Yahoo! integrationは、広告目的で顧客セグメントをエクスポートします。
- Partnermatch API経由でユーザーIDをアップロードできます
- ユーザーとオーディエンス属性をYahoo!にアップロードできます
消費者は、ショッピング、バンキング、ニュース閲覧、ゲーム、動画視聴など、どこにいても、どのデバイスを使用していても、シームレスなオンライン体験を期待しています。Yahoo! Content Delivery Network(CDN)は、オンラインバンキング、eコマース、メディア配信において世界最大のブランドの一部から信頼されています。これは、顧客体験を向上させ、ロイヤルティを高める高品質、パフォーマンス、信頼性、スケールを提供するためです。
Yahoo!は次のことを支援します:
- 大規模にオーディエンスを魅了する。
- 適切なタイミングで適切な広告を配信する。
- DisneyとABCのデジタルブロードバンドメッセージングを統合する。
このトピックには以下が含まれます:
- Yahoo!のファンベースと顧客ベースをマッチングして、最高のパーソナライズされた体験を提供します。
- カスタム属性を含め、TD上で作成されたセグメントをYahoo!と同期して、より良いカテゴリ化を提供し、パフォーマンスの高いキャンペーンを構築します。
- Yahoo! DMP広告ターゲティングのために、Yahoo!セグメントにオーディエンスをアップロードまたは削除します。
- Treasure Dataの基本知識。
- Yahoo! DataX APIの基本知識
- Yahoo!サポートが提供するMDM ID
DataX APIは非同期方式で実行されます。コネクタからのすべての操作は、30分から1日以上の範囲で有効になります。ジョブ結果をダウンロードする必要がある場合は、TDサポートに連絡してください。
Yahoo!とプロバイダーの制限:
- 1時間あたり100回のAPI呼び出し
- 5GBの圧縮ファイルアップロード制限
TDはアップロードセグメントのステータスの監視をサポートしていません。TDログを確認することでステータスを監視できます。
MDM IDについては、Yahoo!サポートにお問い合わせください。
Treasure Dataでは、クエリを実行する前にデータ接続を作成して設定する必要があります。データ接続の一部として、統合にアクセスするための認証を提供します。
- TD Consoleを開きます。
- Integrations Hub > Catalogに移動します。
- Yahoo!を検索して選択します。

- Create Authenticationを選択します。
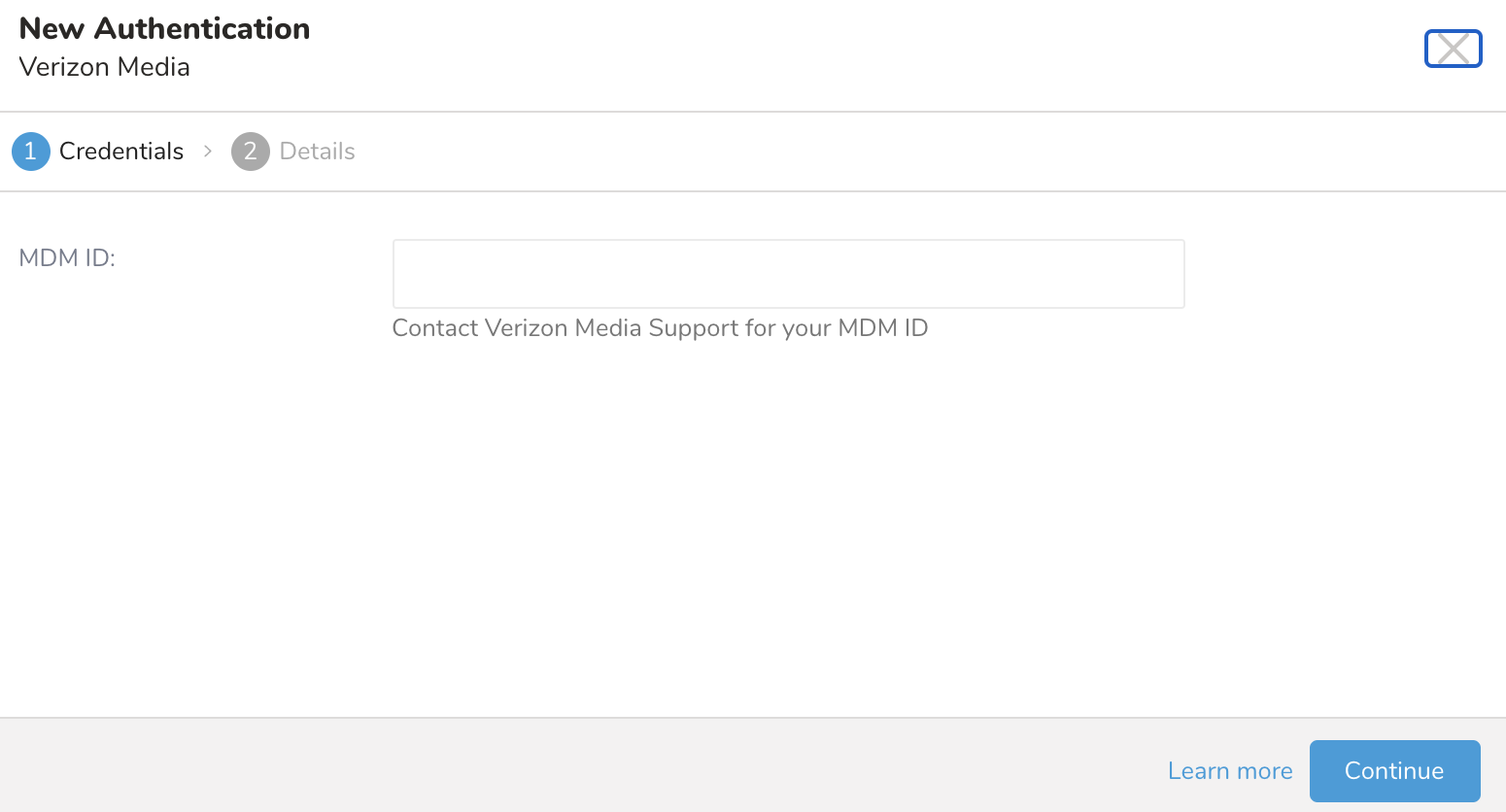
- MDM IDを入力します。例: OH224。
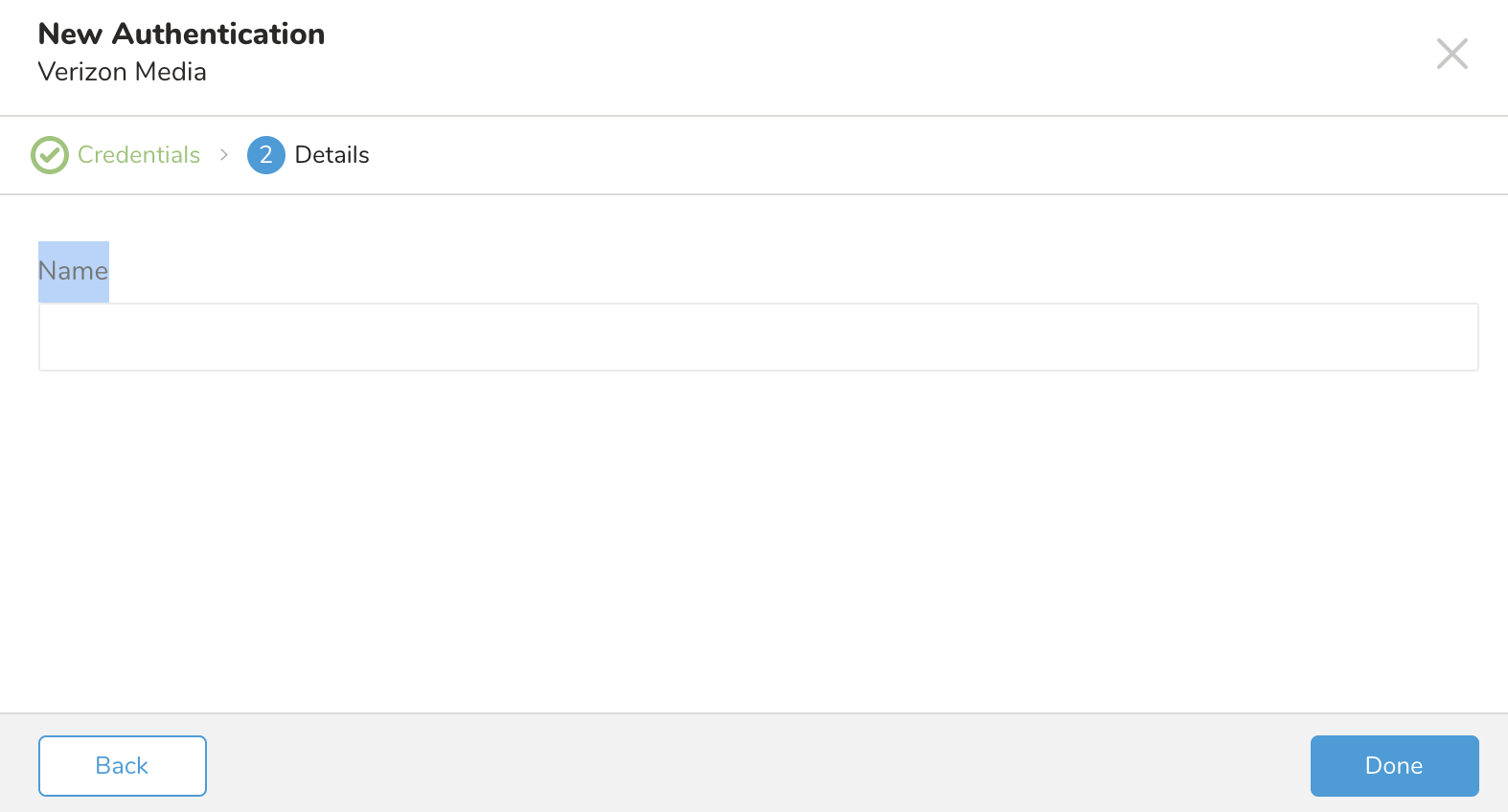
- 接続の名前を入力します。
- Doneを選択します。
| Parameter | Values | Description |
|---|---|---|
| Mode | 値は以下:
| アップロードモードを選択 - Partner Match: Partner Match API経由でユーザーIDとメールをアップロード - Audience: オーディエンスレコードをアップロード - Taxonomy: タクソノミー階層を作成または変更 - Opt-out: タクソノミー階層全体からオーディエンスを削除 |
| Taxonomy Mode | 値は以下:
| Taxonomyアップロードのモードを選択:
|
| URN Type | 値は選択したモードによって異なります。例の型は:
| 値は選択したモードによって異なります。Uniform Resource Name(URN)は、場所に関係なくリソースまたは情報の単位を識別します。URNはグローバルに一意で、永続的で、ネットワーク経由でアクセス可能です。Yahoo! urnの構文: "urn":{string}, "seg":[{"id":{string},"ts":{number},"exp":{number}}] 例: {"urn" : "99ff2333f3fe7659c38b3674bc927f32", "seg" : [{"id":"OH224"}]} |
| Target Segment ID | Audienceモードが選択されている場合。 | ターゲットセグメントのID。これはクエリ結果のオプションフィールドと組み合わせます: seg_exp, seg_ts |
| GDPR | Audienceモードが選択されている場合。 | General Data Protection Regulation (EU GDPR) |
| Dry Run | Taxonomyが選択されている場合 | 現在のTaxonomyを更新せずに、同期が期待どおりかどうかを確認するために有効化します。 |
| Column name | Type | Required | Description |
|---|---|---|---|
| String | Yes | この列はプレーンテキストのメールまたはSHA256ハッシュメールを受け入れます。プレーンテキストのメールはYahoo!サーバーに送信される前にハッシュ化されます | |
| PXID | String | Yes | |
| Phone | String | No | この列はプレーンテキストまたはSHA256ハッシュ電話を受け入れます。プレーンテキストの電話はYahoo!サーバーに送信される前にハッシュ化されます。 |
クエリ例
select 'abc@tese.com' as email, 'abc' as pxid
UNION ALL SELECT 'abc123@tese.com' as email, 'a12bc' as pxid
UNION ALL SELECT 'abcadcc@tese.com' as email, 'ab1231c' as pxid
select 'abc@tese.com' as email, 'abc' as pxid, '+112345678' as phone
UNION ALL SELECT 'abc123@tese.com' as email, 'a12bc' as pxid, '+134567182' as phone
UNION ALL SELECT 'abcadcc@tese.com' as email, 'ab1231c' as pxid, '+1456104632' as phone| Column name | Type | Required | Description |
