KARTE Export Integrationについて詳しく知る。
KARTE Data Connectorを使用して、Google Cloud Storage (GCS) バケットに保存されている*.tsvおよび*.csvファイルの内容をTreasure Dataにインポートできます。
Treasure Dataの基本知識
既存のGoogle Service Account
- Google Developers ConsoleからJSONキーファイルを生成して取得する必要があります。詳細については、Google Cloud Platformのドキュメントのサービスアカウント認証情報の生成セクションを参照してください。
TD Consoleを使用して接続を設定できます。
Integrations Hub > Catalogに移動して検索します。KARTEを選択します。

次のダイアログが開きます。
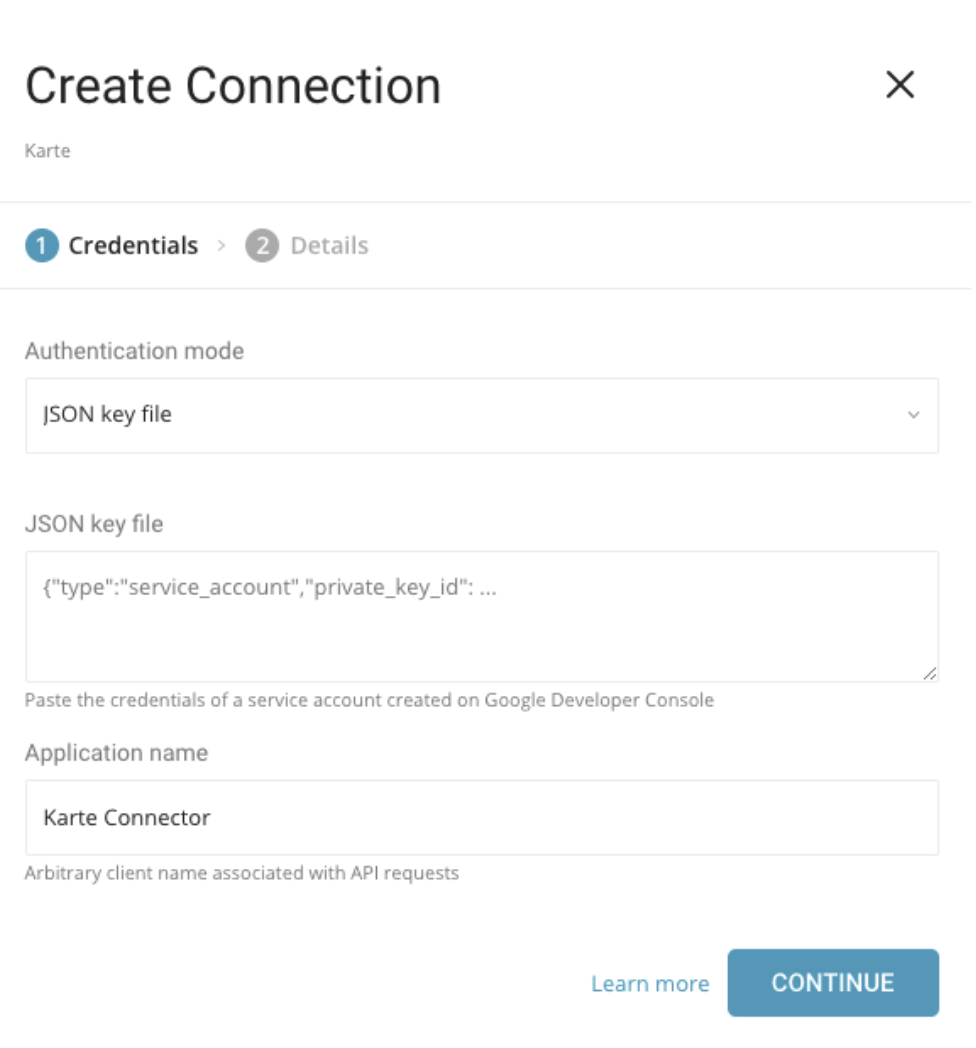
必要な認証情報を入力します。TD Consoleでは、JSONキーファイルのみを使用して認証できます。
- JSON key file: Google Developers Consoleから生成されたJSONキーファイルの内容をこのフィールドにコピー&ペーストします。
- Application Name: KARTEがデフォルト値です。KARTEは、このコネクタに対してTreasure Dataが選択した名前です。
Continueを選択します。
データコネクタの名前を指定し、Doneを選択します。
Connectionsページが表示されます。New Transferを選択します。
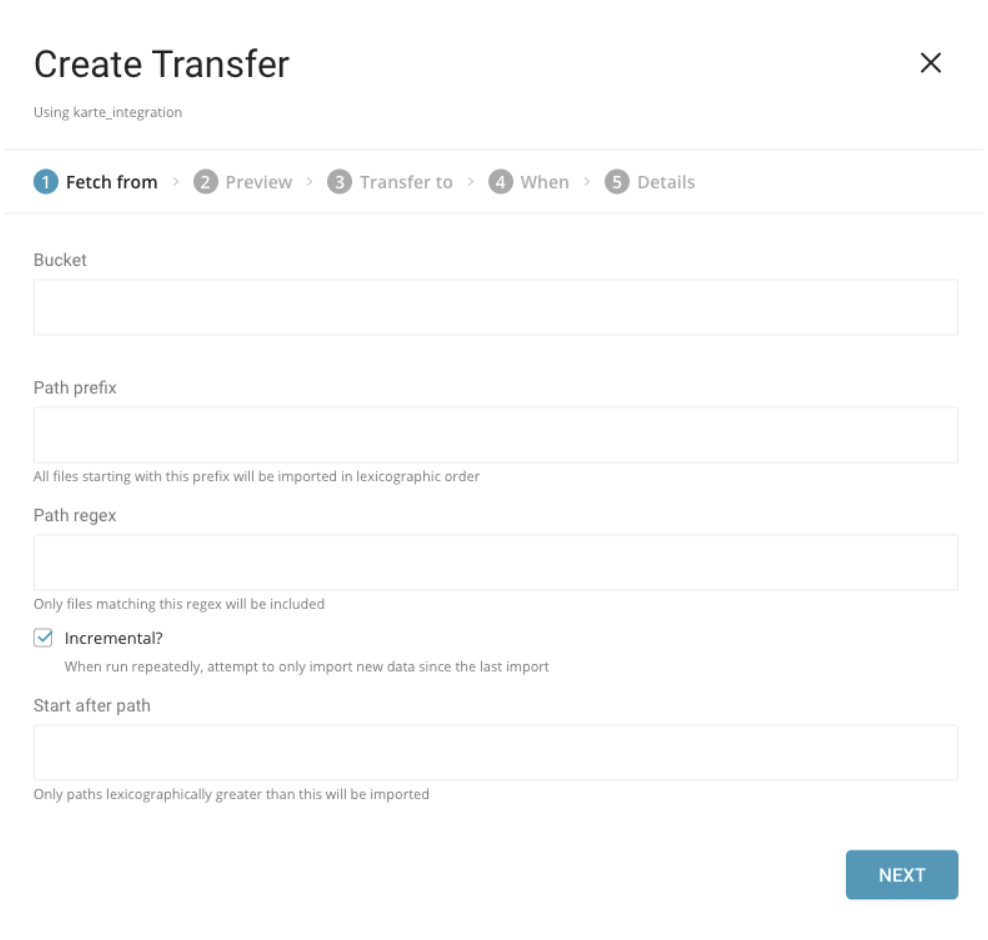
以下のセクションでは、フェッチ、プレビュー、転送、スケジュール、および詳細の確認に関する手順を説明します。
取り込みたい情報を登録する必要があります。
- Bucket. Google Cloud Storageバケット名(例: your_bucket_name)。
- Path Prefix. ターゲットキーのプレフィックス(例: logs/data_)。
- Path Regex. ファイルパスにマッチする正規表現を指定します。ファイルパスがこのパターンにマッチしない場合、そのファイルはスキップされます(例: .csv$ の場合、パスがこのパターンにマッチしないファイルはスキップされます)。
- Start after path. last_pathパラメータを挿入して、最初の実行でこのパスより前のファイルをスキップします(例: logs/data_20170101.csv)。
- Incremental. インクリメンタルローディングを有効にします。インクリメンタルローディングが有効な場合、次の実行のconfig diffにはlast_pathパラメータが含まれ、次の実行ではそのパスより前のファイルがスキップされます。それ以外の場合、last_pathは含まれません。
