Iterableは、完全なクロスチャネルカスタマーエンゲージメントプラットフォームです。電子メール、SMS、埋め込みメッセージ、アプリ内メッセージ、プッシュ通知、Webプッシュ通知を通じて顧客にメッセージを送信し、顧客基盤を拡大し、エンゲージメントを高め、ユーザーのライフタイムバリューを向上させることができます。
このインポート統合により、TDユーザーはIterableからキャンペーン、リスト、エクスポートデータをTreasure Dataに接続して取得できます。
- Treasure Dataの基本知識
- Iterable APIキー
- ユーザーリストの取得レート制限(5リクエスト/分)のため、1つのジョブですべてのリストを取得することはできません。ユーザーは各ジョブでインポートする単一のリストIDを指定する必要があります。
- IterableのEUインスタンスを使用している場合は、https://app.iterable.com/settings/apiKeysまたはhttps://app.eu.iterable.com/settings/apiKeysに移動します
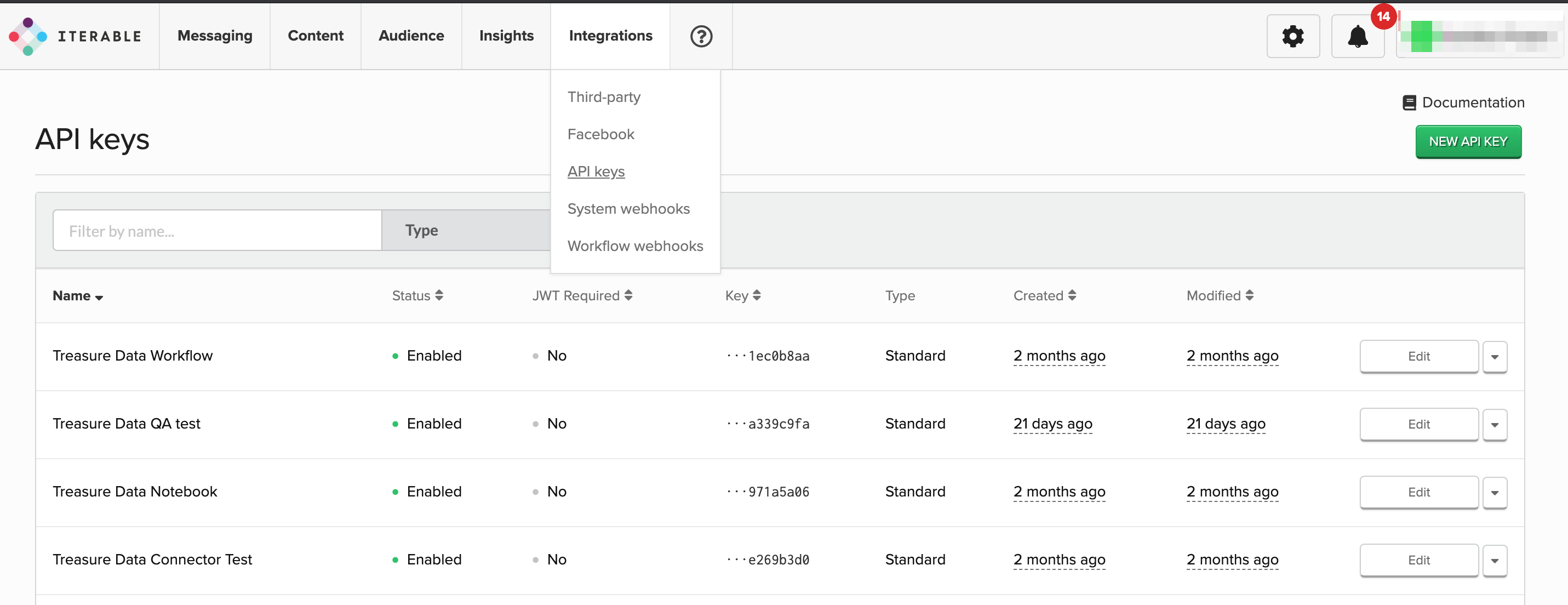
- New API KEYをクリックします
- **Standard (Server-side)**を選択します
- Treasure Dataから認証するためにAPIキーを使用できます。
Treasure Dataでは、クエリを実行する前にデータコネクションを作成して設定する必要があります。データコネクションの一部として、統合にアクセスするための認証を提供します。
- TD Consoleを開きます。
- Integrations Hub > Catalogに移動します。
- Iterableを検索して選択します。
- 次のダイアログが開きます。
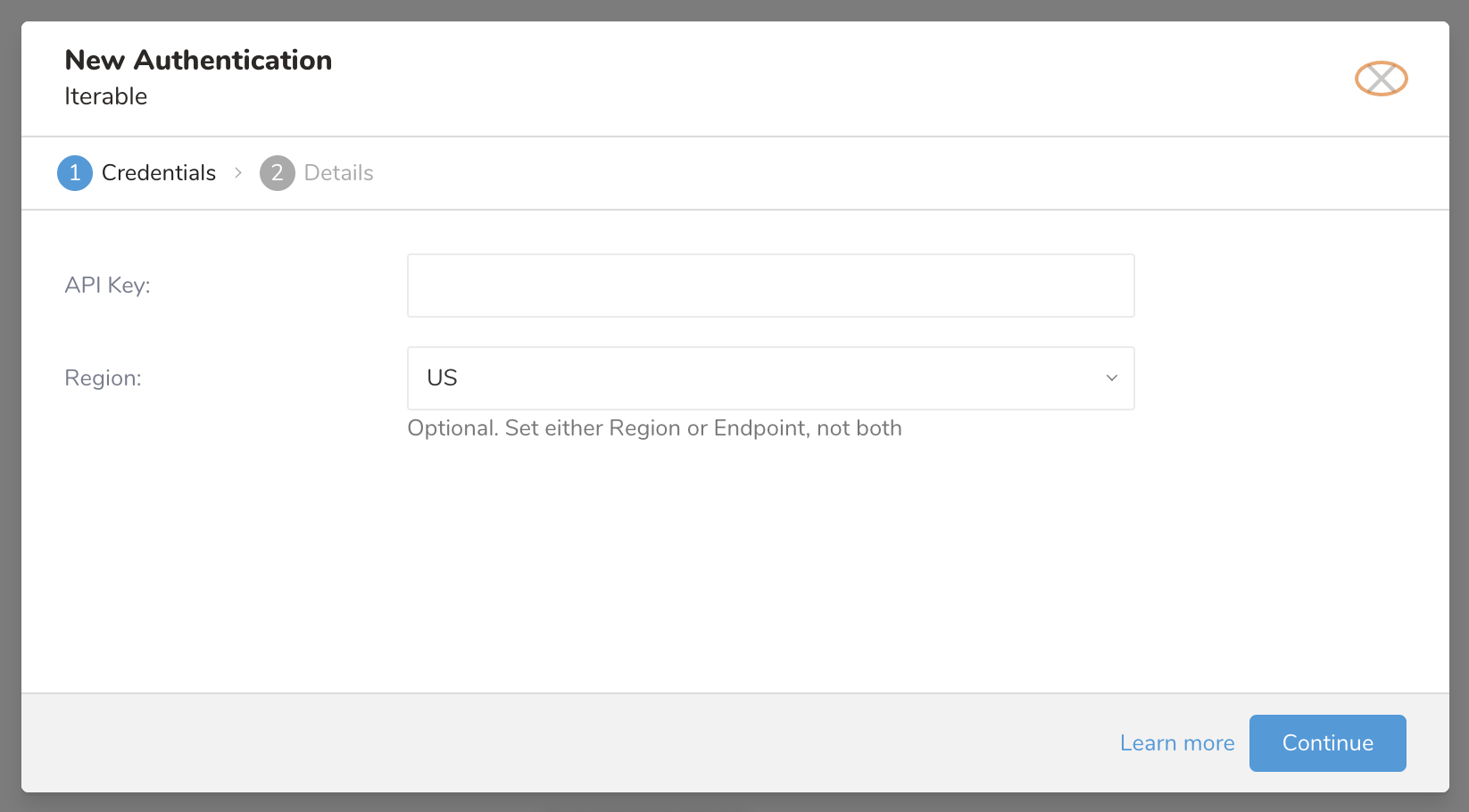
- APIキーを入力し、リージョンを選択します。
- コネクションの名前を入力します。
- Continueを選択します。
認証されたコネクションを作成すると、自動的にAuthentications画面に移動します。作成したコネクションを検索します。
- New Sourceを選択します。
- Data Transfer フィールドにSourceの名前を入力します。
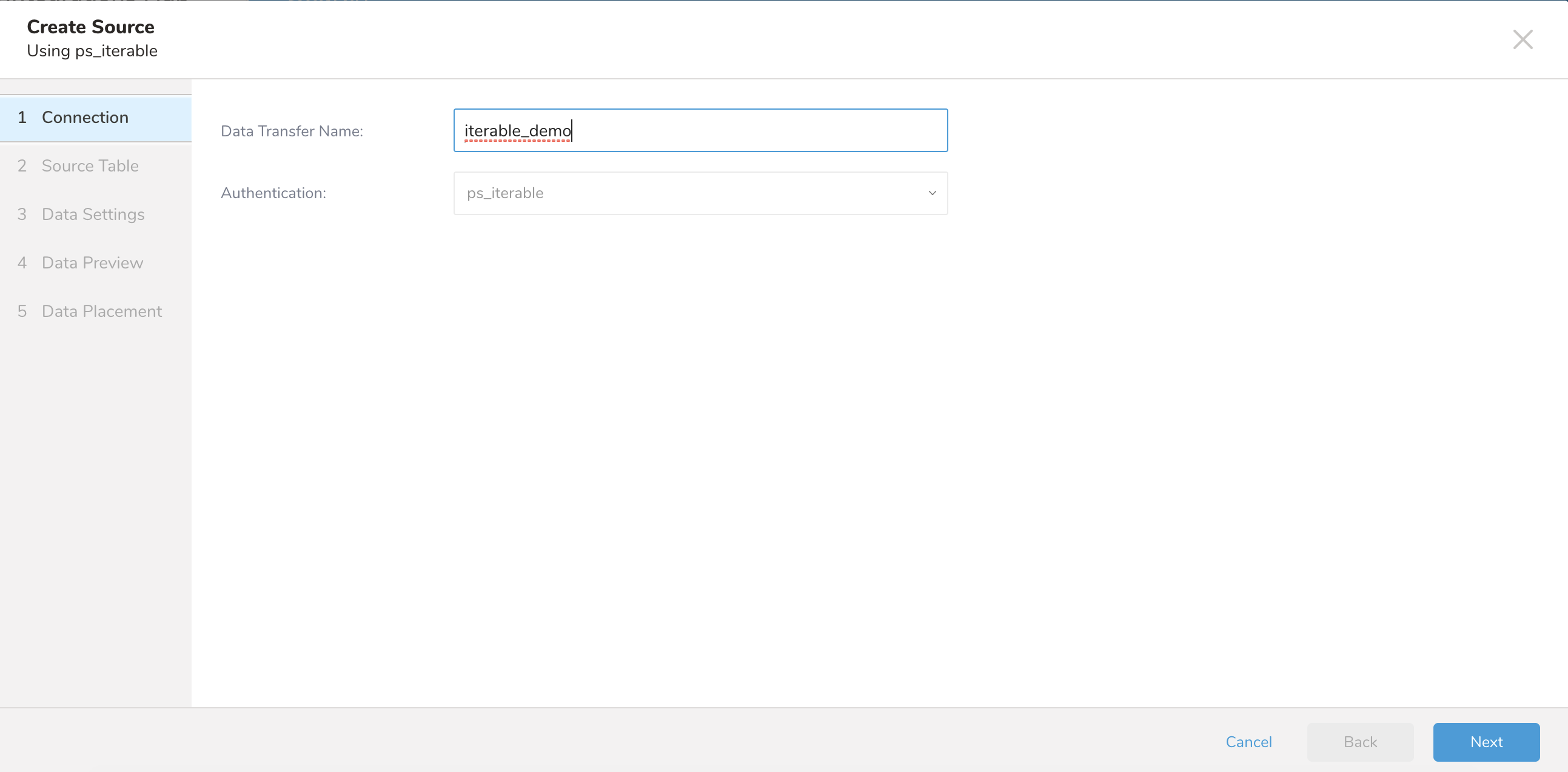
- Nextを選択します。 Source Tableダイアログが開きます。
