Kafkaはリアルタイムデータストリーミングプラットフォームとして機能し、IT部門が様々なソースから膨大な量のデータを効率的に取り込み、処理、管理することを可能にします。TD CDPもリアルタイム機能を提供しています。しかし、KafkaとTD CDPを組み合わせることで、マーケターは既存の中央データストリーミングプラットフォームを活用し、リアルタイムの顧客行動に基づいてカスタマージャーニーを設計・実行できます。さらに、ITチームは異なるシステム、アプリケーション、データベース間でシームレスなデータ統合と同期を確保できます。これによりデータ管理プロセスが簡素化され、ITは顧客データの単一の信頼できる情報源を維持できるようになります。
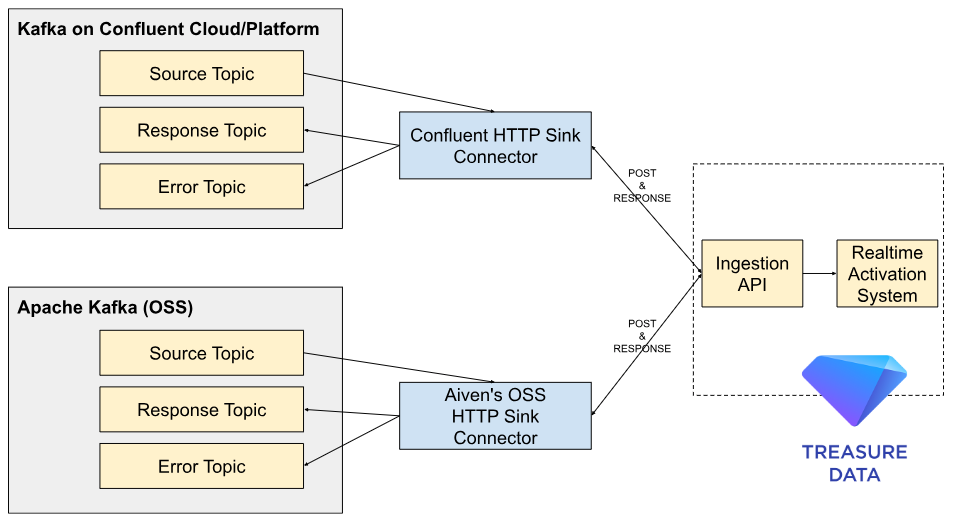
ConfluentはApache Kafkaを実行するためにConfluent Cloud(マネージドサービス)とConfluent Platform(オンプレミスサービス)を提供しています。これらのサービスはHTTPS経由でAPIとKafkaを統合するためのHTTP Sink Connectorを正式にサポートしています。例えば、このコネクタはKafkaから下流のREST APIへデータをプルするSink設定で利用できます。
Confluentサービスを使用していない場合でも、Apache KafkaはAivenのOSS HTTP Sink Connectorでこのアプローチをサポートできます。これらのコネクタを使用することで、Ingestion API経由でTreasure Dataにほぼリアルタイムでレコードをプッシュできます。
HTTP Sink connectorはKafkaトピックからレコードを消費し、各レコード値をAvro、JSONなどからrequest.body.format=jsonでJSONに変換してから、設定されたhttp.api.urlへのリクエストボディで送信します。このURLはオプションでレコードキーやトピック名を参照できます。
Ingestion APIは変換されたJSONレコードを取得するためのPOSTリクエストをサポートしています。コネクタは設定されたbatch.max.sizeまでレコードをバッチ処理してからAPIへバッチリクエストを送信します。各レコードはrequest.body.format=jsonでJSON表現に変換され、batch.separatorで区切られます。
以下は、Ingestion APIへPOSTリクエストを送信するための設定ファイルにおけるHTTP Sink Connectorの一般的なパラメータです。詳細については、Importing Table Records Using the Data Ingestion APIを参照してください。
単一のJSONリクエストのためにIngestion API用にレコードを変換するには、以下のパラメータを使用します。
- http.api.url: https://us01.records.in.treasuredata.com/DB/table
- request.method: POST
- http.authorization.type: none
- http.headers.content.type: application/vnd.treasuredata.v1.single+json
- http.headers.additional: "Authorization: TD1 TD WRITE API KEY"
- batch.max.size: 1
- request.body.format: json
- batch.json.as.array: false
高メッセージスループット環境の場合、リクエストごとに1つのJSONレコードに複数のレコードを取り込むことをお勧めします。このシナリオでは、Ingestion APIで複数レコードの取り込みをサポートするようにパラメータを変更します。
