Treasure Dataのジョブ結果をAirshipのオーディエンスリストに直接書き込むことができます。Airshipでは、これらのリストを使用して特定のユーザーをターゲットにすることができます。
- Treasure Dataの基本知識
- Airship、Airshipオーディエンスリスト、属性、カスタムイベントの基本知識
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
- 最大1,000万レコードまでアップロードできます。
- 最大100個のアップロードリストを作成できます。
- APIの制限により、リストのコンテンツを上書きすることはできますが、リストに追加することはできません。
Treasure Dataでは、クエリを実行する前にデータ接続を作成および設定する必要があります。データ接続の一部として、インテグレーションにアクセスするための認証情報を提供します。
- TD Consoleを開きます。
- Integrations Hub > Catalogに移動します。
- Catalog画面の右端にある検索アイコンをクリックし、Airshipと入力します。
- AirShipコネクタにカーソルを合わせ、Create Authenticationを選択します。
New Authenticationダイアログが開きます。
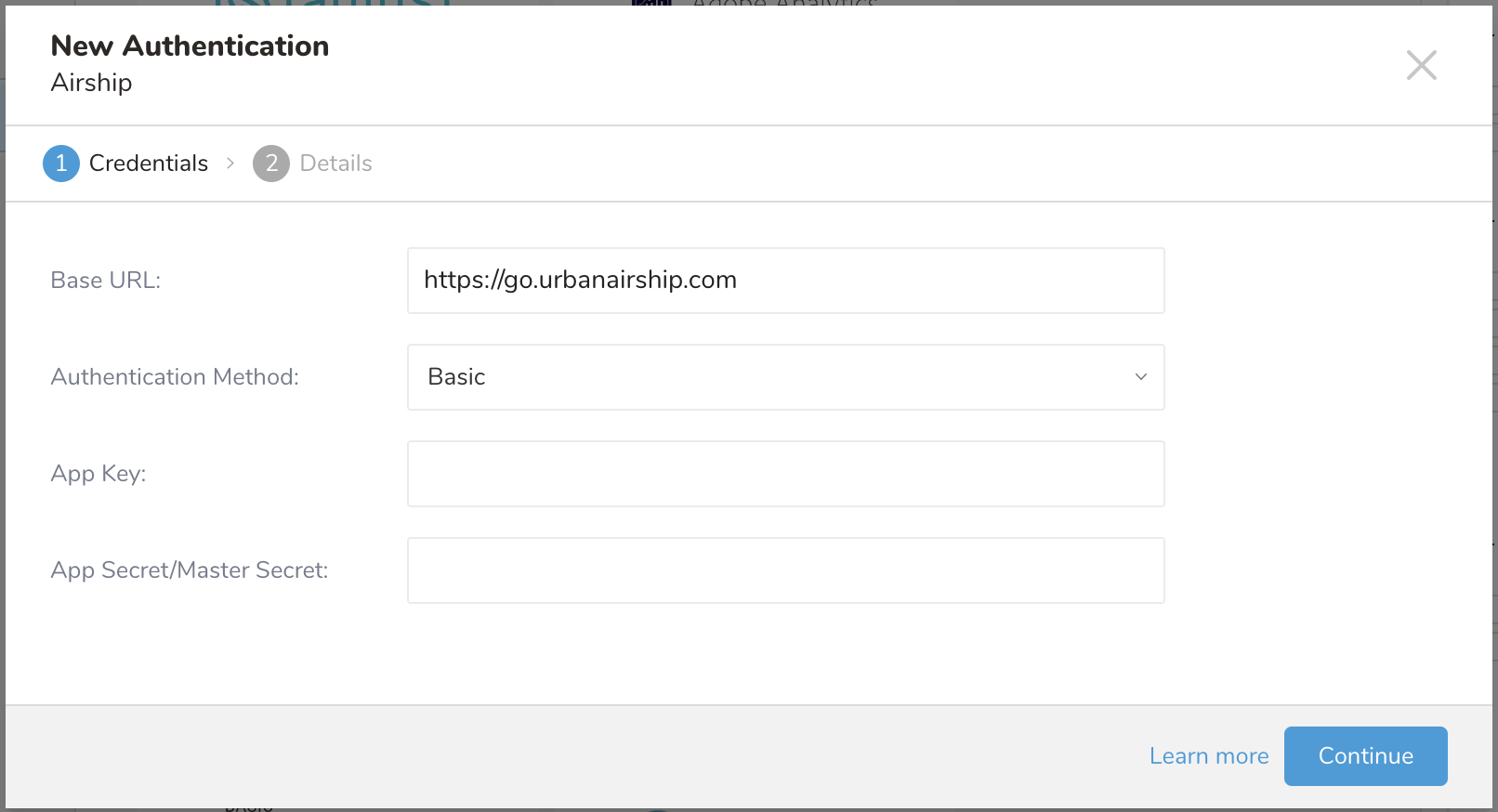 5. Base URLを入力します:
5. Base URLを入力します:
- Airship North Americanクラウドサイト: https://go.urbanairship.com
- Airship Europeanクラウドサイト: https://go.airship.eu
- 次のいずれかの認証方法を選択します
- In the Airship project dashboard, select Settings > APIs & Integrations.