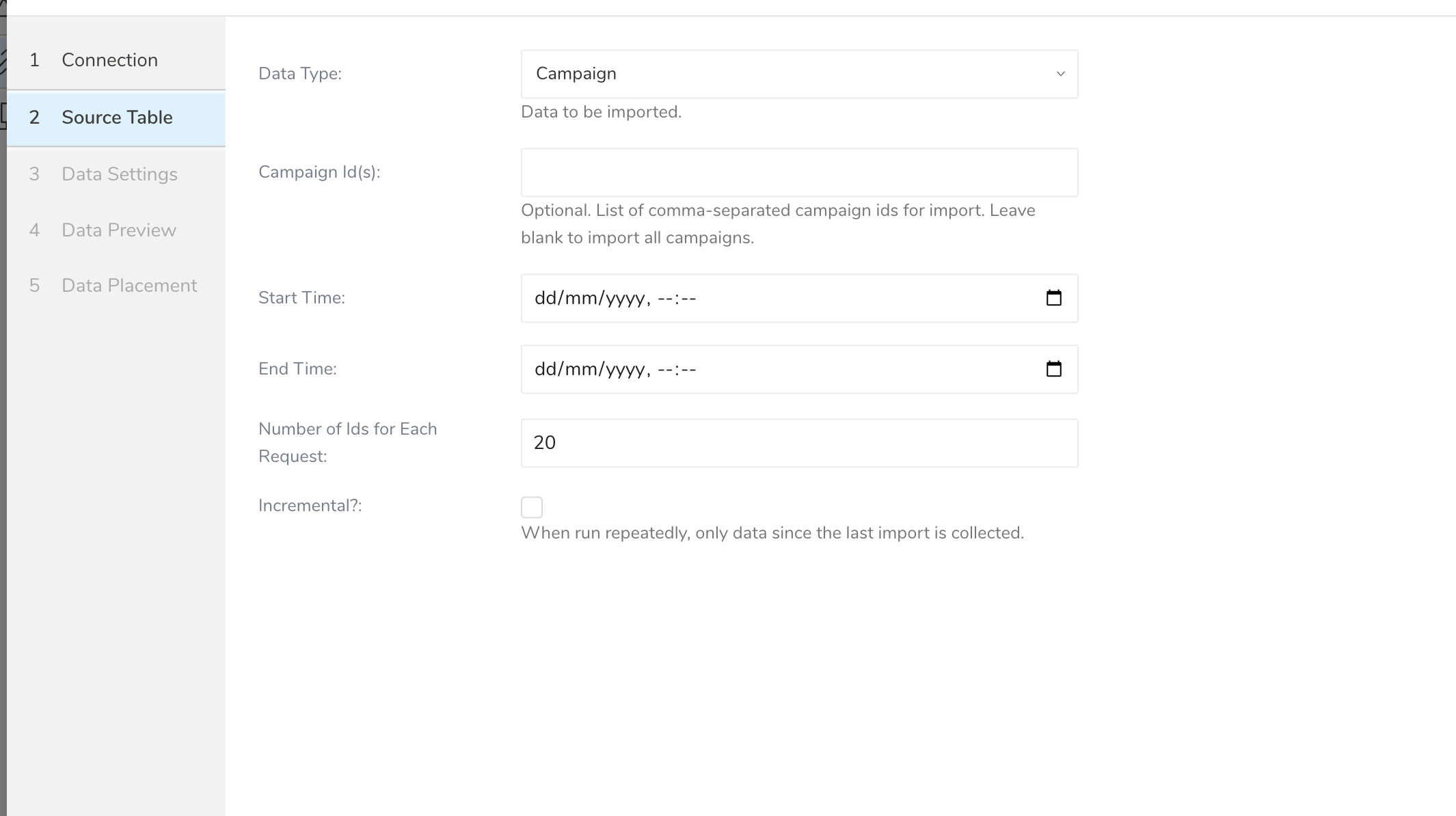
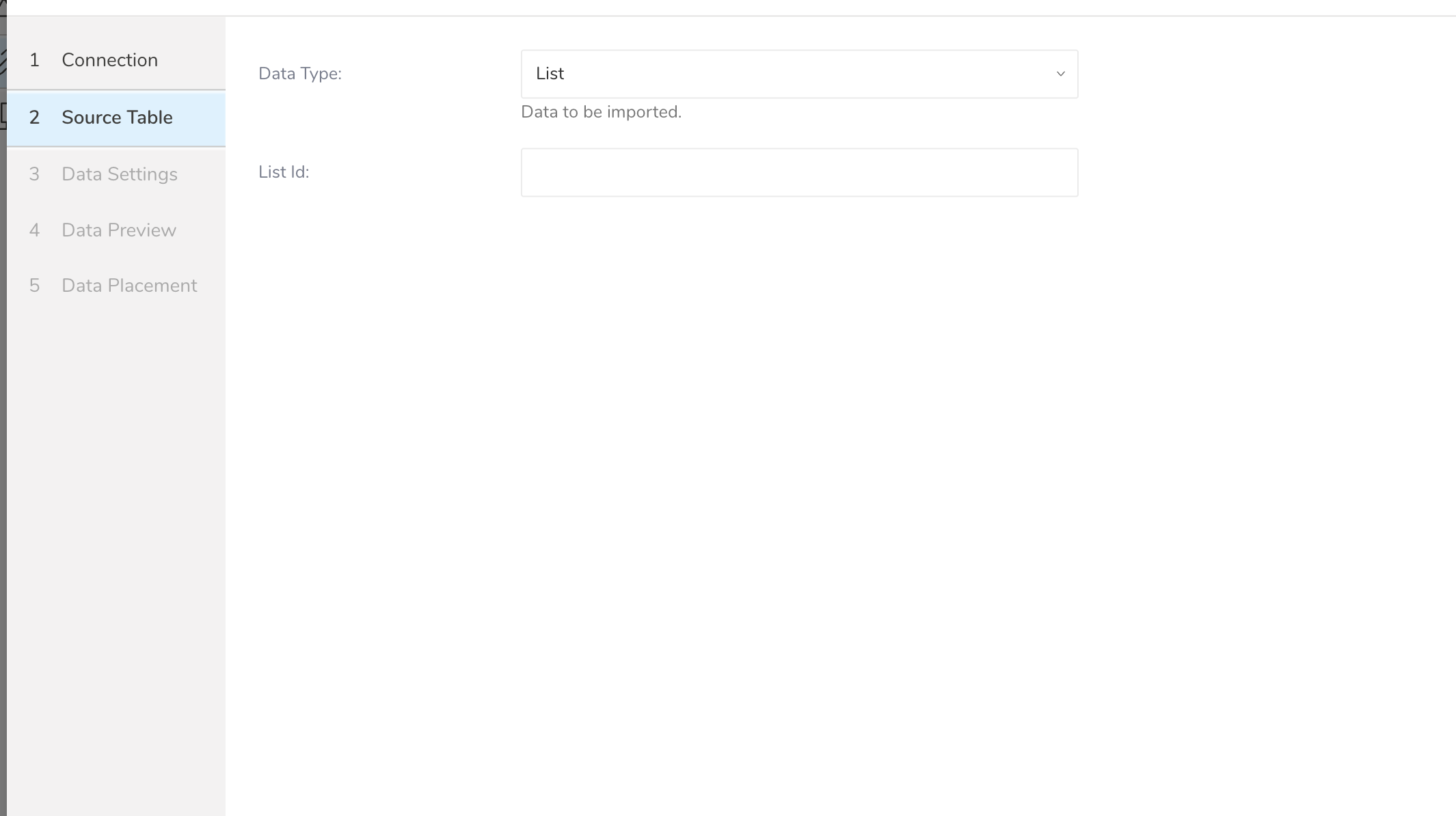
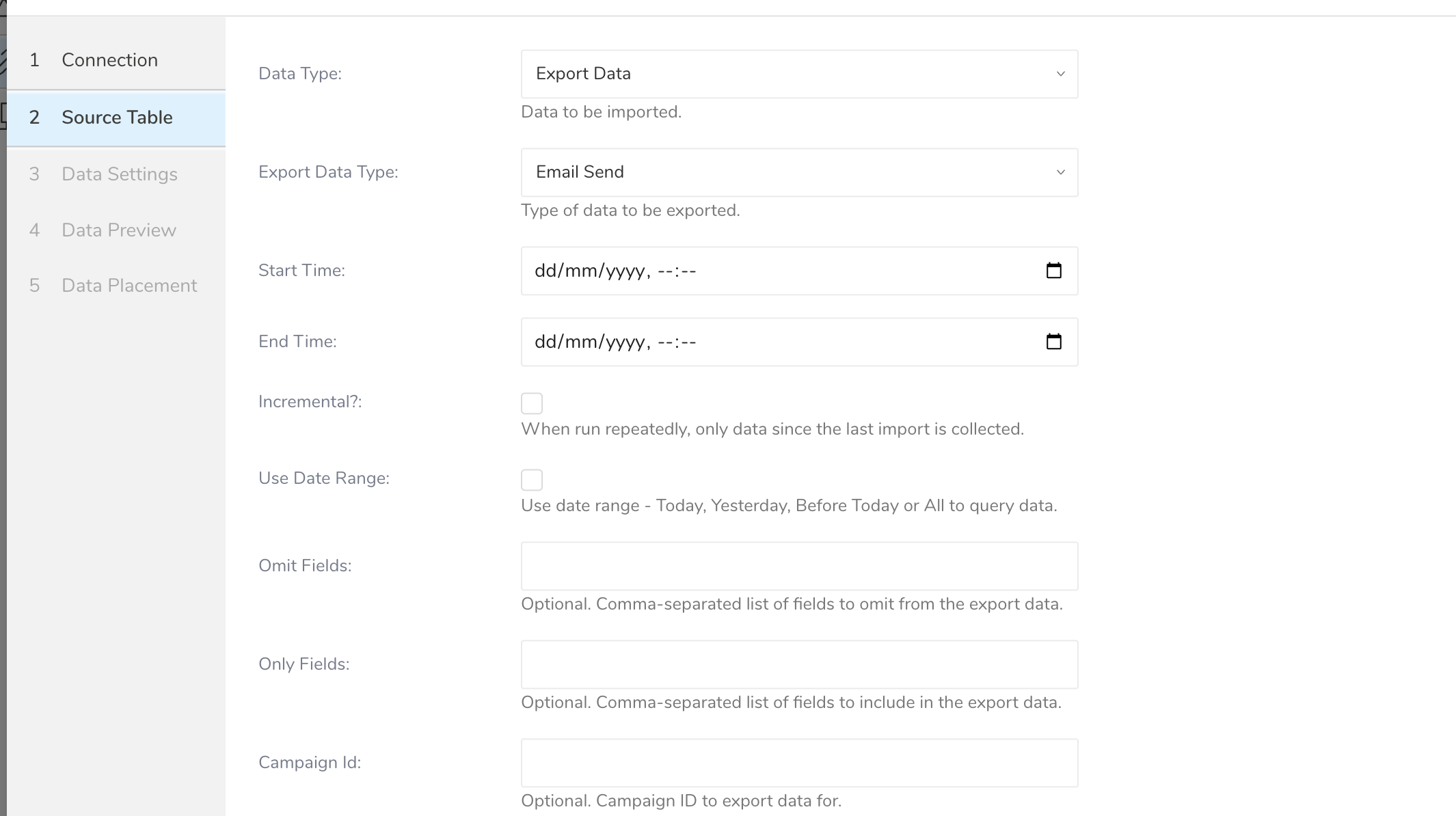
- 次のパラメータを編集します:
| パラメータ | 説明 | |
|---|---|---|
| Data Type | インポートするデータタイプ: - Campaign - List - Export Data | |
| Export Data Type | エクスポートするデータのタイプを指定します。Iterableでサポートされているタイプのいずれかと一致する必要があります。これらのデータタイプがサポートされています。 | |
| Canpaign id(s) | カンマで区切られたキャンペーンIDの配列。すべてのキャンペーンをインポートする場合は空白のままにしてください。 | |
| List id | それに属するすべてのユーザーを取得するためのリストID | |
| Start Time | UI設定の場合、サポートされているブラウザから日付と時刻を選択するか、ブラウザの日時形式に合った日付を入力できます。たとえば、Chromeでは年、月、日、時、分を選択するカレンダーが表示されます。Safariでは、2020-10-25T00:00のようなテキストを入力する必要があります。CLI設定の場合は、RFC3339 UTC"Zulu"形式のタイムスタンプが必要で、ナノ秒まで正確です。例:"2014-10-02T15:01:23" | |
| End Time | UI設定の場合、サポートされているブラウザから日付と時刻を選択するか、ブラウザの日時形式に合った日付を入力できます。たとえば、Chromeでは年、月、日、時、分を選択するカレンダーが表示されます。Safariでは、2020-10-25T00:00のようなテキストを入力する必要があります。CLI設定の場合は、RFC3339 UTC"Zulu"形式のタイムスタンプが必要で、ナノ秒まで正確です。例:"2014-10-02T15:01:23" | |
| Number of Ids for Each Request | 1つのリクエストあたりのIDの数。1から20まで | |
| Incremental | 前回の実行から新しいデータのみをインポートします。インクリメンタルローディングについてを参照してください。 | |
| Use Date Range | 日付範囲の使用を有効にします。 | |