|---|---|---|---|
| urn | String | Yes | 値は選択したURN Typeと一致します。プレーンテキストのメールは送信前にハッシュ化されます |
| <attribute_id> | Any type | Taxonomyで定義された任意の属性ID。例: Age、Country、G123... クエリで複数の属性IDを選択できます | |
| seg_ts | Long | urnに関連付けられたタイムスタンプ | |
| seg_exp | Long | urnに関連付けられた有効期限 | |
| att_ts | Long | 属性に関連付けられたタイムスタンプ | |
| att_exp | Long | 属性に関連付けられた有効期限 |
クエリ例
SELECT urn, CT01, GEN, seg_ts, seg_exp, att_ts, att_exp
FROM audiences| Column name | Type | Required | Description |
|---|---|---|---|
| parent_id | String | Yes | Null値はルートタクソノミーを示します |
| id | String | Yes | 必須値で、会社全体で一意である必要があります。 |
| name | String | Yes | "id"の人間にわかりやすい同等物 |
| type | String | Yes | 現在サポートされている型は: SEGMENT, ATTRIBUTE |
| description | String | ||
| att_type | String | 属性型。現在可能な値は: ENUM、DATETIME、ZIPCODE、NUMBER、STRING。詳細については、この外部リファレンスを参照してください: https://developer.yahooinc.com/datax/guide/taxonomy/taxonomy-rep/。 | |
| att_values | String | 属性値。ENUMおよびNUMBER型には必須。例: - enumの場合: [ "Loyal", "Occasional", "Rare" ] - 数値の場合: [ "1 | |
| gdpr_mode | String |
| Column name | Type | Required | Description |
|---|---|---|---|
| urn | String | Yes | 値は選択したURN Typeと一致します。プレーンテキストのメールは送信前にハッシュ化されます |
TaxonomyはYahooがパートナーのデータの階層的(またはフラット)な組織とその関連メタデータをインポートするのに役立ちます。タクソノミーのアップロードは、ユーザー/オーディエンスデータのアップロードの前提条件です。
- TD Root: すべてのアカウントは単一のルート名"Private"(デフォルトID: TD0001)の下に作成されます。すべてのクライアントサブツリーは、このルートの下に追加する必要があります。