- Enter the App key, App secret, and App master secret.

- 認証情報を入力します。カスタムイベントアップロードの認証の場合は、App keyを使用したアクセストークン方式が必要です。App key、App secret、tokenの取得方法については、以下を参照してください。
- 接続の名前を入力します。
- Continueを選択します。
このインテグレーションは、ユーザーがAirshipにさまざまなタイプのデータを同期することをサポートします。
| Configurations | Options | Description |
|---|---|---|
| Data Type | Static List | Airship Audience Listsに静的リストをアップロードします(ターゲットが存在しない場合は、静的リストが自動的に作成されます) |
| Non-JSON Attributes | Airshipのテキスト、数値、日時属性に値を同期します。 | |
| JSON Attributes | Airshipのjson属性に値を同期します | |
| Custom Events | Airshipにカスタムイベントを同期します |
インテグレーションを設定するには:
- TD Consoleを開きます。
- Data Workbench > Queriesに移動します。
- New Queryをクリックして新しいクエリを作成するか、データのエクスポートに使用する予定の保存されたクエリを検索します。
- クエリエディタの上部にあるExport Resultsを選択します。
以下のサンプルクエリを参照して、ユーザーとチャネルのリストをAirshipオーディエンスリストにアップロードするエクスポートジョブの設定方法を確認してください。
| Parameter | Description |
|---|---|
| Data Type | Static list |
| List Name (required) | Audience listの名前 |
| Description (optional) | Audience listの説明 |
| Skip Empty Records (optional) | デフォルトはTrueです。クエリ結果に空またはnullの列が含まれている場合、その行はスキップされます。それ以外の場合、ジョブは失敗し、空のレコードを手動で削除する必要があります。 |
サンプルクエリ
SELECT identifier_type, identifier FROM table my_tableサンプルクエリ結果
identifier_type, identifiernamed_user,customer-42named_user,room-27ios_channel,5i4c91s5-9tg2-k5zc-m592150z5634web_channel,d132f5b7-abcf-4920-aeb3-9132ddac3d5aandroid_channel,52b2b587-0152-4134-a8a0-38ae6933c88aemail_channel,ab1a81e3-5af3-4c04-a7ae-d676960e6684open_channel,6bcf3e63-a38a-44d8-8b0d-2fb5941e74absms_channel,ab1a81e3-aaf3-ac04-a7ae-a676960e6684以下のサンプルクエリを参照して、テキスト、数値、または日時属性の値をAirshipオーディエンスリストに同期する方法を確認してください。
| Parameter | Description |
|---|---|
| Data Type | Non-JSON attributes |
| Target | Named UsersまたはChannelのいずれかを選択します。 |
| Action | - Batch CSV upload -- Treasure Dataは、大量のレコードに対してBatch CSV uploadを推奨します。このモードは、カスタム属性の値の追加と更新にのみ使用されます。 - SetまたはRemove -- これらのオプションは、レコードごとに1回のアップロード呼び出しを使用します。これにより、Airship上でのデータの伝播が高速化されますが、全体的な実行時間は遅くなります。 |
| Skip Empty Records (optional) | デフォルトはTrueです。クエリ結果に空またはnullの列が含まれている場合、その行はスキップされます。それ以外の場合、ジョブは失敗し、空のレコードを手動で削除する必要があります。 |
Named Usersのサンプルクエリ
この例では、fav_colorとfav_sportはAirship上で属性キーとして定義されている必要があります。
SELECT n.named_user AS named_user, a.fav_color as fav_color, a.fav_sport as fav_sportFROM named_users n JOIN attributes a ON n.id = a.idサンプルクエリ結果
named_user, fav_color, fav_sportcustomer-42, red, footballcustomer-22, black, tennisChannelsのサンプルクエリ
この例では:
- fav_color、fav_sportはAirship上で属性キーとして定義されている必要があります。