- http.api.url: https://us01.records.in.treasuredata.com/DB/table
- request.method: POST
- http.authorization.type: none
- http.headers.content.type: application/vnd.treasuredata.v1+json
- http.headers.additional: "Authorization: TD1 TD WRITE API KEY"
- batch.max.size: 2 (最大500)
- request.body.format: json
- batch.json.as.array: true
- Batch prefix: {"records":
- Batch suffix: }
- Batch separator: ,
KafkaとTreasure Data CDPを統合するための段階的なガイダンスについては、以下のチュートリアルを参照してください。
Confluent CloudはApache Kafkaをベースにしたマネージド型Kafkaサービスです。HTTP Sink Connectorを使用すると、Kafkaトピックからデータを取得し、外部HTTPエンドポイントとしてTreasure Dataに送信できます。このチュートリアルでは、Confluent CloudでHTTP Sink Connectorを設定する手順について説明します。
以下の手順は、最新のConfluence Cloudユーザーインターフェースとは異なる場合があります。
- Confluent Cloud有料アカウントとKafka Cluster
- Confluent Cloudの基本的な理解
- Kafkaクラスタ内のトピックにメッセージがあること
本番データがない場合は、このページでダミーデータをテストしてください。
- Connectorsセクションに移動します。
- New Connectorを選択して新しいコネクタを作成します。
- 利用可能なコネクタからHTTP Sinkを選択します。
HTTP SinkとHTTP Sink Connectorの2つのHTTP Sinkコネクタが見つかる場合があります。Confluent Cloudを使用する場合は、HTTP Sinkを選択してください。
- 要件に基づいてCredentials and Access権限を選択します。
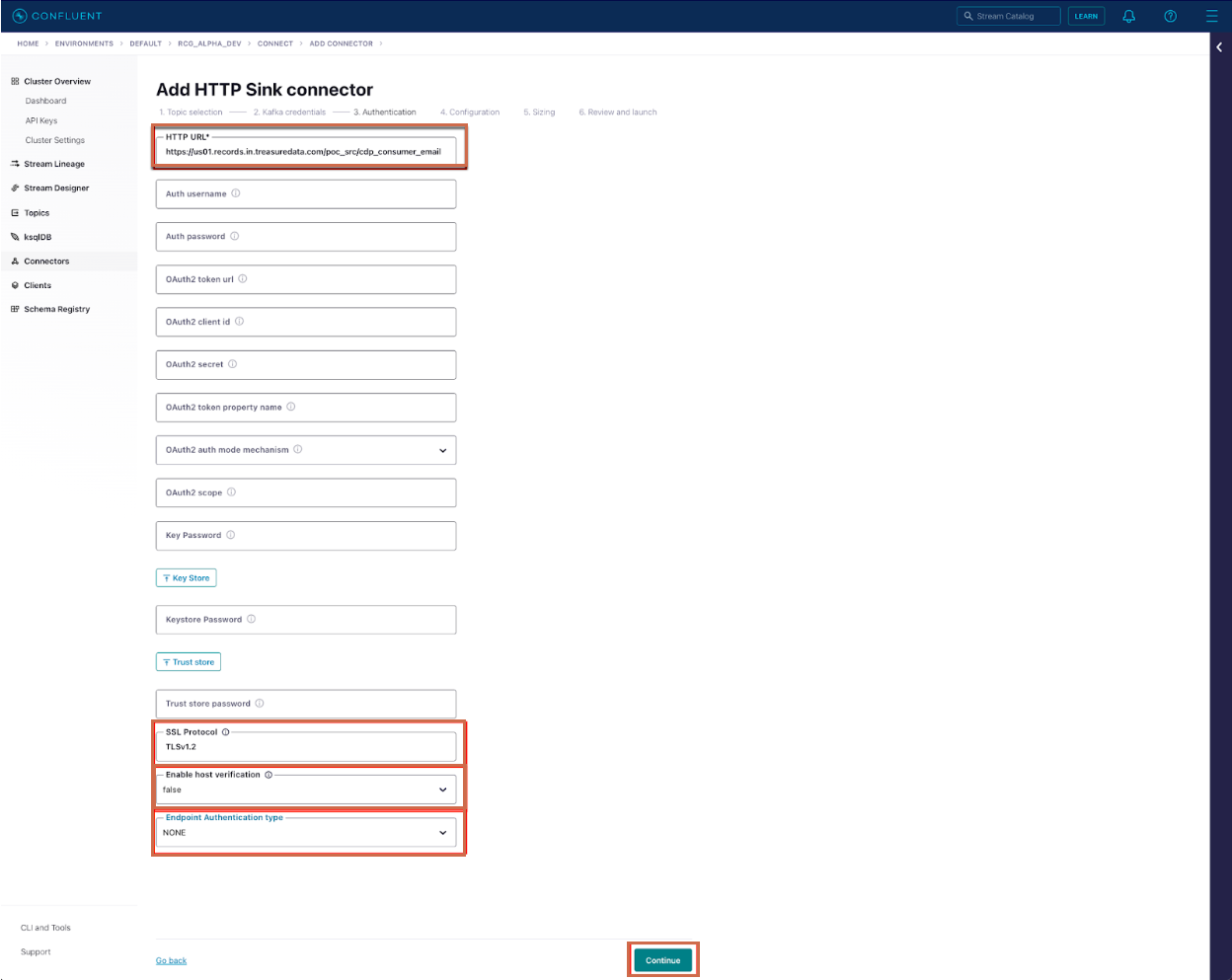
HTTP URL: 例
https://us01.records.in.treasuredata.com/support/kafka\_sampleフォーマットは
https://us01.records.in.treasuredata.com/DatabaseName/TableNameです詳細については、Importing Table Records Using the Data Ingestion APIを参照してください。
SSL Protocol: TLSv1.2
Enable Host verification: false
Endpoint Authentication Type: NONE
Master APIKEYを使用する場合、ユーザーIP ホワイトリストにConfluent clusterの静的IPアドレスを使用できます。
以下の情報は、Treasure Data Ingestion APIの単一レコード用です。さらに、Treasure Dataには複数レコード用のパラメータも含まれています。続行する前に、どのユースケースが適切かを判断してください。
- Input Kafka record value format:
- 現在のトピック設定に基づいて適切な形式を選択してください
- HTTP Request Method: POST
- HTTP Headers: Authorization: TD1 XXXX/xxxxx|Content-Type:application/vnd.treasuredata.v1.single+json
- TD1の後にTreasure Data API Keyを記述し、その後にスペースとTreasure Data API Key |Content-Type:application/vnd.treasuredata.v1.single+jsonを追加してください
- HTTP Headers Separator: |
- Behavior for null valued records: ignore
- Behavior on errors: fail
- 要件に応じて設定してください
- Report errors as: error_string
- Request Body Format: json
- Batch json as array: false
- Batch max size: 1
- Input Kafka record value format:
- 現在のトピック設定に基づいて適切な形式を選択してください
- HTTP Request Method: POST
- HTTP Headers: Authorization: TD1 XXXX/xxxxx|Content-Type:application/vnd.treasuredata.v1+json
- TD1の後にTreasure Data API Keyを記述し、その後にスペースとTreasure Data API Key |Content-Type:application/vnd.treasuredata.v1+jsonを追加してください
- HTTP Headers Separator: |
- Behavior for null valued records: ignore
- Behavior on errors: fail
- 要件に応じて設定してください
- Report errors as: error_string
- Request Body Format: json
- Batch json as array: true
- Batch max size: 500
- Batch prefix: {"records":
- Batch suffix: }
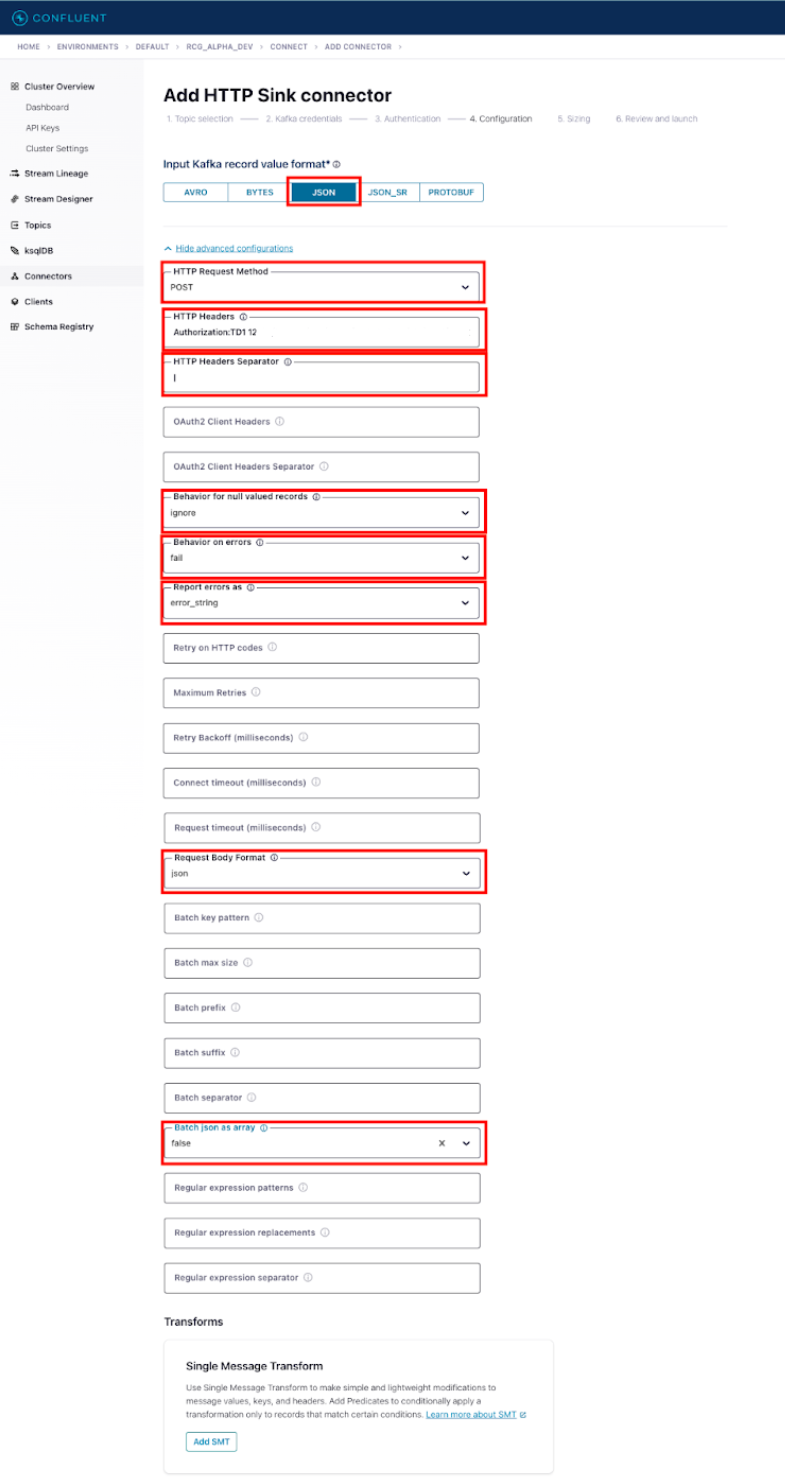
Continueを選択します。
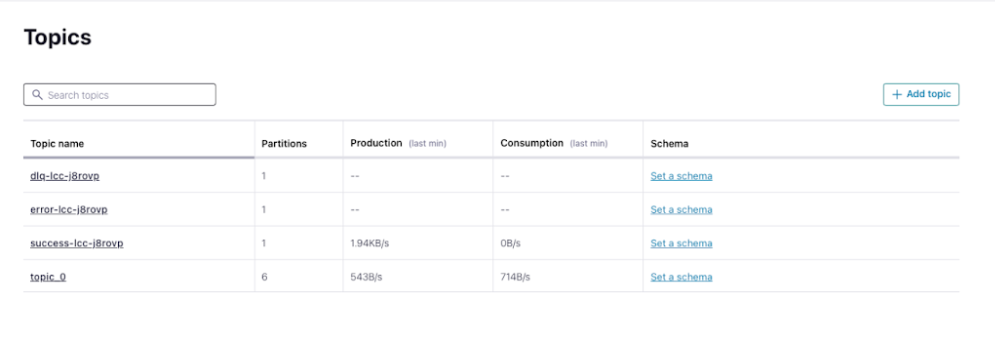
設定が完了すると、コネクタが自動的に起動します。トピックページで、success_nameで始まるレコードの数を確認してください。
Apache Kafkaはオープンソースの分散イベントストリーミングプラットフォームであり、Confluent PlatformはKafkaの商用ディストリビューションで、企業向けにデプロイメントと管理を簡素化する追加機能とツールを提供しています。自社の環境に適したプラットフォームを使用してください。両方のプラットフォームはHTTP Sink Connectorをサポートしており、Kafkaトピックからデータを取得し、外部のHTTPエンドポイントとしてTreasure Dataに送信することができます。このチュートリアルでは、Confluent PlatformおよびApache KafkaでHTTP Sink Connectorをセットアップする手順について説明します。
Confluent Platformの有料ライセンスまたはApache Kafkaクラスタ
Confluent PlatformではConfluentがサポートするHTTP Sink Connectorが必要です(リンク)
Apache KafkaではKafkaコミュニティが保守するAivenのHTTP Sink Connectorが必要です(リンク)
Treasure Dataはこれらのコネクタに対する商用サポートを提供していません。
- Apache Kafkaの基本的な理解
Kafka Connectがインストールされていることを確認してください。このフレームワークは外部システムをKafkaに接続します。Confluent Platformを使用している場合、Kafka Connectはプリインストールされています。それ以外の場合は、別途ダウンロードしてインストールする必要があります。
- Apache Kafka Connect https://kafka.apache.org/documentation/#connect
- Confluent Kafka Connect: https://docs.confluent.io/platform/current/connect/index.html
HTTPエンドポイントにデータを送信するには、HTTP Sink Connectorプラグインが必要です。お使いのKafka Connectバージョンと互換性のある特定のプラグインバージョンについては、Confluent Hubまたは他のソースを確認してください。その後、ダウンロードしたHTTP Sink Connectorプラグイン(JARファイル)を適切なKafka Connectプラグインディレクトリに配置します。
- Confluent Platform用にConfluent Hub経由でダウンロード: https://docs.confluent.io/kafka-connectors/http/current/overview.html
- Apache Kafka用にGithub経由でダウンロード: https://github.com/Aiven-Open/http-connector-for-apache-kafka
HTTP Sink Connectorの設定を定義するための設定ファイル(JSONまたはproperties形式)を作成します。この設定ファイルには通常、以下のプロパティが含まれます:
- name: コネクタの一意の名前
- connector.class: HTTP Sink Connectorのクラス名(例:io.confluent.connect.http.HttpSinkConnector)
- tasks.max: コネクタに対して作成されるタスクの数(通常はKafkaパーティション数と同じ)
- topics: データが消費され、HTTPエンドポイントに送信されるKafkaトピック
- http.api.url: データが送信されるHTTPエンドポイントのURL
- http.api.method: リクエストを行う際に使用するHTTPメソッド(例:POST、PUTなど)
- http.headers: リクエストに含める追加のHTTPヘッダー
- http.timeout.ms: HTTPリクエストのタイムアウト
その他、使用ケースや要件に応じたオプションプロパティ。
これらの設定プロパティは、使用するKafka ConnectとHTTP Sink Connectorプラグインの特定のバージョンによって異なる場合があります。最新の情報と手順については、常に公式ドキュメントとプラグインのドキュメントを参照してください。
- Confluent Platform: https://docs.confluent.io/kafka-connectors/http/current/connector_config.html
- Apache Kafka https://github.com/Aiven-Open/http-connector-for-apache-kafka/blob/main/docs/sink-connector-config-options.rst
HTTP Sink Connectorの設定を定義するための設定JSONファイルを作成します。https://docs.confluent.io/kafka-connectors/http/current/connector_config.html#http-sink-connector-configuration-propertiesのコネクタガイドラインに従ってください。
{
"name": "tdsinglejsonHttpSink",
"config":
{
"topics": "rest-messages5",
"connector.class": "io.confluent.connect.http.HttpSinkConnector",
"http.api.url": "https://us01.records.in.treasuredata.com/database_name/table_name",
"request.method": "POST",
"headers": "Authorization:TD1 XXXXX/xxxxx|Content-Type:application/vnd.treasuredata.v1.single+json",
"header.separator": "|",
"report.errors.as": "error_string",
"request.body.format": "json",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter.schemas.enable": "false",
"batch.prefix":"",
"batch.suffix":"",
"batch.max.size": "1",
"batch.json.as.array": "false",
"tasks.max": "1",
"confluent.topic.bootstrap.servers": "localhost:9092",
"confluent.topic.replication.factor": "1",
"reporter.bootstrap.servers": "localhost:9092",
"reporter.result.topic.name": "success-responses",
"reporter.result.topic.replication.factor": "1",
"reporter.error.topic.name": "error-responses",
"reporter.error.topic.replication.factor": "1",
"ssl.enabled":"true",
"https.ssl.protocol":"TLSv1.2"
}
}{
"name": "tdBatchHttpSink",
"config":
{
"topics": "rest-messages5",
"connector.class": "io.confluent.connect.http.HttpSinkConnector",
"http.api.url": "https://us01.records.in.treasuredata.com/DB/TBL",
"request.method": "POST",
"headers": "Authorization:TD1 XXXX/xxxx|Content-Type:application/vnd.treasuredata.v1+json",
"header.separator": "|",
"report.errors.as": "error_string",
"request.body.format": "string",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": "false",
"value.converter.schemas.enable": "false",
"batch.prefix":"{\"records\":",
"batch.suffix":"}",
"batch.max.size": "500",
"batch.json.as.array": "true",
"tasks.max": "1",
"confluent.topic.bootstrap.servers": "localhost:9092",
"confluent.topic.replication.factor": "1",
"reporter.bootstrap.servers": "localhost:9092",
"reporter.result.topic.name": "success-responses",
"reporter.result.topic.replication.factor": "1",
"reporter.error.topic.name": "error-responses",
"reporter.error.topic.replication.factor": "1",
"ssl.enabled":"true",
"https.ssl.protocol":"TLSv1.2"
}
}HTTP Sink Connectorの設定を定義するための設定JSONファイルを作成します。コネクタのガイドラインについては、https://github.com/Aiven-Open/http-connector-for-apache-kafka/blob/main/docs/sink-connector-config-options.rstを参照してください。Confluent HTTP Sink Connectorがサポートしていたものと同様のパラメータをサポートしています。
{
"name": "tdCommunityHttpSink",
"config":
{
"topics.regex": "td-rest-messages1",
"connector.class": "io.aiven.kafka.connect.http.HttpSinkConnector",
"http.url": "https://us01.records.in.treasuredata.com/database_name/table_name",
"http.authorization.type": "none",
"http.headers.content.type": "application/vnd.treasuredata.v1.single+json",
"http.headers.additional": "Authorization: TD1 XXXX/xxxx",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter.schemas.enable": "false",
"batching.enabled": "false",
"batch.max.size": "1",
"batch.prefix":"{\"records\":[",
"batch.suffix":"]}",
"batch.separator": "n",
"tasks.max": "1"
}
}設定をKafka Connectに送信してHTTP Sink Connectorを起動します。confluentコマンドラインツールを使用するか、Kafka Connect REST APIへREST API呼び出しを行うことができます。詳細については、KAFKA CONNECT 101を参照してください。