例
Amazon CloudFrontは、静的および動的Webコンテンツの配信を高速化するWebサービスです。CloudFrontを設定して、CloudFrontが受信するすべてのユーザーリクエストに関する詳細情報を含むログファイルを作成できます。ロギングを有効にすると、次のようなCloudFrontログファイルを保存できます。
[your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-15.a103fd5a.gz]
[your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-15.b2aede4a.gz]
[your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-16.594fa8e6.gz]
[your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-16.d12f42f9.gz]この場合、Fetch fromの設定は次のようになります。
- Bucket: your_bucket
- Path Prefix: logging/
- Path Regex: .gz$ (必須ではありません)
- Start after path: logging/E231A697YXWD39.2017-04-23-15.b2aede4a.gz (2017-04-23-16からログファイルをインポートしたい場合)
- Incremental: true (このジョブをスケジュールしたい場合)
データのプレビューが表示されます。データプレビューの仕組みの詳細については、About Data Previewを参照してください。 指定したカラム名の設定などの変更を行う場合は、Advanced Settingsを選択します。それ以外の場合は、Nextを選択します。
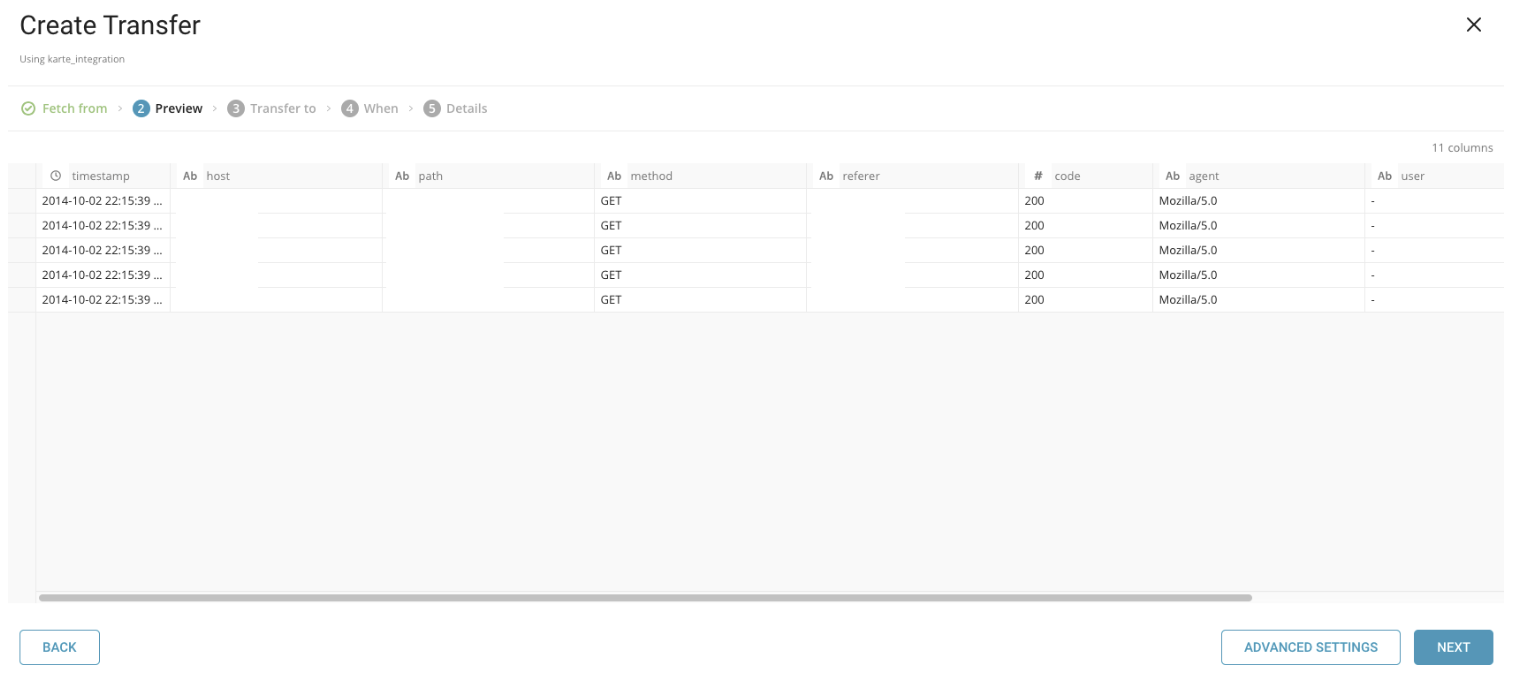
Advanced Settingsでは、プロパティを編集できます。以下のプロパティが利用可能です。
- Default timezone. 値自体にタイムゾーンが含まれていない場合、timestampカラムのタイムゾーンを変更します。
- Columns
Name. カラムの名前を変更します。カラム名は小文字のアルファベット、数字、および"_"のみをサポートします。
Type. 指定されたタイプとして値を解析し、TreasureDataスキーマに変換した後でそのタイプを保存します。
- boolean
- long
- timestamp: TreasureDataではstring型としてインポートされます(例: 2017-04-01 00:00:00.000)
- double
- string
- json
- Total file count limit. 読み取るファイルの最大数(オプション)。
