Treasure Dataでは、組織のZendeskアカウントから直接データをインポートできます。
- Treasure Dataの基本的な知識
- Zendeskアカウント
- Chatデータを取得するためのZendesk Zopimアカウント
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
TD Consoleを開きます。
Integrations Hub > Catalogに移動します。
Zendeskを検索して選択します。
Createをクリックします。認証された接続を作成します。次のダイアログが開きます。
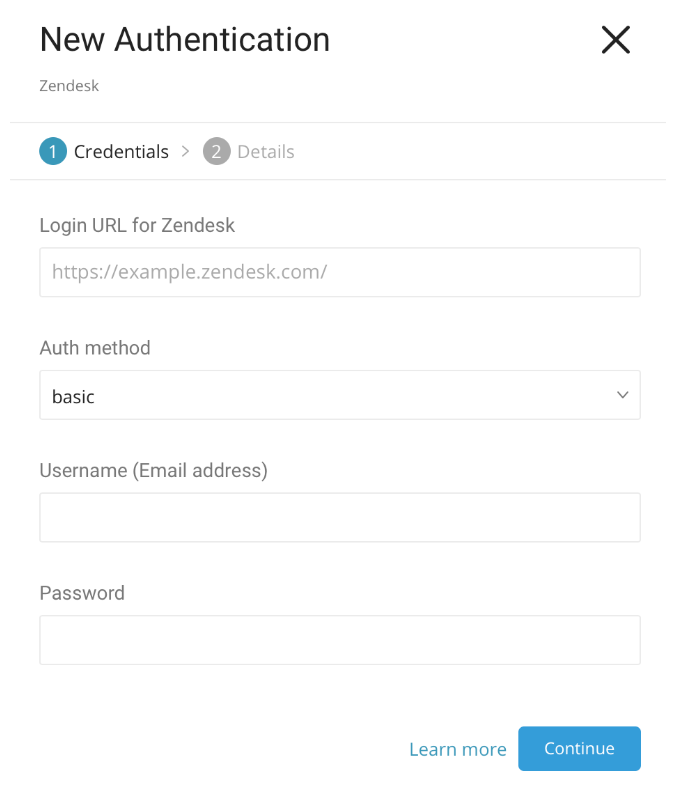
Auth methodには3つのオプションがあります:basic、token、oauth。
- Chatデータをインポートするには、ZendeskのLogin Urlに次のURLを入力します:https://www.zopim.com。ChatではToken認証はサポートされていません。
すべての必須フィールドを入力し、Continueをクリックします。
新しいZendesk接続に名前を付けます。Doneをクリックします。
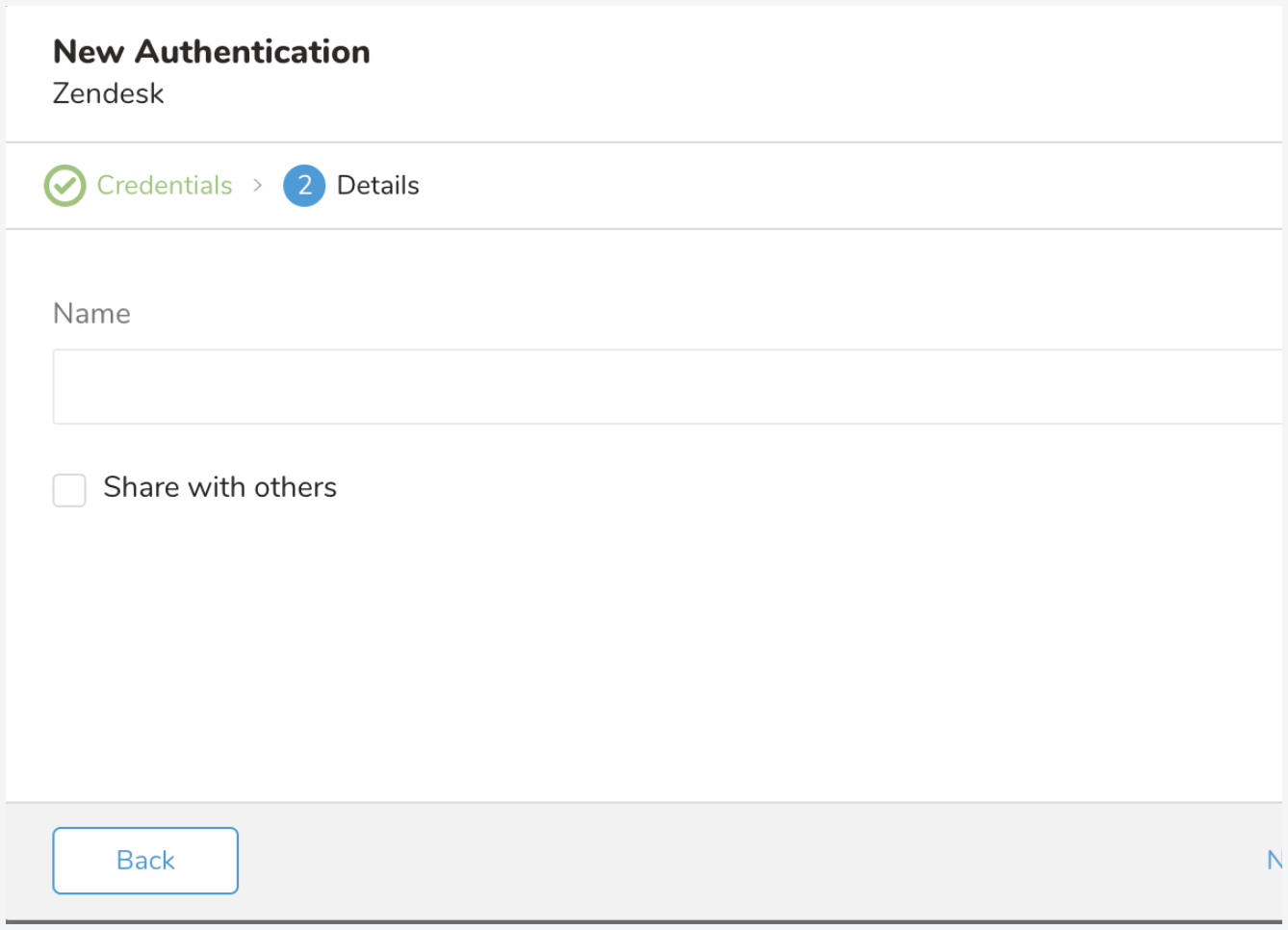
認証された接続を作成すると、自動的にAuthenticationsタブに移動します。
作成した接続を検索し、New Sourceをクリックします。
適切なフィールドを編集します。
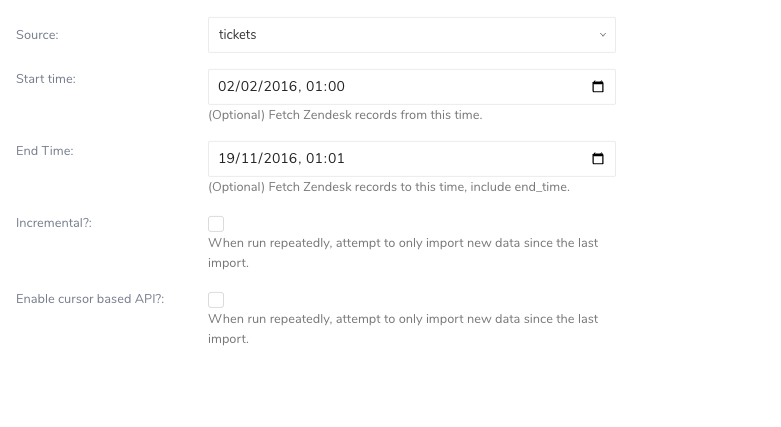
| Source | Zendeskから転送するオブジェクトの種類を指定します:tickets、ticket_fields、ticket_forms、ticket_events、ticket_metrics、users、organizations、scores、recipients、object_records、relationship_records、user_events、chat - object_recordsとrelationship_recordsはZendeskカスタムオブジェクトに関する情報を提供します - scoresとrecipientsはZendesk NPSに関する情報を提供します - Chatの制限事項: - 管理者または所有者のみがChatデータを取得する権限を持ちます。 - 「Include Subresources」および「De-duplicate records」オプションはサポートされていません |
|---|---|
| Incremental | コネクタがインクリメンタルモードで実行できるようにし、Start timeとEnd timeを使用できるようにします。 |
| Start time | 'start_time'以降に更新されたオブジェクトのみを選択できるようにします - Start timeが指定されていない場合、すべてのオブジェクトが最初から取得されます。 |