- Identifier_typeは次のいずれかを指定します: amazon_channel、android_channel、channel、email_address、ios_channel、sms_id、web_channel
- identifier_typeがsms_idの場合、追加情報が必要なため、sender列が必要です。(それ以外の場合、そのレコードは無効です。)
- Identifer_valueはそのチャンネルのIDを指定します
SELECT c.channel_id AS identifier_value, 'email_address' AS identifier_type, a.fav_color as fav_color, a.fav_sport as fav_sportFROM channels c JOIN attributes a ON c.id = a.idサンプルクエリ結果
identifier_type, identifier_value, fav_color, fav_sportemail_address, customer11@email.com, red, footballemail_address, customer21@email.com, black, footballAirshipオーディエンスリストにJSON属性を同期する方法については、以下のサンプルクエリを参照してください。
| パラメータ | 説明 |
|---|---|
| Data Type | JSON Attributes |
| Target | Named UsersまたはChannelのいずれかを選択 |
| Action | - SetまたはRemove -- これらのオプションは、レコードごとに単一のアップロードコールを使用します。これにより、Airship上でのデータの伝播が高速化される可能性がありますが、全体的な実行時間は遅くなります。 |
| Attribute name | JSON属性の名前。一度に設定できる属性は1つのみです。 |
| Skip Empty Records (optional) | デフォルトはTrueです。クエリ結果に空またはnullの列が含まれている場合、その行はスキップされます。そうでない場合、ジョブは失敗し、空のレコードを手動で削除する必要があります。 |
| Json Composer (optional) | デフォルトはtrueです。Json composerは、提供されたプロパティフィールドからjson値を構成します。それ以外の場合は、有効なjson値を持つプロパティフィールドが必要です。プロパティフィールド名は、更新する属性名と同じである必要があります。 |
サンプルクエリ
この例では、統合はクエリの出力がピボットまたは水平形式で構造化されていることを想定しています。これは、各予約のデータが単一の行に表示され、その予約に関連するフライトのさまざまな属性を表す複数の列があることを意味します。たとえば、顧客が2つのフライトを持っている場合、出力は両方のフライトに関連するすべての詳細を単一の行にリストし、各フライトの属性に特別に指定された列を含みます(例: flights[0].departure_port、flights[1].departure_portなど)。
このアプローチは、各フライトの詳細が別々の行にリストされる垂直形式とは対照的です。ただし、バッチでレコードを収集する場合、オブジェクトの配列のレコードが垂直に記述されていると、同じオブジェクトに属する配列アイテムの収集が漏れる可能性があります。
統合は、Airshipに送信されるJSONオブジェクトを作成することに注意してください。json composerフラグがオフの場合、JSON形式の値を持つ「属性名」の列名が必要です。有効な値は属性としてAirshipに送信されます。
Json composerがオンの場合
WITH flights_with_index AS (
SELECT
f.reservation_id,
f.departure_port,
f.departure_time,
f.arrival_port,
f.arrival_time,
ROW_NUMBER() OVER (
PARTITION BY f.reservation_id
ORDER BY f.departure_time
) - 1 AS flight_index
FROM flights f
JOIN reservations r
ON f.reservation_id = r.reservation_id
)
SELECT
'named_users' AS identifier_type,
r.customer_name AS identifier_value,
t.reservation_id AS instance_id,
MAX(CASE WHEN t.flight_index = 0 THEN t.departure_port END) AS "flights[0].departure_port",
MAX(CASE WHEN t.flight_index = 0 THEN t.departure_time END) AS "flights[0].departure_time",
MAX(CASE WHEN t.flight_index = 0 THEN t.arrival_port END) AS "flights[0].arrival_port",
MAX(CASE WHEN t.flight_index = 0 THEN t.arrival_time END) AS "flights[0].arrival_time",