インポート用の既存のデータベースとテーブルを選択するか、新しいものを作成します。
- Mode: AppendまたはReplace。既存のテーブルにレコードを追加するか、既存のテーブルを置き換えるかを選択します。
- Partition Key Seed: パーティショニング時間としてlongまたはtimestampカラムを選択します。デフォルトの時間カラムとして、add_timeフィルタを使用したupload_timeを使用します。
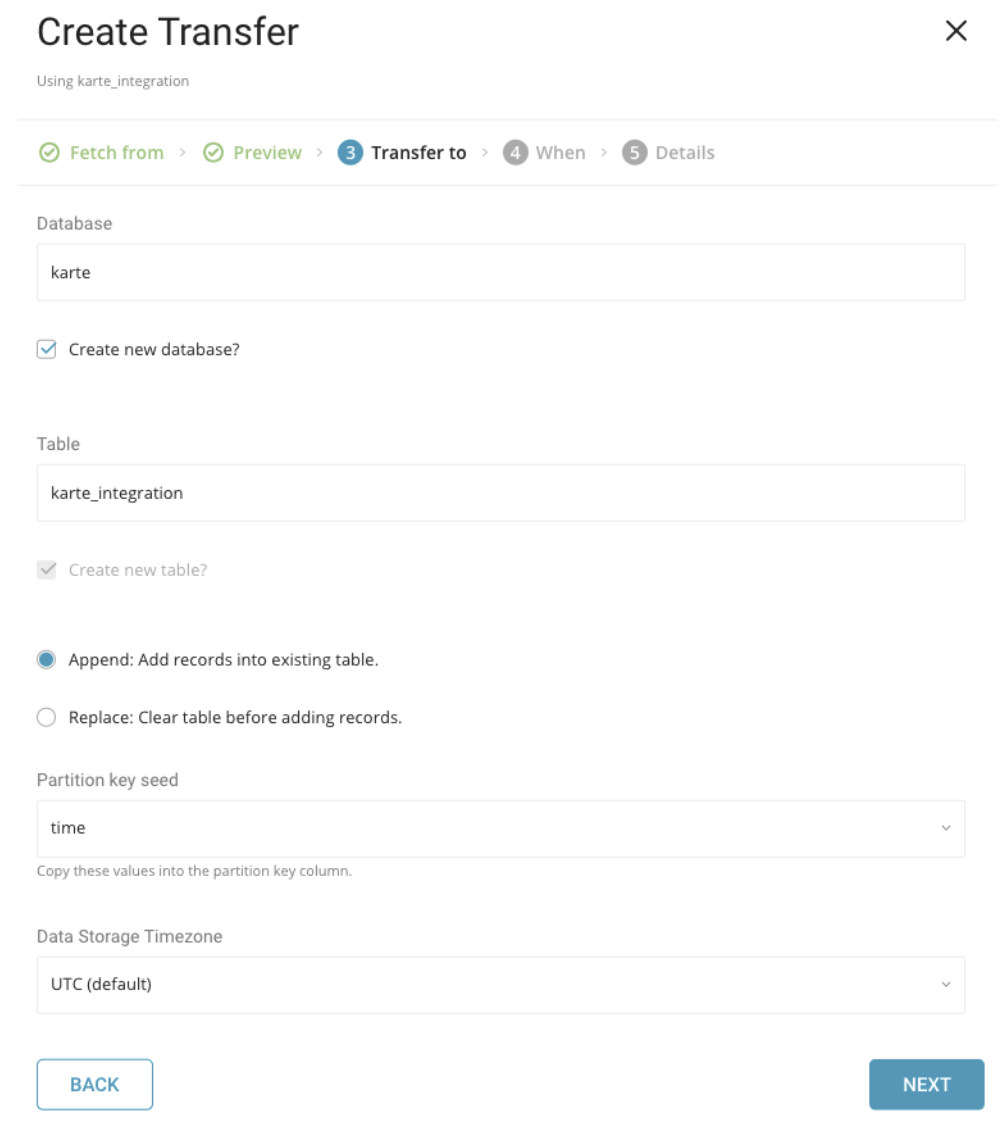
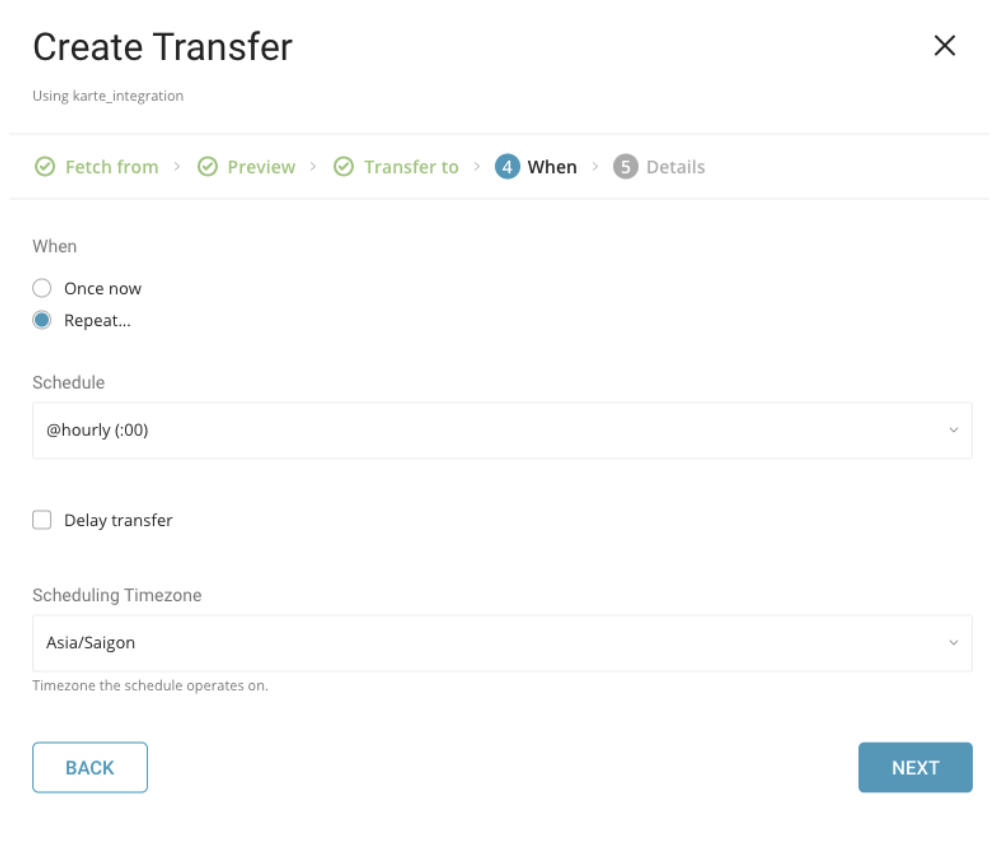
1回限りの転送または自動的に繰り返される転送のスケジュールを指定できます。
以下のパラメータを使用してスケジュールを設定します。
Once now. ジョブを1回実行します。
Repeat
- Schedule. @hourly、@daily、@monthlyの3つのオプション、およびカスタムcronでスケジュールできます。
- Delay Transfer. 指定された実行時刻に遅延を追加します。
Timezone. 拡張タイムゾーン形式をサポートします(例: Asia/Tokyo)。
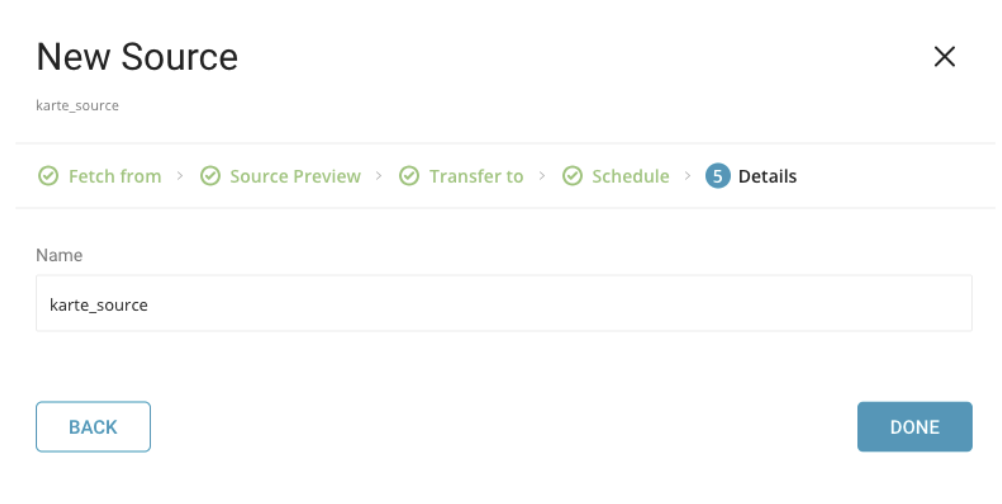
ソースの名前を作成し、DONEを選択してKARTE connectorを新しいソースとして保存します。
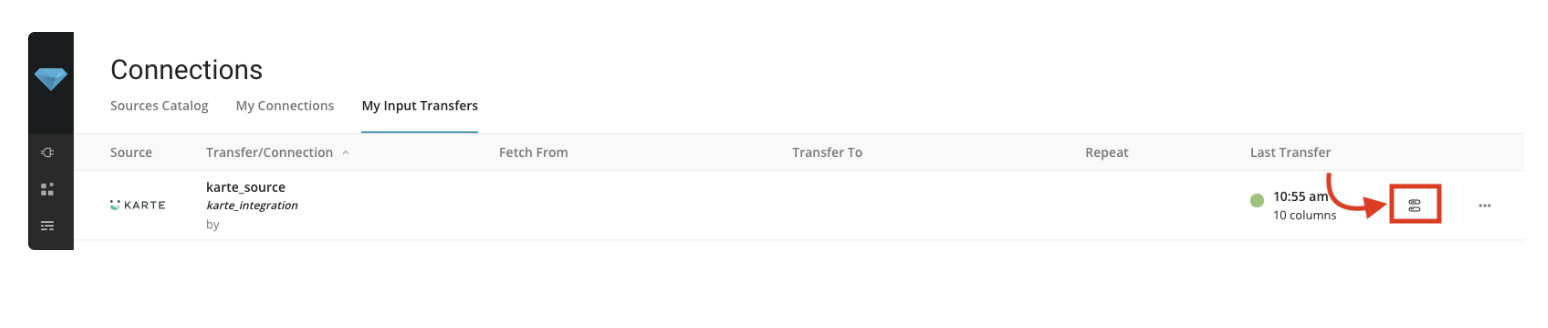
My Input Transfersで既存のジョブを編集します。このデータコネクタの以前の転送の詳細を表示するには、ジョブアイコンを選択します。
コネクタをセットアップする前に、Treasure Data Toolbeltをインストールしてください。
以下の例とJSONキーファイルを使用してseed.ymlを準備します。バケットとターゲットファイル名(または複数ファイルの場合はプレフィックス)も指定する必要があります。
in:
type: karte
bucket: sample_bucket
path_prefix: path/to/sample_file # path the the *.csv or *.tsv file on your GCS bucket
auth_method: json_key
json_keyfile:
content: |
{
"private_key_id": "1234567890",
"private_key": "-----BEGIN PRIVATE KEY-----\nABCDEF",
"client_id": "...",
"client_email": "...",
"type": "service_account"
}
out:
mode: appendData Connector for KARTEは、指定されたプレフィックスに一致するすべてのファイルをインポートします。例:path_prefix: path/to/sample_ –> path/to/sample_201501.csv.gz, path/to/sample_201502.csv.gz, …, path/to/sample_201505.csv.gz