| Date Range | 事前設定された日付範囲、例: - "Today", "Yesterday", "BeforeToday", "All" - 実際の日付を指定せずに素早くエクスポートするのに便利です。 | |
| Omit Fields (Optional) | エクスポートに含めるフィールド名の配列。存在する場合、これら以外のすべてのフィールドが返されます。カンマで区切ります。 | |
| Only Fields (Optional) | エクスポートから除外するフィールド名の配列。存在する場合、これらのフィールドのみが結果に表示されます。カンマで区切ります。 | |
| Campaign Id (Optional) | キャンペーン関連イベント(例:emailSend)をエクスポートする際に、特定のキャンペーンにデータをフィルタリングします。データの範囲を絞り込むのに便利です。 |
- データ設定を構成します。
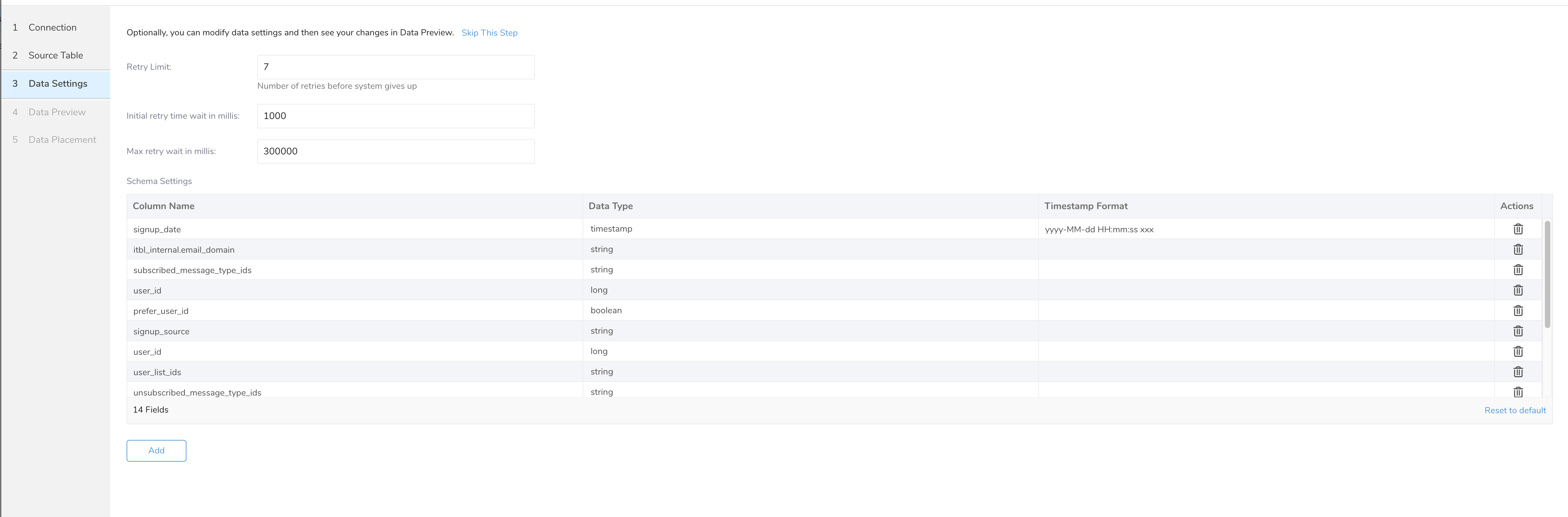
| パラメータ | 説明 |
|---|---|
| Retry Limit | インポートが失敗するまでの再試行回数。 |
| Initial retry time wait in millis | 再試行する前に待機する初期時間(ミリ秒)。 |
| Max retry wait in millis | 再試行する前に待機する最大時間(ミリ秒)。 |
| スキーマ設定 | スキーマはサンプルデータから推測されました。PREVIEWおよびRUNの前に、タイプとフォーマットを変更できます。 |
- 注意:
- JSONフィールドのトップレベル1のみをサポートします。JSONオブジェクトのキーと値のペアの解析はサポートしていません。
- データを取得するには、JSONフィールドを文字列からJSONデータ型に変更することを忘れないでください。通常、推測されたフィールドのデータ型は文字列です。
- 必要でない場合は、フィールド名を変更しないでください。
- カスタムクエリで何かを変更した後は、スキーマ設定をもう一度確認して編集する必要があります。
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示できます。Data preview はオプションであり、選択した場合はダイアログの次のページに安全にスキップできます。
- Next を選択します。Data Preview ページが開きます。
- データをプレビューする場合は、Generate Preview を選択します。