MAX(CASE WHEN t.flight_index = 1 THEN t.departure_port END) AS "flights[1].departure_port",
MAX(CASE WHEN t.flight_index = 1 THEN t.departure_time END) AS "flights[1].departure_time",
MAX(CASE WHEN t.flight_index = 1 THEN t.arrival_port END) AS "flights[1].arrival_port",
MAX(CASE WHEN t.flight_index = 1 THEN t.arrival_time END) AS "flights[1].arrival_time"
FROM flights_with_index t
JOIN reservations r
ON t.reservation_id = r.reservation_id
GROUP BY
r.customer_name,
t.reservation_id
ORDER BY
instance_id;結果
| identifier_type | identifier_value | instance_id | flights[0].departure_port | flights[0].departure_time | flights[0].arrival_port | flights[0].arrival_time | flights[1].departure_port | flights[1].departure_time | flights[1].arrival_port | flights[1].arrival_time |
|---|---|---|---|---|---|---|---|---|---|---|
| named_users | customer-1 | rev1 | PDX | 2025-01-08 00:00:00.000 | LAX | 2025-01-09 00:00:00.000 | LAX | 2025-01-09 00:00:00.000 | PDX | 2025-01-10 00:00:00.000 |
| named_users | customer-2 | rev2 | SGN | 2025-01-08 00:00:00.000 | BKK | 2025-01-09 00:00:00.000 | BKK | 2025-01-09 00:00:00.000 | SGN | 2025-01-10 00:00:00.000 |
| named_users | customer-3 | rev3 | SGN | 2025-01-08 00:00:00.000 | TDN | 2025-01-09 00:00:00.000 | TDN | 2025-01-09 00:00:00.000 | SGN | 2025-01-10 00:00:00.000 |
| named_users | customer-4 | rev4 | BKK | 2025-01-09 00:00:00.000 | TST | 2025-01-10 00:00:00.000 | ||||
| named_users | customer-5 | rev5 | ABC | 2025-01-09 00:00:00.000 | XTZ | 2025-01-10 00:00:00.000 | ||||
| named_users | customer-6 | rev6 | SSN | 2025-01-09 00:00:00.000 | BKK | 2025-01-10 00:00:00.000 |
Json composerがオフの場合
SELECT
named_user,
instance_id,
booking
FROM (
VALUES
(
'customer-1',
'u111',
'{"flights":[{"departure_port":"PDX","departure_time":"2025-01-08 00:00:00.000","arrival_port":"LAX","arrival_time":"2025-01-09 00:00:00.000"},{"departure_port":"LAX","departure_time":"2025-01-09 00:00:00.000","arrival_port":"PDX","arrival_time":"2025-01-10 00:00:00.000"}]}'
),
(
'customer-2',
'u222',
'{"flights":[{"departure_port":"PDX","departure_time":"2025-01-08 00:00:00.000","arrival_port":"LAX","arrival_time":"2025-01-09 00:00:00.000"},{"departure_port":"LAX","departure_time":"2025-01-09 00:00:00.000","arrival_port":"PDX","arrival_time":"2025-01-10 00:00:00.000"}]}'
)
) AS tbl(named_user, instance_id, booking);結果
| named_user | instance_id | booking |
|---|---|---|