利用可能なoutモードの詳細については、下記の付録を参照してください。
connector:guessを使用します。このコマンドは、ターゲットファイルを自動的に読み取り、ファイル形式をインテリジェントに推測します。
$ td connector:guess seed.yml -o load.ymlload.ymlを開いて、ファイル形式、エンコーディング、カラム名、タイプなど、推測されたファイル形式定義を確認します。
in:
type: karte
bucket: sample_bucket
path_prefix: path/to/sample_file
auth_method: json_key
json_keyfile:
content: |
{
"private_key_id": "1234567890",
"private_key": "-----BEGIN PRIVATE KEY-----\nABCDEF",
"client_id": "...",
"client_email": "...",
"type": "service_account"
}
decoders:
- {type: gzip}
parser:
charset: UTF-8
newline: CRLF
type: csv
delimiter: ','
quote: '"'
escape: ''
skip_header_lines: 1
columns:
- name: id
type: long
- name: company
type: string
- name: customer
type: string
- name: created_at
type: timestamp
format: '%Y-%m-%d %H:%M:%S'
out:
mode: appendpreviewコマンドを使用して、システムがファイルをどのように解析するかをプレビューします。
$ td connector:preview load.yml
+-------+---------+----------+---------------------+
| id | company | customer | created_at |
+-------+---------+----------+---------------------+
| 11200 | AA Inc. | David | 2015-03-31 06:12:37 |
| 20313 | BB Imc. | Tom | 2015-04-01 01:00:07 |
| 32132 | CC Inc. | Fernando | 2015-04-01 10:33:41 |
| 40133 | DD Inc. | Cesar | 2015-04-02 05:12:32 |
| 93133 | EE Inc. | Jake | 2015-04-02 14:11:13 |
+-------+---------+----------+---------------------+guessコマンドは、ソースデータから取得したサンプル行を使用してカラム定義を推測するため、ソースデータファイルに3行以上、2カラム以上が必要です。
カラム名やカラムタイプが予期せず検出された場合は、load.ymlを直接修正して再度プレビューしてください。
Data Connectorは、「boolean」、「long」、「double」、「string」、「timestamp」タイプの解析をサポートしています。
previewコマンドは、指定されたバケットから1つのファイルをダウンロードし、そのファイルの結果を表示します。これにより、previewコマンドとissueコマンドの結果に違いが生じる可能性があります。
最後に、ロードジョブを送信します。データのサイズに応じて、数時間かかる場合があります。ユーザーは、データが格納されるデータベースとテーブルを指定する必要があります。
Treasure Dataのストレージは時間で分割されているため、--time-columnオプションを指定することをお勧めします(data partitioningも参照)。このオプションを指定しない場合、Data Connectorは最初のlongまたはtimestampカラムをパーティション分割時間として選択します。--time-columnで指定するカラムタイプは、longまたはtimestampタイプである必要があります。
データに時間カラムがない場合は、add_timeフィルターオプションを使用して追加してください。詳細については、add_timeフィルタープラグインを参照してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table \
--time-column created_at上記の例のコマンドは、database(td_sample_db)とtable(td_sample_table)がすでに作成されていることを前提としています。データベースまたはテーブルがTreasure Dataに存在しない場合、このコマンドは成功しません。代わりに、データベースとテーブルを手動で作成するか、td connector:issueコマンドで--auto-create-tableオプションを使用してデータベースとテーブルを自動作成してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table --time-column created_at --auto-create-tableData Connectorは、サーバー側でレコードをソートしません。時間ベースのパーティショニングを効果的に使用するには、事前にファイル内のレコードをソートしてください。
timeというフィールドがある場合は、--time-columnオプションを指定する必要はありません。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table高可用性スケジューラを使用すると、増分KARTEファイルインポートのための定期的なData Connectorの実行をスケジュールできます。この機能を使用することで、ローカルデータセンターでcronデーモンを使用する必要がなくなります。
スケジュールされたインポートの場合、Data Connector for KARTEは、最初に指定されたプレフィックスに一致するすべてのファイル(例:path_prefix: path/to/sample_ –> path/to/sample_201501.csv.gz, path/to/sample_201502.csv.gz, …, path/to/sample_201505.csv.gz)をインポートし、次回の実行のために最後のパス(path/to/sample_201505.csv.gz)を記憶します。
2回目以降の実行では、アルファベット順(辞書式順序)で最後のパスの後にあるファイルのみをインポートします。例:path/to/sample_201506.csv.gz, …
td connector:createコマンドを使用して、新しいスケジュールを作成できます。以下が必要です:
- スケジュール名
- cron形式のスケジュール
- データが保存されるデータベースとテーブル。
- Data Connector設定ファイル。
$ td connector:create \
daily_import \
"10 0 * * *" \
td_sample_db \
td_sample_table \
load.ymlTreasure Dataのストレージは時間で分割されているため、--time-columnオプションを指定することをお勧めします(アーキテクチャも参照してください)。
$ td connector:create \
daily_import \
"10 0 * * *" \
td_sample_db \
td_sample_table \
load.yml \
--time-column created_atcronパラメータは、@hourly、@daily、@monthlyの3つの特別なオプションも受け付けます。
デフォルトでは、スケジュールはUTCタイムゾーンで設定されます。-tまたは--timezoneオプションを使用してタイムゾーンでスケジュールを設定できます。--timezoneオプションは、'Asia/Tokyo'、'America/Los_Angeles'などの拡張タイムゾーン形式のみをサポートしています。PST、CSTなどのタイムゾーン略語はサポートされておらず、予期しないスケジュールにつながる可能性があります。
td connector:listコマンドを実行すると、スケジュールされたエントリのリストを確認できます。
$ td connector:list
+--------------+------------+----------+-------+--------------+-----------------+----------------------------+
| Name | Cron | Timezone | Delay | Database | Table | Config |
+--------------+------------+----------+-------+--------------+-----------------+----------------------------+
| daily_import | 10 0 * * * | UTC | 0 | td_sample_db | td_sample_table | {"in"=>{"type"=>"karte", ... |
+--------------+------------+----------+-------+--------------+-----------------+----------------------------+td connector:showは、スケジュールエントリの実行設定を表示します。
% td connector:show daily_import
Name : daily_import
Cron : 10 0 * * *
Timezone : UTC
Delay : 0
Database : td_sample_db
Table : td_sample_table
Config
---
in:
type: karte
bucket: sample_bucket
path_prefix: path/to/sample_
auth_method: json_key
json_keyfile:
content: |
{
"private_key_id": "1234567890",
"private_key": "-----BEGIN PRIVATE KEY-----\nABCDEF",
"client_email": "...",
"type": "service_account"
}
decoders:
- type: gzip
parser:
charset: UTF-8
...td connector:historyは、スケジュールエントリの実行履歴を表示します。個々の実行の結果を調査するには、td job jobidを使用します。
% td connector:history daily_import
+--------+---------+---------+--------------+-----------------+----------+---------------------------+----------+
| JobID | Status | Records | Database | Table | Priority | Started | Duration |
+--------+---------+---------+--------------+-----------------+----------+---------------------------+----------+
| 578066 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-18 00:10:05 +0000 | 160 |
| 577968 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-17 00:10:07 +0000 | 161 |
| 577914 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-16 00:10:03 +0000 | 152 |
| 577872 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-15 00:10:04 +0000 | 163 |
| 577810 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-14 00:10:04 +0000 | 164 |
| 577766 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-13 00:10:04 +0000 | 155 |
| 577710 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-12 00:10:05 +0000 | 156 |
| 577610 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-11 00:10:04 +0000 | 157 |
+--------+---------+---------+--------------+-----------------+----------+---------------------------+----------+
8 rows in settd connector:deleteは、スケジュールを削除します。
$ td connector:delete daily_importNFC は、この記事で説明されているように、ファイル名のエンコードと相互運用性の問題を軽減するために、ファイル名に必要なユニコード正規化形式のタイプです。そうでない場合、path_match_patternまたはpath_prefixと比較するときに一致エラーが発生する可能性があります。
seed.ymlのoutセクションでファイルインポートモードを指定できます。
これはデフォルトモードで、レコードがターゲットテーブルに追加されます。
in:
...
out:
mode: appendこのモードは、ターゲットテーブルのデータを置き換えます。ターゲットテーブルに対して手動で行われたスキーマ変更は、このモードでもそのまま保持されます。
in:
...
out:
mode: replace