- データを確認します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
TD Consoleを使用して接続を設定できます。
最新のTD Toolbeltをインストールします。
設定ファイルには、Iterableからコネクタに入力される内容を指定するin-セクションと、コネクタからTreasure Dataのデータベースに出力される内容を指定するout-セクションが含まれます。
in:
api_key: xxxxxxxxxxxxxxxx
type: iterable
data_type: export_data
region: eu
export_data_type: user
use_date_range: false
incremental: true
start_time: '2024-01-01T08:51:00Z'
end_time: '2024-12-01T08:51:00Z'パラメータリファレンス
| 名前 | 説明 | 値 | デフォルト値 | 必須 |
|---|---|---|---|---|
| type | インポートのソース。 | "iterable" | はい | |
| api_key | Iterable UIで統合用に生成されたAPI Keyの文字列。 | 文字列 | はい | |
| region | api_keyを登録するリージョン。エンドポイントに応じて、ベースURLも変更されます。 | 文字列。 - us - eu | "us" | はい |
| data_type | インポートするデータタイプ: - campaign - list - export_data | 文字列。 | "campaign" | はい |
| export_data_type | エクスポートするデータのタイプを指定します。Iterableでサポートされているタイプのいずれかと一致する必要があります。サポートされるデータタイプはこちら。 | 文字列 | はい(data_typeがexport_dataの場合)。 | |
| campaign_ids | キャンペーンIDの配列をカンマで区切ります。すべてのキャンペーンをインポートする場合は空白のままにしてください。 | 文字列 | いいえ | |
| list_id | それに属するすべてのユーザーを取得するリストID | 文字列 | いいえ | |
| incremental | インクリメンタルローディングを有効にします。 | ブール値。 | False | いいえ |
| start_date | データのエクスポートを開始する開始タイムスタンプ | 文字列。フォーマット: yyyy-MM-dd'T'HH:mm:ss.SS'Z' | いいえ | |
| end_date | データのエクスポートを終了する終了タイムスタンプ | 文字列。フォーマット: yyyy-MM-dd'T'HH:mm:ss.SS'Z' | いいえ | |
| number_of_ids_for_each_request | 1リクエストあたりのID数。1から20まで。 | 整数 | 1 | いいえ |
| use_date_range | 日付範囲の使用を有効にします。 | ブール値 | False | はい |
| date_range | 事前設定された日付範囲、例: - "Today", "Yesterday", "BeforeToday", "All" - 実際の日付を指定せずにエクスポートするのに便利です。 | 文字列 サポートされる値: - today - yesterday - before_today - all | "Today" | いいえ |
| omit_fields | エクスポートに含めるフィールド名の配列。存在する場合、これら以外のすべてのフィールドが返されます。カンマで区切ります。 | 文字列 | いいえ | |
| only_fields | エクスポートから除外するフィールド名の配列。存在する場合、これらのフィールドのみが結果に表示されます。カンマで区切ります。 | 文字列 | いいえ | |
| campaign_id | キャンペーン関連イベント(例: emailSend)をエクスポートする際に、特定のキャンペーンにデータをフィルタリングします。データの範囲を絞り込むのに便利です。 | 文字列 | いいえ |
td connector:guess seed.yaml -o load.yaml in:
api_key: xxxxxxxxxxxxxxxxxx
type: iterable
data_type: export_data
region: eu
export_data_type: user
use_date_range: false
incremental: true
start_time: '2024-01-01T08:51:00Z'
end_time: '2024-12-01T08:51:00Z'
columns:
- {format: 'yyyy-MM-dd HH:mm:ss xxx', name: signup_date, type: timestamp}
- {name: itbl_internal.email_domain, type: string}
- {name: subscribed_message_type_ids, type: string}
- {name: user_id, type: long}
- {name: prefer_user_id, type: boolean}
- {name: signup_source, type: string}
- {name: user_id, type: long}
- {name: user_list_ids, type: string}
- {name: unsubscribed_message_type_ids, type: string}
- {name: itbl_user_id, type: string}
- {name: email, type: string}
- {name: merge_nested_objects, type: boolean}
- {format: 'yyyy-MM-dd HH:mm:ss xxx', name: profile_updated_at, type: timestamp}
- {name: unsubscribed_channel_ids, type: string}データを推測するには、td connector:guess コマンドを使用します。(まずguessを使用してスキーマを推測し、その後"columns"プロパティで期待通りにスキーマを変更する必要があります)。
td connector: previewコマンドを使用して、インポートされるデータをプレビューできます。
td connector:preview load.yamlカラム名やタイプが予期しないものとしてシステムが検出した場合は、load.yamlを直接変更して、再度プレビューします。
現在、Data Connectorは"boolean"、"long"、"double"、"string"、および"timestamp"タイプの解析をサポートしています。
Load Jobを送信します。データサイズによっては数時間かかる場合があります。ユーザーは、データが保存されるデータベースとテーブルを指定する必要があります。
td connector:issue load.yaml \
--database td_sample_db \
--table td_sample_table上記のコマンドは、すでにデータベース (td_sample_db) とテーブル (td_sample_table) を作成していることを前提としています。データベースまたはテーブルがTDに存在しない場合、このコマンドは成功しません。データベースとテーブルを手動で作成するか、コマンドのオプションを使用して自動作成することができます。
td connector:issue load.yaml --database td_sample_db --table td_sample_table --time-column created_at --auto-create-table定期的なIterableインポートのために、定期的なData Connector実行をスケジュールすることができます。高可用性を確保するためにスケジューラーを慎重に管理しています。この機能を使用することで、ローカルデータセンターでcronデーモンを使用する必要がなくなります。
新しいスケジュールは、td connector: createコマンドを使用して作成できます。スケジュールの名前、cron形式のスケジュール、データが保存されるデータベースとテーブル、およびData Connector設定ファイルが必要です。
cronパラメータは、@hourly、@daily、@monthlyのオプションを受け付けます。
デフォルトでは、スケジュールはUTCタイムゾーンで設定されます。-tまたは--timezoneオプションを使用して、タイムゾーンでスケジュールを設定できます。--timezoneオプションは、''Asia/Tokyo''、''America/Los Angeles''などの拡張タイムゾーン形式のみをサポートします。PSTやCSTなどのタイムゾーン略語は*サポートされておらず*、予期しないスケジュールになる可能性があります。
$ td connector:create \
daily_import \
"10 0 * * *" \
td_sample_db \
td_sample_table \
load.yaml- スケジュールの名前
- cron形式のスケジュール
- データが保存されるデータベースとテーブル
- Data Connector設定ファイルが必要です。TreasureDataのストレージは時間でパーティション分割されているため、--time-columnオプションを指定することも推奨されます。
td connector:create daily_import "10 0 * * *" \
td_sample_db td_sample_table load.yaml --time-column created_attd connector: listコマンドを入力すると、スケジュールされたエントリのリストを確認できます。
td connector:Listtd connector:showは、スケジュールエントリの実行設定を表示します。
$ td connector:show daily_iterable_import Name : daily_iterable_import Cron : 10 0 * * * Timezone : UTC Delay : 0 Database : sample_db Table : sample_tabletd connector:historyは、スケジュールエントリの実行履歴を表示します。各実行の結果を調査するには、td job:show jobidを使用します。
| 577914 | success | 20000 | sample_db | sample_table | 0 | 2015-04-16 00:10:03 +0000 | 152 | | 577872 | success | 20000 | sample_db | sample_table | 0 | 2015-04-15 00:10:04 +0000 | 163 | | 577810 | success | 20000 | sample_db | sample_table | 0 | 2015-04-14 00:10:04 +0000 | 164 | | 577766 | success | 20000 | sample_db | sample_table | 0 | 2015-04-13 00:10:04 +0000 | 155 | | 577710 | success | 20000 | sample_db | sample_table | 0 | 2015-04-12 00:10:05 +0000 | 156 | | 577610 | success | 20000 | sample_db | sample_table | 0 | 2015-04-11 00:10:04 +0000 | 157 | +--------+---------+---------+-----------+--------------+----------+---------------------------+----------+td connector:deleteは、スケジュールを削除します。
$ td connector:delete daily_iterable_import