Learn more about KARTE Import Integrationを参照してください。
Karteコネクタを使用して、Treasure Dataで実行したクエリのジョブ結果をGoogle Cloud Storageに書き込むことができます。
- Toolbeltを含むTreasure Dataの基本的な知識
- Google Cloud Platformアカウント
コネクタを作成する前に、以下の情報を収集する必要があります:Project IDとJSON Credentialです。
Google Cloud Storageとの統合は、サーバー間API認証に基づいています。Google Developer Consoleに移動し、左側のメニューのAPIs & authの下にあるCredentialsを選択します。次に、Service accountを選択します。
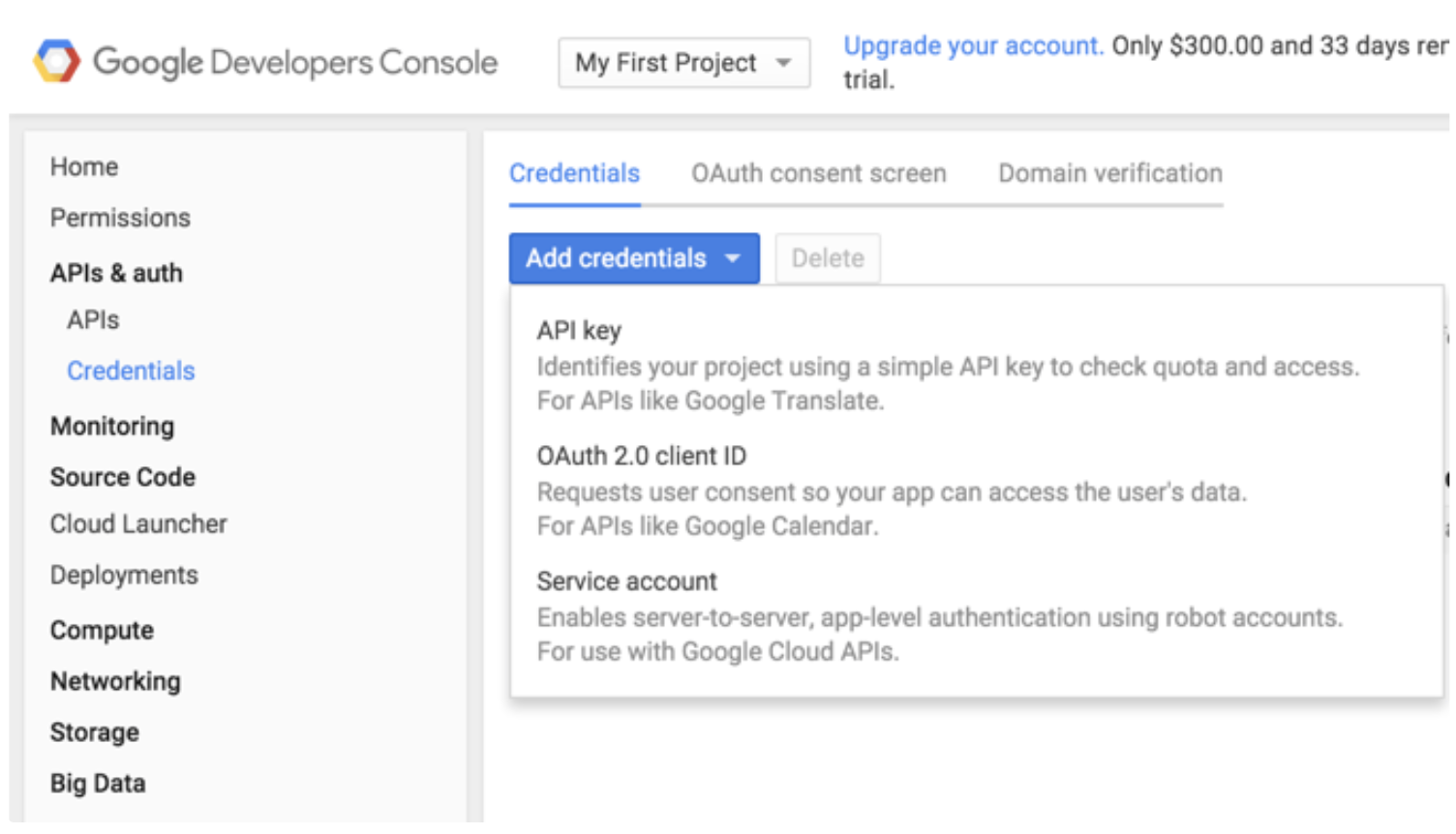
JSONベースのキータイプを選択してください。これはGoogleの推奨設定です。キーはブラウザによって自動的にダウンロードされます。
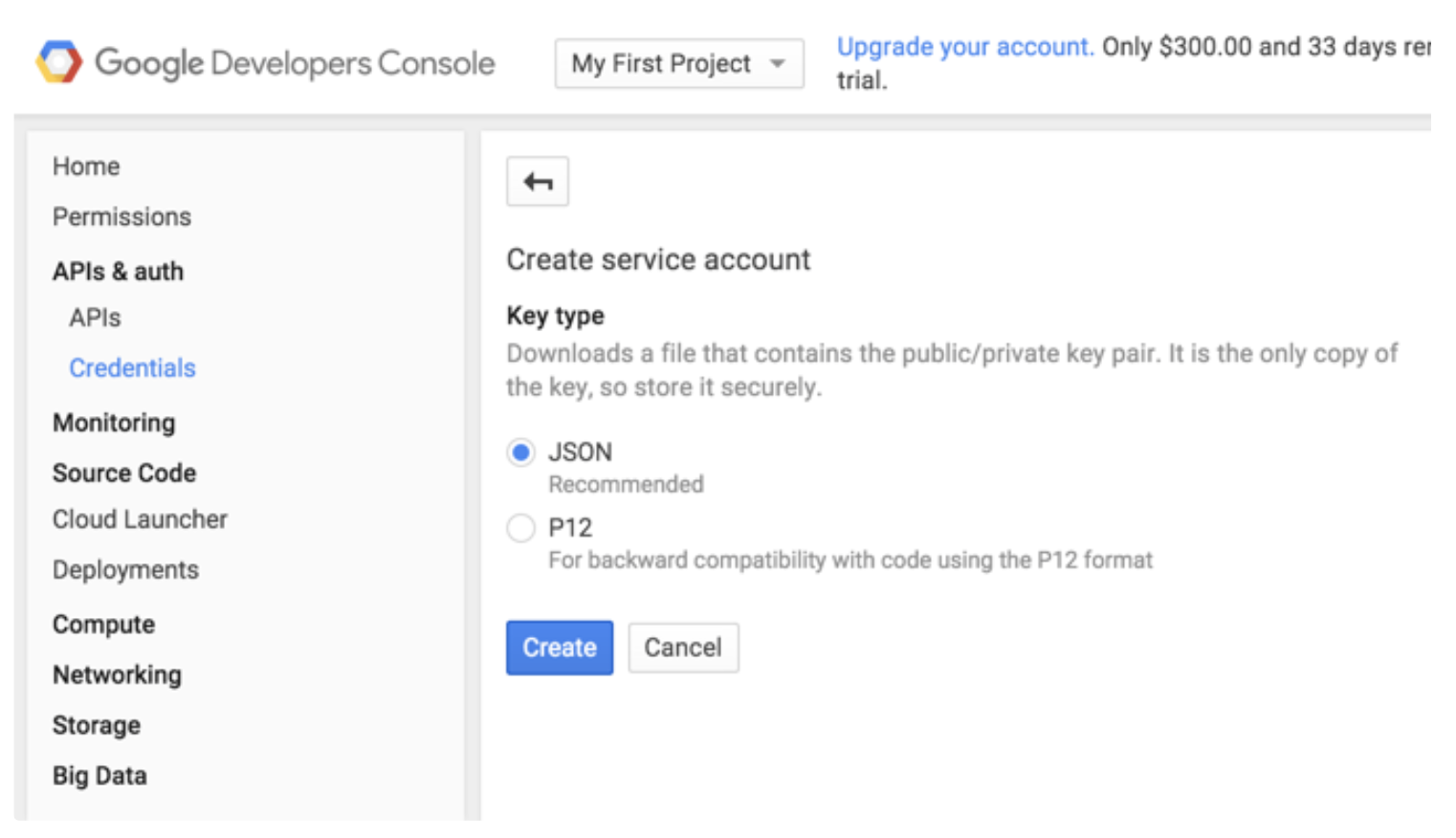
JSON Credentialsを生成したService Accountの所有者は、宛先バケットに対する書き込み権限を持っている必要があります。
Google Cloud Storageコンソールからバケットを作成します。
Treasure Data Consoleクエリエディタページに移動し、クエリをコンパイルします。