| customer-1 | u111 | {"flights":[{"departure_port":"PDX","departure_time":"2025-01-08 00:00:00.000","arrival_port":"LAX","arrival_time":"2025-01-09 00:00:00.000"},{"departure_port":"LAX","departure_time":"2025-01-09 00:00:00.000","arrival_port":"PDX","arrival_time":"2025-01-10 00:00:00.000"}]} |
| customer-2 | u222 | {"flights":[{"departure_port":"PDX","departure_time":"2025-01-08 00:00:00.000","arrival_port":"LAX","arrival_time":"2025-01-09 00:00:00.000"},{"departure_port":"LAX","departure_time":"2025-01-09 00:00:00.000","arrival_port":"PDX","arrival_time":"2025-01-10 00:00:00.000"}]} |
以下のサンプルクエリを参照して、カスタムイベントをAirshipに同期する方法を確認してください。
| パラメータ | 説明 |
|---|---|
| Data Type | Custom Events |
Json Composer (optional) | デフォルトはfalseです。有効なjson値を持つpropertiesフィールドが必要です。それ以外の場合、json composerは提供されたpropertiesフィールドからjson値を構成します。 |
| Skip Empty Records (optional) | デフォルトはTrueです。クエリ結果に空またはnullのカラムが含まれている場合、その行はスキップされます。それ以外の場合、ジョブは失敗し、空のレコードを手動で削除する必要があります。 |
サンプルクエリ
この例では、インテグレーションはクエリの出力がピボット形式または水平形式で構造化されることを想定しています。これは、各購入のデータが単一の行で表示され、その購入に関連付けられた異なる項目の異なる属性を表す複数のカラムがあることを意味します。たとえば、顧客が2つの項目を持っている場合、出力は両方の項目に関する関連するすべての詳細を単一の行にリストし、各項目の属性専用に指定されたカラム(例:items[0].text、items[1].textなど)があります。
このアプローチは、各項目の詳細が別々の行にリストされる垂直形式とは対照的です。ただし、バッチでレコードを収集する際、オブジェクトの配列のレコードが垂直に記述されている場合、同じオブジェクトに属する配列項目の収集に漏れが発生する可能性があります。
インテグレーションがAirshipに送信されるJSONオブジェクトを作成することに注意してください。
WITH items_with_index AS (
SELECT
f.purchase_id,
f.text,
f.price,
ROW_NUMBER() OVER (
PARTITION BY f.purchase_id
ORDER BY f.text
) - 1 AS item_index
FROM purchase_items f
)
SELECT
r.identifier_type,
r.identifier_value,
r.name,
r.interaction_id,
r.interaction_type,
r.brand AS "properties.brand",
r.value,
r.unique_id,
r.occurred,
MAX(CASE WHEN t.item_index = 0 THEN t.text END) AS "properties.items[0].text",
MAX(CASE WHEN t.item_index = 0 THEN t.price END) AS "properties.items[0].price",
MAX(CASE WHEN t.item_index = 1 THEN t.text END) AS "properties.items[1].text",
MAX(CASE WHEN t.item_index = 1 THEN t.price END) AS "properties.items[1].price",
MAX(CASE WHEN t.item_index = 2 THEN t.text END) AS "properties.items[2].text",
MAX(CASE WHEN t.item_index = 2 THEN t.price END) AS "properties.items[2].price"
FROM items_with_index t
JOIN purchase r
ON t.purchase_id = r.id
GROUP BY
r.identifier_type,
r.identifier_value,
r.name,
r.interaction_id,
r.interaction_type,
r.brand,
r.value,
r.unique_id,
r.occurred;サンプルクエリの結果
