この機能はベータ版です。詳細については、カスタマーサクセス担当者にお問い合わせください。
SendGridは、ユーザーがメールサーバーを維持することなくメールを送信できるクラウドベースのSMTPプロバイダーです。このIntegrationにより、TDユーザーはSendGrid上で作成されたキャンペーンの応答イベントとパフォーマンスメトリクスを収集できます。また、コンタクト、シングルセンド、メッセージなどの他のマーケティングデータの収集も可能です。
- Treasure Dataの知識
- SendGridの知識
SendGridのAPIキーが必要です。API Keyを参照してください。
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
SendGridへの新しいAuthenticationを作成するには、次の手順に従います。
Integrations HubからCatalogを開きます。
CatalogでSendGridを検索します。
Create Authenticationを選択します。API Keyを入力して、Authenticationを保存します。
SendGridからContactsをインポートするには、次の手順に従います。
- TD Consoleを開きます。
- Integrations Hub > Authenticationsに移動します。
- 新しいAuthenticationを見つけて、New Sourceを選択します。
Contactsのインポートジョブを設定するために、次の設定パラメータを定義します。
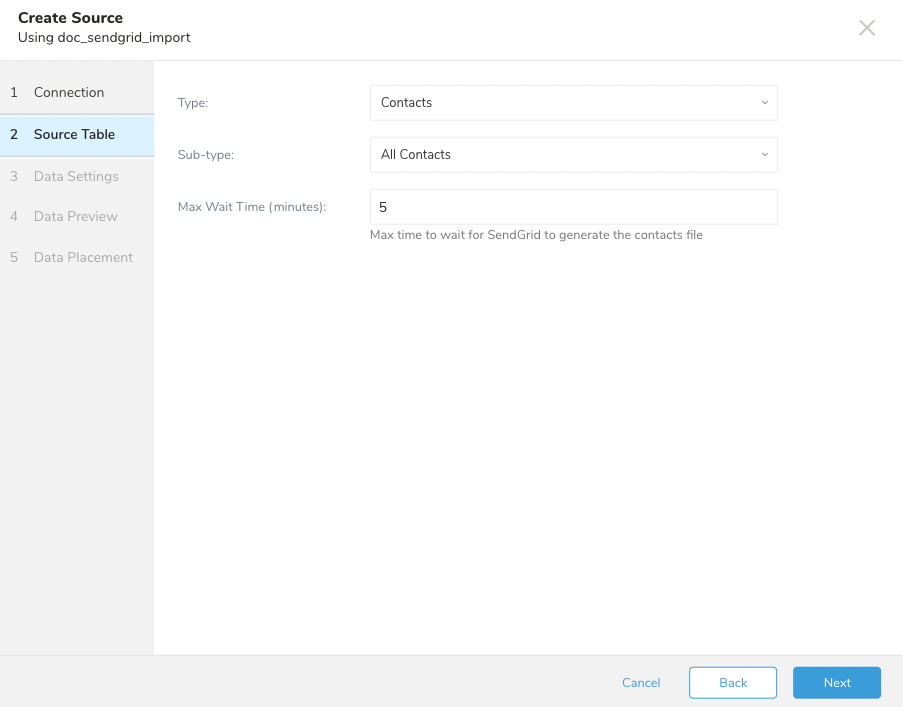
| パラメータ | 説明 |
|---|---|
| Type | インポートするデータのタイプ。Contactsを選択します。 |
| Sub-type | インポートするデータのサブタイプ。ユーザーは次のいずれかを選択できます: - All Contacts: すべてのコンタクトをインポートします。 - Lists: リスト内のコンタクトのみを取得します。 - Segments: セグメント内のコンタクトを取得します。 |
| List Name | Listsの場合のみ。フィルタリングするリストの名前を入力します。 |
| Segment Name | Segmentsの場合のみ。フィルタリングするセグメントの名前を入力します。 |
| Max Wait Time | SendGridがデータファイルを生成するための最大待機時間(分単位)。 |
Nextを選択します。
Integrationは、SendGridによって定義された標準コンタクトスキーマのフィールドを表示します。
Nextを選択します。
SendGridは、コンタクトファイルの準備と生成のプロセスを処理します。タイムアウトを避けるために、Integrationはダミーデータのみを表示します。
データプレビューはオプションであり、必要に応じてNextをクリックしてダイアログの次のページに安全に進むことができます。
- Generate Previewを選択して、インポートを実行する前にデータのプレビューを表示します。
データプレビューに表示されるデータは、ソースから概算されたものです。インポートされる実際のデータではありません。
データが期待どおりに見えることを確認します。
Nextを選択します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
SendGridから統計情報を取得するためのサンプル設定に従います
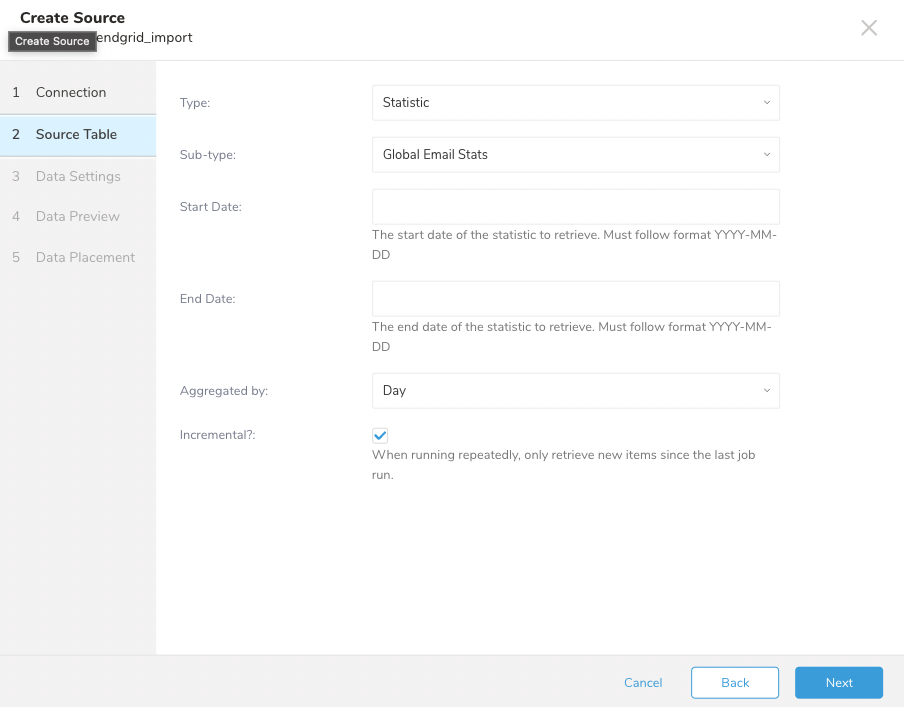
| パラメータ | 説明 |
|---|---|
| Type | インポートするデータのタイプ。Statisticを選択します。 |
| Sub-type | インポートするデータのサブタイプ。ユーザーは次のいずれかを選択できます: Global Email Stats: 送信されたすべてのメールからの統計をインポートします。 SingleSend Stats: シングルセンド別の統計をインポートします。 Automation Stats: オートメーション別の統計をインポートします。 |
| Start Date - End Date | Global Email Statsの場合のみ利用可能。日付でフィルタリングします。Start Dateは必須です。 |
| Aggregated by | Global Email Statsの場合のみ利用可能。データの集計方法を定義します*(Day、Week、Month、None)*。 |
| Incremental | Global Email Statsの場合のみ利用可能。繰り返し実行の場合、次の時間枠内のデータのみを検索します。 |
SendGridからSuppressionsイベントを取得するためのサンプル設定に従います。Integrationは次をサポートします:
- Bounces
- Unsubscribes
- Blocks
- Spam Reports
- Invalid
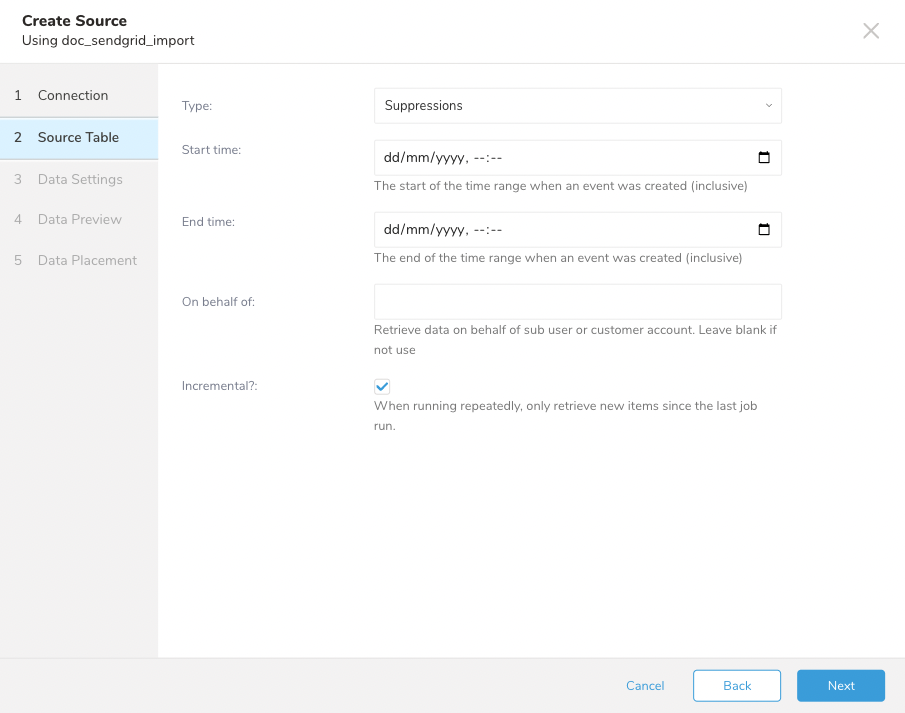
| パラメータ | 説明 |
|---|---|
| Type | インポートするデータのタイプ。Suppressionsを選択します。 |
| Start Time - End Time | 検索期間を定義します。Incrementalがオンの場合、Start Timeは必須です。 |
| On behalf of | (オプション)サブユーザーまたは顧客アカウントからデータを取得するために使用します。 |
| Incremental | 繰り返し実行の場合、次の時間枠内のデータのみを検索します。 |
SendGridからのデータ定義はSuppressionタイプによって異なるため、以下はTDに取り込まれる際のデータスキーマです。
type;created;email;reason;status;ipblock;1714970265;testemail4@email.com;blockreason;blockstatus;nullinvalid;1714970265;testemail5@email.com;dummyreason;null;nullbounce;1714970265;testemail@email.com;550 Inconsistent;550;nullspam_report;1714970265;testemail2@email.com;null;null;192.168.1.1unsubscribe;1714970265;testemail3@email.com;null;null;nullSendGridからSingle Sendsデータをインポートするには、次の手順に従います。
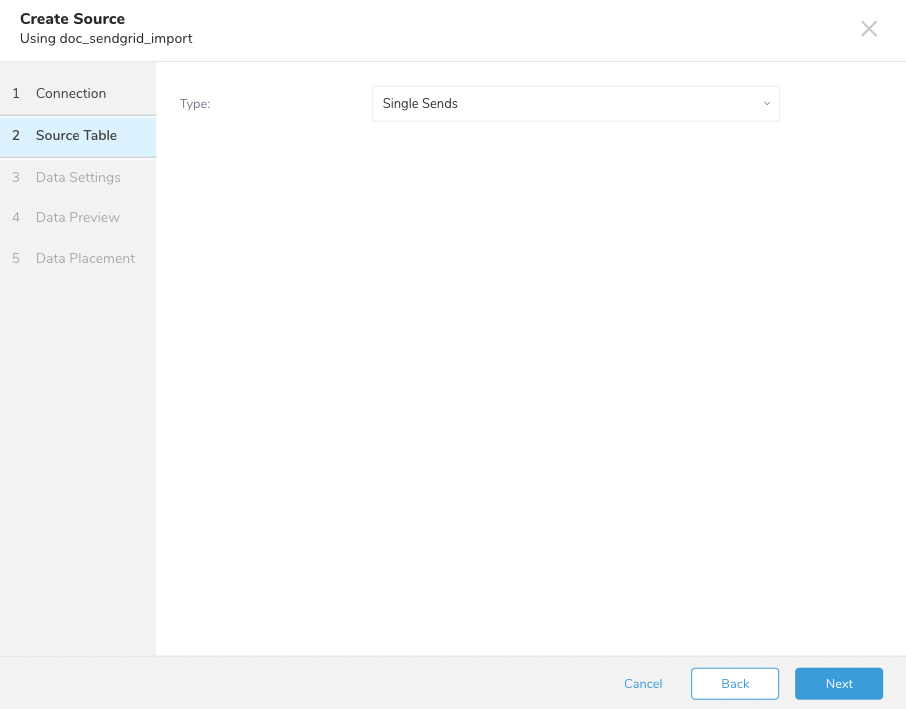
SendGridからMessage Dataをインポートするには、次の手順に従います。
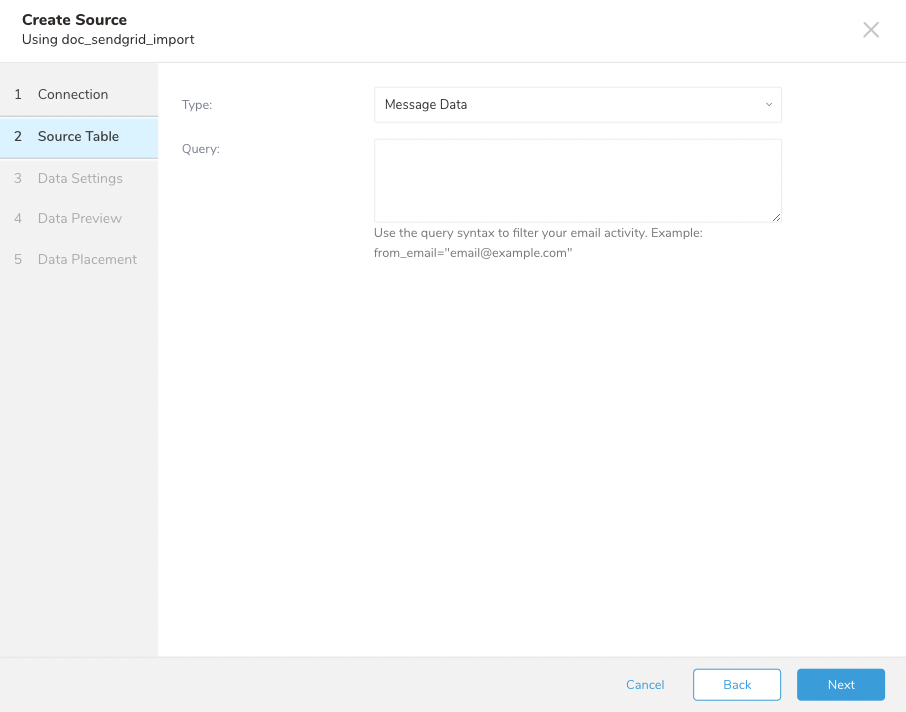
| パラメータ | 説明 |
|---|---|
| Type | インポートするデータのタイプ。Message Dataを選択します。 |
| Query | クエリでフィルタリングします。クエリ構文を参照してください。 |
WorkflowのTD_load>: operatorを使用して、SendGridからデータをインポートできます。すでにSOURCEを作成している場合は実行できます。作成したくない場合は、ymlファイルを使用してインポートできます。
- Sourceを特定します。
- Unique IDを取得するには、SourceリストをSendGridでフィルタリングします。
- メニューを開き、Copy Unique IDを選択します。
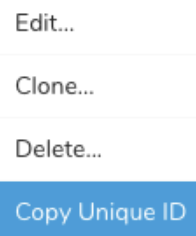
- td_load > operatorを使用してWorkflowタスクを定義します。
+load:
td_load>: unique_id_of_your_source
database: ${td.dest_db}
table: ${td.dest_table}- Workflowを実行します。
- ymlファイルを特定します。ymlファイルを作成する必要がある場合は、参考としてAmazon S3 Import Integration Using CLIを確認してください。
- td_load > operatorを使用してWorkflowタスクを定義します。
+load:
td_load>: config/daily_load.yml
database: ${td.dest_db}
table: ${td.dest_table}- Workflowを実行します。
| 名前 | 説明 | 値 | デフォルト値 | 必須 |
|---|---|---|---|---|
| type | Integrationタイプ | sendgrid | sendgrid | Yes |
| api_key | 接続用のAPIキー | N/A | N/A | Yes |
| data_type | 取得するデータタイプ | statistic suppressions contacts message_data single_sends | statistic | Yes |
| sub_type_statistic | 統計のサブタイプ | global_email_stats single_send_stats automation_stats | global_email_stats | No |
| sub_type_contacts | コンタクトのサブタイプ | all_contacts lists segments | all_contacts | No |
| start_date | all_contactsの開始日 | String | incremental_statisticsがtrueの場合のみ必須 | |
| end_date | all_contactsの終了日 | String | No | |
| aggregated_by | all_contactsの集計方法 | day week month year | day | No |
| incremental_statistics | all_contactsの増分モード | true false | true | No |
| start_time | data_type suppressionsの開始時刻 | String | No | |
| end_time | data_type suppressionsの終了時刻 | String | No | |
| incremental_suppressions | suppressionsの増分モード | true false | true | No |
| on_behalf_of | サブユーザーまたは顧客アカウントからデータを取得するために使用します。 | String | No | |
| sub_type_contacts | コンタクトのサブタイプ | all_contacts lists segments | all_contacts | No |
| list_name | コンタクトのリストの名前 | カンマで区切られた文字列のリスト | sub_type_contacts がlistsの場合は必須 | |
| segment_name | コンタクトのセグメントの名前 | カンマで区切られた文字列のリスト | sub_type_contacts がsegmentsの場合は必須 | |
| max_wait_time | コンタクトをエクスポートするための最大待機時間(分単位) | Integer | 5 | No |
| query | message_dataのクエリ | String | No | |
| maximum_retries | 最大リトライ回数 | Integer | 5 | No |
| initial_retry_interval_millis | 初回リトライ待機時間(ミリ秒単位) | Integer | 500 | No |
| maximum_retry_interval_millis | 最大リトライ待機時間(ミリ秒単位) | Integer | 30000 | No |
| columns | カラム定義 | Json | Yes |
サンプルWorkflowコードについては、Treasure Boxesを参照してください。
Integrationを設定する前に、最新のTD Toolbeltをインストールしてください。
in:
type: sendgrid
api_key: XXXXXXXXXX
data_type: contacts
sub_type_statistic: global_emal_stats
sub_type_contacts: list
start_time: '2023-01-19-T00:51:29.937Z'
end_time: '2023-01-19-T00:51:29.937Z'
start_date: '2023-01-01'
end_date: '2023-01-01'
aggregated_by: day
query: to_email="dumy@gmail.com"
list_name: 'abc,def'
segment_name: 'abc,def'
incremental_statistic: true
incremental_suppressions: true
max_wait_time: 5
on_behalf_of: xxx
initial_retry_interval_millis: 500
maximum_retries: 5
maximum_retry_interval_millis: 30000
out:
mode: append| 名前 | 説明 | 値 | デフォルト値 | 必須 |
|---|---|---|---|---|
| type | Integrationタイプ | sendgrid | sendgrid | Yes |
| api_key | 接続用のAPIキー | N/A | N/A | Yes |
| data_type | 取得するデータタイプ | statistic suppressions contacts message_data single_sends | statistic | Yes |
| sub_type_statistic | 統計のサブタイプ | global_email_stats single_send_stats automation_stats | global_email_stats | No |
| sub_type_contacts | コンタクトのサブタイプ | all_contacts lists segments | all_contacts | No |
| start_date | all_contactsの開始日 | String | incremental_statisticsがtrueの場合のみ必須 | |
| end_date | all_contactsの終了日 | String | No | |
| aggregated_by | all_contactsの集計方法 | day week month year | day | No |
| incremental_statistics | all_contactsの増分モード | true false | true | No |
| start_time | data_type suppressionsの開始時刻 | String | No | |
| end_time | data_type suppressionsの終了時刻 | String | No | |
| incremental_suppressions | suppressionsの増分モード | true false | true | No |
| on_behalf_of | サブユーザーまたは顧客アカウントからデータを取得するために使用します。 | String | No | |
| sub_type_contacts | コンタクトのサブタイプ | all_contacts lists segments | all_contacts | No |
| list_name | コンタクトのリストの名前 | カンマで区切られた文字列のリスト | sub_type_contacts がlistsの場合は必須 | |
| segment_name | コンタクトのセグメントの名前 | カンマで区切られた文字列のリスト | sub_type_contacts がsegmentsの場合は必須 | |
| max_wait_time | コンタクトをエクスポートするための最大待機時間(分単位) | Integer | 5 | No |
| query | message_dataのクエリ | String | No | |
| maximum_retries | 最大リトライ回数 | Integer | 5 | No |
| initial_retry_interval_millis | 初回リトライ待機時間(ミリ秒単位) | Integer | 500 | No |
| maximum_retry_interval_millis | 最大リトライ待機時間(ミリ秒単位) | Integer | 30000 | No |
Data Integrationは、指定されたprefixに一致するすべてのファイルをインポートします。
- 例
path_prefix: path/to/sample_ –> path/to/sample_201501.csv.gz, path/to/sample_201502.csv.gz, …, path/to/sample_201505.csv.gz
connector:guessを使用します。このコマンドは自動的にソースファイルを読み取り、ロジックを使用してファイル形式とそのフィールド/カラムを推測します。
$ td connector:guess seed.yml -o load.ymlload.ymlを開いて、ファイル形式、エンコーディング、カラム名、タイプの定義を確認できます。
in:
type: sendgrid
api_key: XXXXXXXXXX
data_type: contacts
sub_type_statistic: global_emal_stats
sub_type_contacts: list
start_time: '2023-01-19-T00:51:29.937Z'
end_time: '2023-01-19-T00:51:29.937Z'
start_date: '2023-01-01'
end_date: '2023-01-01'
aggregated_by: day
query: to_email="dumy@gmail.com"
list_name: 'abc,def'
segment_name: 'abc,def'
incremental_statistic: true
incremental_suppressions: true
max_wait_time: 5
on_behalf_of: xxx
initial_retry_interval_millis: 500
maximum_retries: 5
maximum_retry_interval_millis: 30000
columns:
- {name: email, type: string}
- {name: first_name, type: string}
- {name: last_name, type: string}
- {name: created_at, type: timestamp, format: '%Y-%m-%dT%H:%M:%S%z'}
- {name: date, type: timestamp, format: '%Y-%m-%d'}
out:
mode: appendデータをプレビューするには、td connector:previewコマンドを使用します。
$ td connector:preview load.ymlguessコマンドは、ソースデータファイル内に3行以上と2列以上が必要です。これは、コマンドがソースデータのサンプル行を使用してカラム定義を評価するためです。
システムがカラム名またはカラムタイプを予期せず検出した場合は、load.ymlファイルを変更して再度プレビューしてください。
- load jobを送信します。
データサイズによっては数時間かかる場合があります。データを保存するTreasure DataのDatabaseとTableを必ず指定してください。
Treasure Dataのストレージは時間によってパーティション化されているため(data partitioningを参照)、Treasure Dataは*-- time-columnオプションの指定も推奨しています。このオプションが提供されない場合、data connectorは最初のlongまたはtimestamp*カラムをパーティション化時間として選択します。--time-columnで指定されるカラムのタイプは、longまたはtimestampタイプのいずれかである必要があります。
データに時間カラムがない場合は、add_timeフィルタオプションを使用して追加できます。詳細については、add_timeフィルタプラグインを参照してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table --time-column created_atconnector:issueコマンドは、database(td_sample_db)とtable(td_sample_table)がすでに作成されていることを前提としています。DatabaseまたはTableがTDに存在しない場合、このコマンドは失敗します。DatabaseとTableを手動で作成するか、td connector:issueコマンドで--auto-create-tableオプションを使用してDatabaseとTableを自動作成してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table --time-column created_at --auto-create-tabledata connectorはサーバー側でレコードをソートしません。時間ベースのパーティション化を効果的に使用するには、事前にファイル内のレコードをソートしてください。
timeという名前のフィールドがある場合は、--time-columnオプションを指定する必要はありません。
$ td connector:issue load.yml --database td_sample_db --table td_sample_tableload.ymlファイルのoutセクションでファイルインポートモードを指定できます。out:セクションは、データがTreasure DataのTableにインポートされる方法を制御します。例えば、データを追加したり、Treasure Data内の既存のTableのデータを置き換えたりすることができます。
| Mode | 説明 | 例 |
|---|---|---|
| Append | レコードはターゲットTableに追加されます。 | in: ... out: mode: append |
| Always Replace | ターゲットTableのデータを置き換えます。 ターゲットTableに対して行われた手動のスキーマ変更はそのまま残ります。 | in: ... out: mode: replace |
| Replace on new data | インポートする新しいデータがある場合にのみ、ターゲットTableのデータを置き換えます。 | in: ... out: mode: replace_on_new_data |
増分ファイルインポートのために、定期的なData Integration実行をスケジュールできます。Treasure Dataは、高可用性を確保するためにスケジューラを慎重に設定しています。
スケジュールされたインポートでは、指定されたprefixに一致し、条件により次のフィールドのいずれかに該当するすべてのファイルをインポートできます:
- use_modified_timeが無効になっている場合、最後のパスが次の実行のために保存されます。Integrationは、2回目以降の実行では、アルファベット順で最後のパス以降のファイルのみをインポートします。
- それ以外の場合、ジョブの実行時間が次の実行のために保存されます。2回目以降の実行では、Integrationはその実行時間以降に変更されたファイルのみをアルファベット順でインポートします。
新しいスケジュールは、td connector:createコマンドを使用して作成できます。
$ td connector:create daily_import "10 0 * * *" td_sample_db td_sample_table load.ymlTreasure Dataのストレージは時間によってパーティション化されているため(data partitioningも参照)、Treasure Dataは*--time-column*オプションの指定も推奨しています。
$ td connector:create daily_import "10 0 * * *" td_sample_db td_sample_table load.yml --time-column created_atcronパラメータは、@hourly、@daily、@monthlyの3つの特別なオプションも受け入れます。
デフォルトでは、スケジュールはUTCタイムゾーンで設定されます。-tまたは--timezoneオプションを使用して、タイムゾーンでスケジュールを設定できます。--timezoneオプションは、'Asia/Tokyo'、'America/Los_Angeles'などの拡張タイムゾーン形式のみをサポートしています。PST、CSTなどのタイムゾーンの略語はサポートされておらず、予期しないスケジュールにつながる可能性があります。
SendGrid Export Integration - SendGrid Output
SendGrid API - API Reference