| End time | 'end_time'まで更新されたオブジェクトのみを選択できるようにします。 - End timeが指定されていない場合、現在までのすべてのオブジェクトが取得されます。 - Start timeとEnd timeを組み合わせて、'start_time'から'end_time'までの特定の期間内に更新されたオブジェクトのみを選択できます |
| Enable cursor-based API | cursor APIフローを使用して100,000件を超えるレコードを取得できるようにします。 - ticketsとusers sourceのみに適用されます - Start timeのみを使用したincrementalをサポートします |
データをプレビューします。変更を加えるには、Advanced Settingsをクリックします。
Nextを選択します。
Advanced Settingsを選択すると、次のダイアログが開きます。
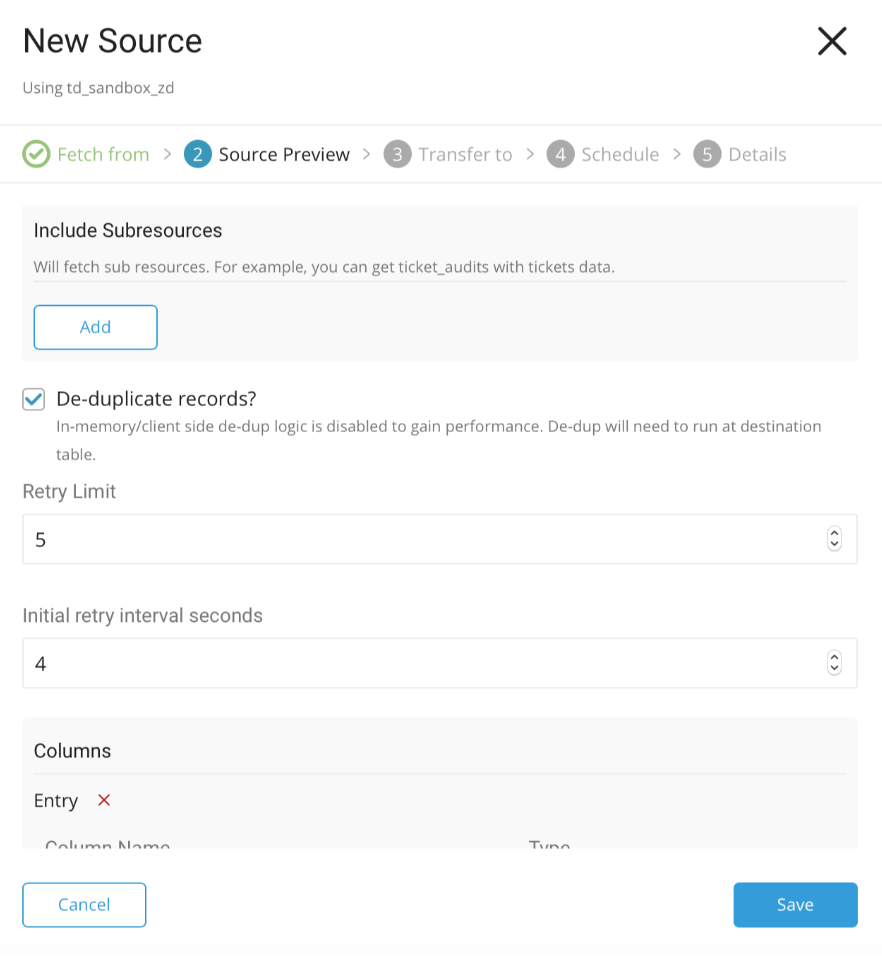
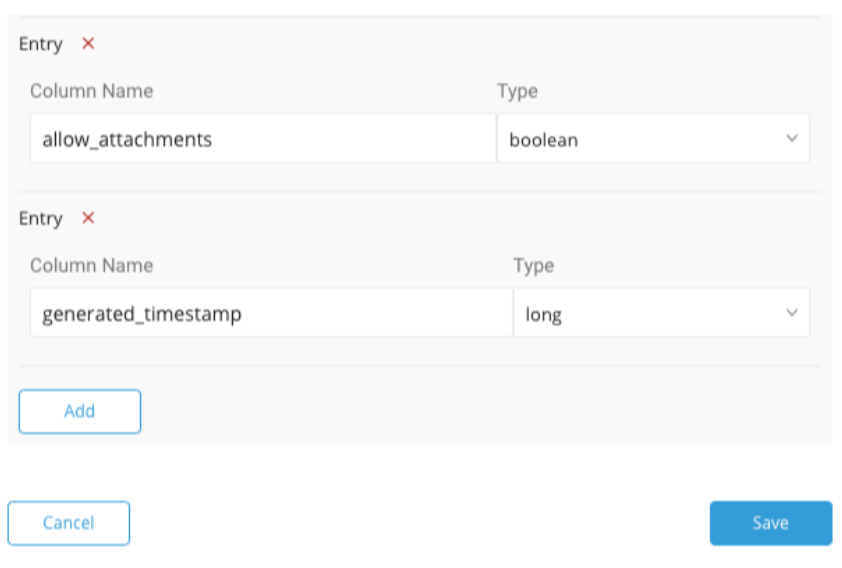
パラメータを編集します。Save and Nextを選択します。
| Parameter | Description |
|---|---|
| Include Subresources | メインオブジェクトと共にサブリソースを取得できるようにします。Addをクリックして名前でサブリソースを追加し、対応するカラムもAddします。サブリソースはJSONオブジェクトとして扱われ、同じ名前のカラムに表示されます。 - Zendeskでは、このエンドポイントがサポートされています:GET /api/v2/users/{user_id}/organizations.json つまり、organizationsをusersのサブリソースと見なすことができます。ユーザーが所属するorganizationsのすべての情報を取得できます。 - これを設定するには、'organizations'をサブリソースとして追加し、同じ名前のカラムをもう1つ追加する必要があります。データ型はJSONである必要があります。 - Include SubresourcesはChatではサポートされていません。 |
| De-duplicated Records | Zendesk APIは重複を防止しないため、インクリメンタルモードで実行する際に重複レコードを回避できるようにします。 - 重複排除はChatではサポートされていません。 |
| Retry Limit | エラーが発生したときにジョブが再試行する回数を示します。 |
| Initial retry interval seconds | 再試行前の最初の待機時間を示します。秒単位で測定されます。 |
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
Zendeskからデータをインポートするサンプルワークフローについては、Treasure Boxesを参照してください。