| identifier_type | identifier_value | name | interaction_id | interaction_type | properties.brand | value | unique_id | occurred | properties.items[0].text | properties.items[0].price | properties.items[1].text | properties.items[1].price | properties.items[2].text | properties.items[2].price |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| named_user_id | customer-1 | purchase 1 | interaction 1 | url | Brand 1 | 10.5 | unique id 1 | 2025-01-09 00:00:00.000 | text 1 purchase 1 | 4.0 | text 2 purchase 1 | 2.6 | text 3 purchase 1 | 3.5 |
| named_user_id | customer-2 | purchase 2 | interaction 2 | url | Brand 2 | 34.0 | unique id 2 | 2025-01-09 00:00:00.000 | text 1 purchase 2 | 6.7 | text 2 purchase 2 | 4.9 | NULL | NULL |
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
結果エクスポートと組み合わせたスケジュールジョブを使用して、出力結果を定期的に特定のターゲット先に書き込むことができます。
Treasure Dataのスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行することを要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
たとえば、cronスケジュールが '0 0 1 * 1' の場合、「日」の仕様と「曜日」の仕様は矛盾しています。前者の仕様では毎月1日の深夜0時(00:00)に実行することを要求し、後者の仕様では毎週月曜日の深夜0時(00:00)に実行することを要求しているためです。この場合、後者の仕様が優先されます。
Scheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
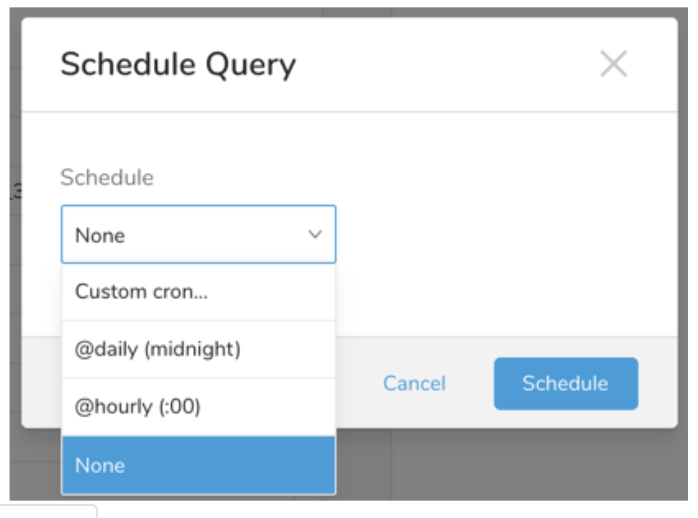
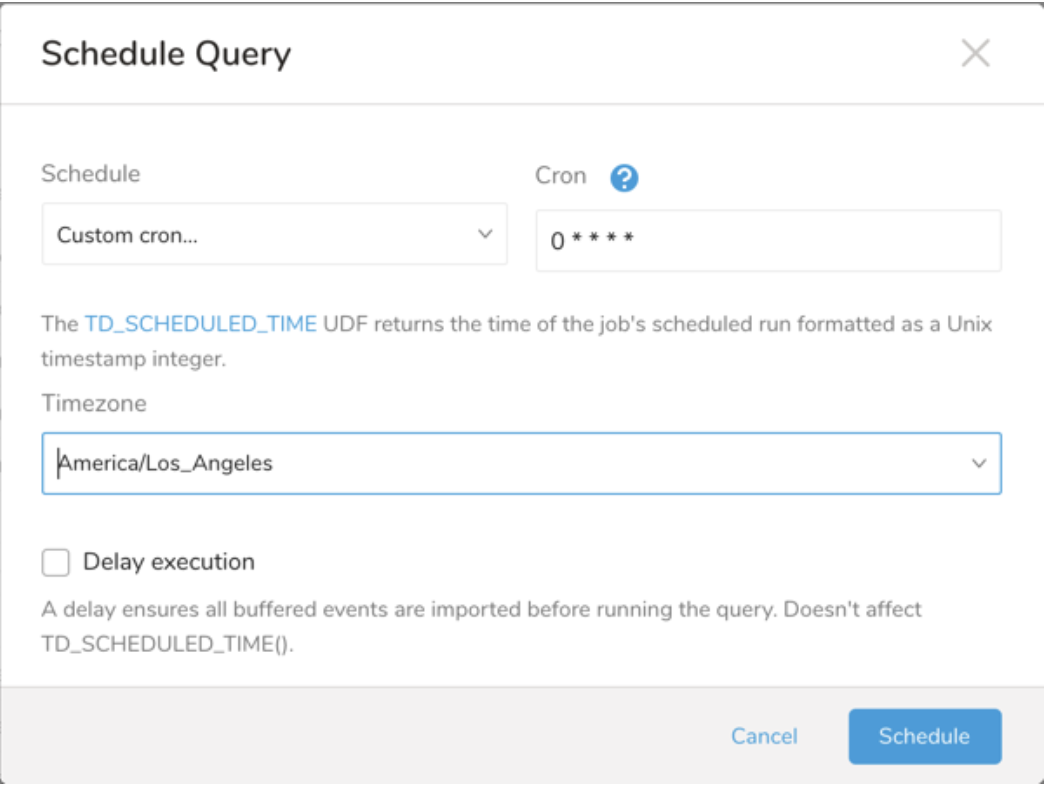
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
クエリに名前を付けて保存して実行するか、単にクエリを実行します。クエリが正常に完了すると、クエリ結果は指定された宛先に自動的にエクスポートされます。
設定エラーにより継続的に失敗するスケジュールジョブは、複数回通知された後、システム側で無効化される場合があります。
(オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。
- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。
- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
Treasure Workflow内で、データコネクタを使用してデータをエクスポートすることを指定できます。
詳細については、TD Toolbeltを使用してワークフローでデータをエクスポートするを参照してください。
Static List用のWorkflow設定サンプル
timezone: UTC
_export:
td:
database:
sample_datasets
+td-result-into-target:
td>: queries/sample.sql
result_connection: airship result_settings:
list_name: 'td uploaded list' list_description: 'ios and android channels'Attributes Update用のWorkflow設定サンプル
timezone: UTC
_export:
td:
database: sample_datasets
+td-result-into-target:
td>: queries/sample.sql
result_connection: airship
result_settings:
data_type: non_json_attributes
non_json_target: named_users
non_json_action: batch_csv
skip_invalid_nonjson_att: truetimezone: UTC
_export:
td:
database: sample_datasets
+td-result-into-target:
td>: queries/sample.sql
result_connection: airship
result_settings:
data_type: custom_events
json_composer_custom_events: true
skip_invalid_custom_events: trueAirship Export Integration CLIを参照してください。
Airship APIドキュメント: