを管理する負担なしに、Treasure DataからLookerプラットフォームを駆動できるData Tanksを提供しています。
Data Tanksはアドオン機能です。Looker連携の使用を開始する際は、support@treasuredata.comまでご連絡ください。
Data Tanksの使用方法の詳細をご覧ください。
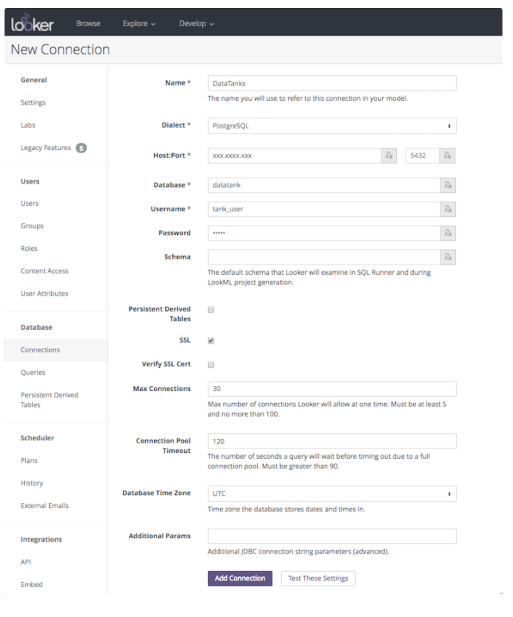
Lookerアカウントに移動します。Admin -> Connections -> "New Connection"を選択します。
次に、以下の手順を完了します:
- コネクタの名前を入力:任意
- dialectを選択:PostgreSQL
- Data Tanksのホストとポートを入力:xxx.xxx.xxx.xxx:5439
- データベース名を入力:datatank
- ユーザー名を入力:tank_user
- パスワードを入力:あなたのパスワード
- SSLを有効化:チェック済み
- 最大接続数を入力:30
各パラメータの詳細については、Lookerを参照してください。
Lookerの魔法を解き放つために、データエキスパートは「LookML」と呼ばれる軽量なモデリング言語でデータを記述します。LookMLは、組織内の全員が裏側の詳細を理解することなくレポートを作成できるように、データのクエリ方法をLookerに伝えます。LookMLの記述を始める方法については、Lookerドキュメントを参照してください。