最新のTD Toolbeltをインストールします。
次の例に示すように、login_url、username(メールアドレス)、token、およびtargetを使用してseed.ymlを準備します。この例では、"append"モードを使用します。
in:
type: zendesk
login_url: https://YOUR_DOMAIN_NAME.zendesk.com
auth_method: token
username: YOUR_EMAIL_ADDRESS
token: YOUR_API_TOKEN
target: tickets
start_time: "2007-01-01 00:00:00+0000"
enable_cursor_based_api: true
out:
mode: appendtokenは、Admin Home –> CHANNELS –> API –> "add new token"(https://YOUR_DOMAIN_NAME.zendesk.com/agent/admin/api)から作成できます。
targetは、Zendeskからダンプするオブジェクトのタイプを指定します。tickets、ticket_events、ticket_forms、ticket_fields、users、organizations、scores、recipients、object_records、relationship_records、user_eventsがサポートされています。
利用可能なoutモードの詳細については、付録を参照してください。
connector:guessを使用します。このコマンドは、ターゲットデータを自動的に読み取り、データフォーマットをインテリジェントに推測します。
$ td connector:guess seed.yml -o load.ymlload.ymlファイルを開くと、ファイルフォーマット、エンコーディング、カラム名、タイプなどを含む推測されたファイルフォーマット定義が表示されます。
in:
type: zendesk
login_url: https://YOUR_DOMAIN_NAME.zendesk.com
auth_method: token
username: YOUR_EMAIL_ADDRESS
token: YOUR_API_TOKEN
target: tickets
start_time: '2019-05-15T00:00:00+00:00'
columns:
- {name: url, type: string}
- {name: id, type: long}
- {name: external_id, type: string}
- {name: via, type: json}
- {name: created_at, type: timestamp, format: "%Y-%m-%dT%H:%M:%S%z"}
- {name: updated_at, type: timestamp, format: "%Y-%m-%dT%H:%M:%S%z"}
- {name: type, type: string}
- {name: subject, type: string}
- {name: raw_subject, type: string}
- {name: description, type: string}
- {name: priority, type: string}
- {name: status, type: string}
- {name: recipient, type: string}
- {name: requester_id, type: string}
- {name: submitter_id, type: string}
- {name: assignee_id, type: string}
- {name: organization_id, type: string}
- {name: group_id, type: string}
- {name: collaborator_ids, type: json}
- {name: follower_ids, type: json}
- {name: email_cc_ids, type: json}
- {name: forum_topic_id, type: string}
- {name: problem_id, type: string}
- {name: has_incidents, type: boolean}
- {name: is_public, type: boolean}
- {name: due_at, type: string}
- {name: tags, type: json}
- {name: custom_fields, type: json}
- {name: satisfaction_rating, type: json}
- {name: sharing_agreement_ids, type: json}
- {name: fields, type: json}
- {name: followup_ids, type: json}
- {name: ticket_form_id, type: string}
- {name: brand_id, type: string}
- {name: satisfaction_probability, type: string}
- {name: allow_channelback, type: boolean}
- {name: allow_attachments, type: boolean}
- {name: generated_timestamp, type: long}
out:
{mode: append}
exec: {}
filters:
type: add_time
from_value:
{mode: upload_time}
to_column: {name: time}次に、previewコマンドを使用して、システムがファイルをどのように解析するかをプレビューできます。
$ td connector:preview load.ymlシステムが予期しないカラム名や型を検出した場合は、load.ymlを直接変更して再度プレビューしてください。
Data Connectorは、「boolean」、「long」、「double」、「string」、および「timestamp」型の解析をサポートしています。
ロードジョブを送信します。データサイズによっては数時間かかる場合があります。ユーザーは、データが保存されるデータベースとテーブルを指定する必要があります。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table上記のコマンドは、*database(td_sample_db)とtable(td_sample_table)*がすでに作成されていることを前提としています。データベースまたはテーブルがTDに存在しない場合、このコマンドは成功しませんので、データベースとテーブルを手動で作成するか、td connector:issueコマンドで--auto-create-tableオプションを使用してデータベースとテーブルを自動的に作成してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table --time-column created_at --auto-create-table「--time-column」オプションを使用して、Time Formatカラムを「Partitioning Key」に割り当てることができます。
incrementalフラグを使用して、Zendeskからレコードをインクリメンタルにロードできます。Falseの場合、next.ymlのstart_timeとend_timeは更新されません。コネクターは常に静的な条件でZendeskからすべてのデータを取得します。Trueの場合、next.ymlでstart_timeとend_timeが更新されます。デフォルトはTrueです。
in:
type: zendesk
login_url: https://YOUR_DOMAIN_NAME.zendesk.com
auth_method: token
username: YOUR_EMAIL_ADDRESS
token: YOUR_API_TOKEN
target: tickets
start_time: "2007-01-01 00:00:00+0000" end_time: "2008-01-01 00:00:00+0000"
incremental: true
out:
mode: appendZendeskは、100,000件を超えるレコードを取得できるページネーションエンドポイントをサポートしています。このエンドポイントは、usersとticketsターゲットにのみ適用されます。詳細については、Introducing Pagination Changes - Zendesk APIを参照してください。
新しいエンドポイントを使用するには、Enable cursor-based APIを有効にしてください。