同じウィンドウで、Result ExportのCreate New Connectionを選択します。
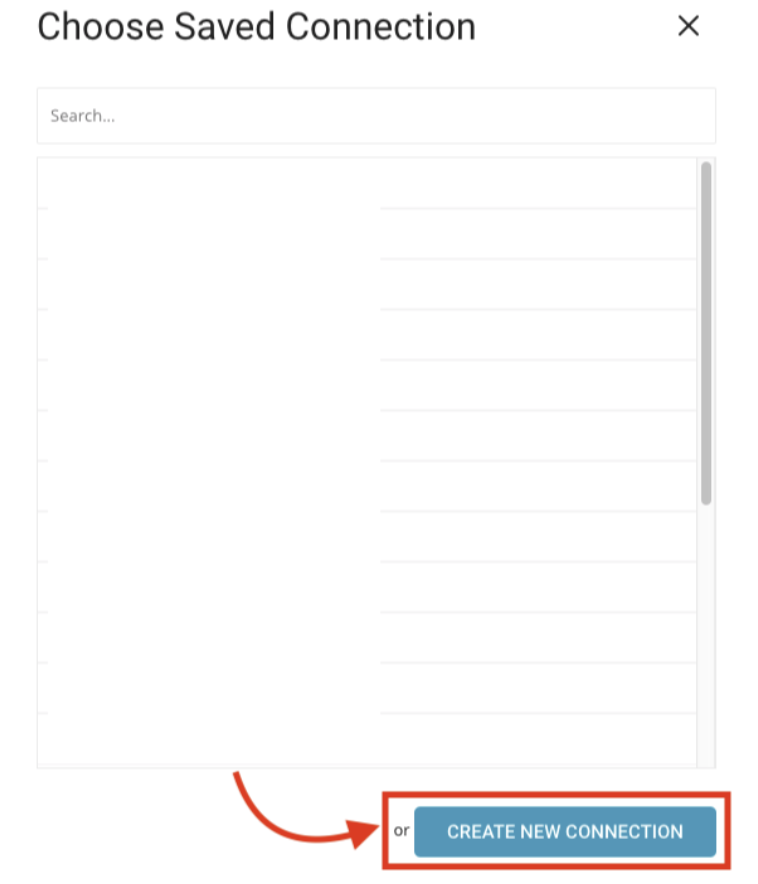
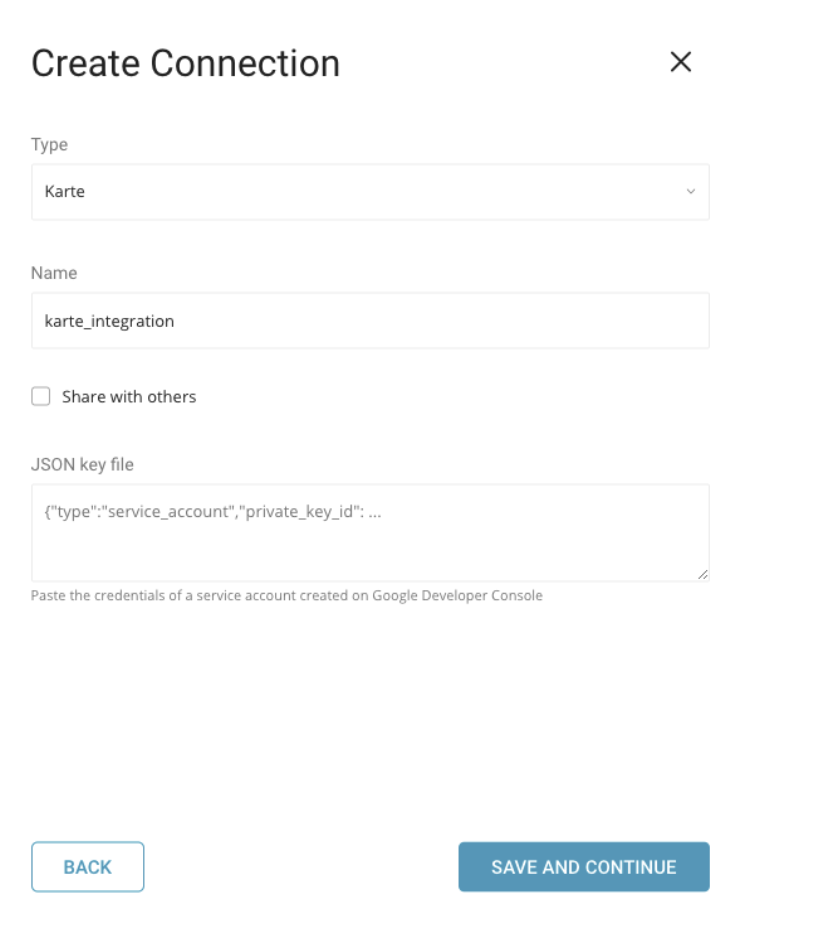
開いたダイアログで、接続タイプKARTEを検索して選択します。KARTE接続の名前を指定します。JSON Credential、Bucket name、Pathを含む情報を入力します:
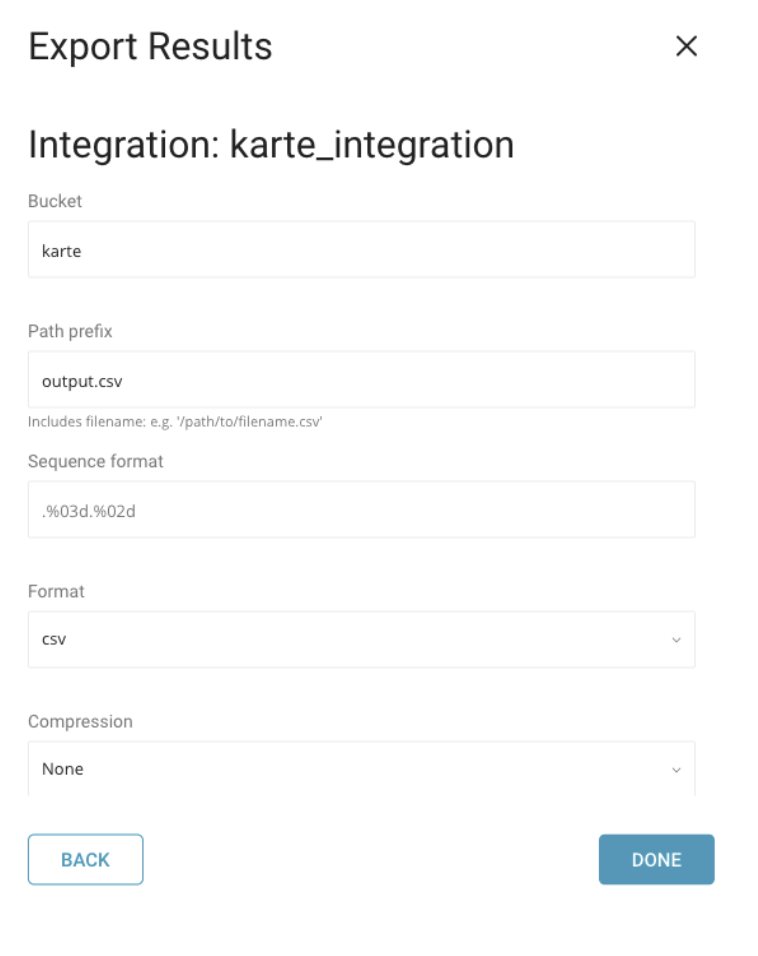
最後に、クエリに名前を付けて保存するか、単にクエリを実行します。クエリが正常に完了すると、結果は指定されたGoogle Cloud Storageの宛先に自動的に送信されます。
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
KARTEを使用してジョブ結果をGoogle Cloud Storageに送信するように、スケジュール済みクエリを設定できます。
json_keyを指定し、改行をバックスラッシュでエスケープします。
例
$ td sched:create scheduled_karte "10 6 * * *" \
-d dataconnector_db "SELECT id,account,purchase,comment,time FROM data_connectors" \
-r '{"type":"karte","bucket":"samplebucket","path_prefix":"/output/test.csv","format":"csv","compression":"","header_line":false,"delimiter":",","null_string":"","newline":"CRLF", "json_keyfile":"{\"private_key_id\": \"ABCDEFGHIJ\", \"private_key\": \"-----BEGIN PRIVATE KEY-----\\nABCDEFGHIJ\\ABCDEFGHIJ\\n-----END PRIVATE KEY-----\\n\", \"client_email\": \"ABCDEFGHIJ@developer.gserviceaccount.com\", \"client_id\": \"ABCDEFGHIJ.apps.googleusercontent.com\", \"type\": \"service_account\"}"}'Treasure Workflow内で、このデータコネクタを使用してデータを出力することを指定できます。
timezone: UTC
_export:
td:
database: sample_datasets
+td-result-into-target:
td>: queries/sample.sql
result_connection: karte_integration
result_settings:
bucket: your_bucket
path_prefix: dir/example.csv.gz
format: csv
compression: gz
newline: CR
....Treasure Data Workflowでデータコネクタを使用してデータをエクスポートする方法の詳細については、Exporting Data with Parametersを参照してください。
KARTEコネクタを設定する際に、以下のパラメータを使用できます。
| bucket | バケット名 |
|---|---|
| path_prefix | ファイルパス |
| format | "csv"または"tsv" |
| compression | ""または"gz"、"encryption_pgp" |
| public key | ファイルをアップロードする前に暗号化するために使用される公開鍵 |
| Key Identifier | ファイルを保護するために使用される暗号化サブキーのKey IDを指定します。マスターキーは暗号化プロセスから除外されます。 |
| Amor | ASCII armorを使用するかどうか |
| Compression Type | - ファイルを圧縮するために使用される圧縮アルゴリズムを定義します。ファイルはSFTPサーバーへのアップロードのために暗号化される前に圧縮されます。- 注意:ファイルは暗号化してアップロードする前に圧縮してください。復号化すると、ファイルは.gzや.bz2などの圧縮形式に戻ります。 |
| header_line | trueまたはfalse |
| delimiter | ","または"\t"または" |
| null_string | ""または"\N" |
| newline | "CRLF"または"CR"または"LF" |