- 各アカウント(MDM IDで表される)には、単一のルートを持つ1つのツリー(アカウントツリー)のみがあります。例: Account A。
- 各ツリーノードのIDは、すべてのアカウントで一意です。
- 各ノードタイプはSEGMENTまたはATTRIBUTEのみを受け入れます
クライアントサブツリーを持つTreasure Data Taxonomyツリーの例:
+ Private (TD0001)
├-- Account A
| ├── seg1 name(seg1)
| │ ├── seg1.1 name(seg1.1)
| │ └── seg1.2 name(seg1.2)
| └── root attribute name 100(root attribute 100)
| └── att1 name(att1)
├-- Account B
├--- Seg ABコネクタはTaxonomyツリー構造アップロード用の4つのモードをサポートしています:
- Whole Structure
- Append Node
- Replace Node
- Delete Node
Whole Structure: これはTaxonomyのデフォルトモードです。ツリー構造全体をアップロードし、新しいノードのみを保持します。現在のアカウントツリーの古いノードは削除され、新しいツリーの新しいノードに置き換えられます。 検証:
- アカウントルートノードのID = null(データベースではparent_id = null)、ID列は必須です。
- 親を持たない孤立ノードは許可されていません。
- 各実行で削除できるのはリーフノードのみです。
- アカウントノードが存在しない場合、TDルートまたはPrivate(TD0001)に追加されます。
1つのルート(parent_id = null)のみが許可されます。Append Node
既存のparentIdノードに単一ノードまたはサブツリーを追加します。会社ツリーが作成されていない場合、入力ルートで新しいツリーが作成され、TDルートの下に追加されます。
検証:
- アカウントツリーが存在しない場合、1つの入力ルートを持つ新しいアカウントツリーが作成され、Private(デフォルトID: TD0001)に追加されます。
- アカウントツリーが存在しない場合、クエリ結果で最大1つのルートノードが許可されます。
- アカウントツリーが存在する場合、クエリ結果でルートノードは許可されません。
- 会社ルートがnullでない場合、各ノードの親IDが存在する必要があります。
- 会社ツリーがnullでない場合、Append nodeを使用してはいけません。
例:
現在のアカウントツリー
root segment name 200 (root segment 200)
├── SEG Child 6 (seg6)
├── SEG Child 2 (seg2)
├── SEG Child 5 (seg5)
│ ├── SEG Child 5.1 (seg5.1)
│ └── SEG Child 5.2 (seg5.2)
├── SEG Child 4(seg4)
│ ├── SEG Child 4.3 (seg4.3)
│ └── SEG Child 4.1 (seg4.1)
└── SEG Child 3 (seg3)
├── SEG Child 3.1 (seg3.1)
└── SEG Child 3.2 (seg3.2)入力データ
SELECT parent_id, id, name, type
FROM
(
VALUES
('TD0008','seg8.1','SEG 8.1','SEGMENT')
) tbl (parent_id,id,name,type);期待されるツリーは以下のようになります:
root segment name 200 (root segment 200)
├── SEG Child 6 (seg6)
│ ├── SEG Child 6.1 (seg6.1)
│ └── SEG Child 6.2 (seg6.2)
├── SEG Child 2 (seg2)
├── SEG Child 5 (seg5)
│ ├── SEG Child 5.1 (seg5.1)
│ └── SEG Child 5.2 (seg5.2)
├── SEG Child 4 (seg4)
│ ├── SEG Child 4.3 (seg4.3)
│ └── SEG Child 4.1 (seg4.1)
├── SEG Child 3 (seg3)
│ ├── SEG Child 3.1 (seg3.1)
│ └── SEG Child 3.2 (seg3.2)
├── SEG 8 (seg8)
│ └── SEG Child 8.1 (seg8.1)
└── SEG 7 (seg7)Replace Node既存のタクソノミーノードとそのサブツリーを新しいタクソノミーデータで置き換えます。会社ルートまたはTDルートを置き換えることはできません。会社ルートのサブツリーのみを置き換えることができます。
検証:
- この操作を行うには、アカウントツリーが存在する必要があります。
- 入力サブツリーのルートは空であってはなりません。
- アカウントルートの置き換えは許可されていません。
- TDルート(Private)の置き換えは許可されていません。
- 入力ツリーのルートノードはアカウントツリーの下にある必要があります。
例
以下のようなアカウントツリーがあります
Sample TD Segment(TD0002)
├── Child 1(TD0003)
│ └── Child 1.1(TD0007)
│ └── Child 1.1.1(TD0008)
│ └── SEG 8.1(seg8.1)
└── Child 2(TD0004)
├── Child 2.1(TD005)
│ └── Child 2.1.1(TD005_1)
└── Child 2.2(TD0006)
└── Child 2.2.2(TD0006_1)SQLデータからこの階層を構築することを期待します
SELECT parent_id, id, name, type
FROM
(
VALUES
('','TD0007','Child 1.1','SEGMENT'),
('TD0007','TD0008','Child 1.1.1','SEGMENT'),
('TD0007','TD0009','Child 1.1.2','SEGMENT'),
('TD0007','TD0010','Child 1.1.3','SEGMENT')
) tbl (parent_id,id,name,type);期待されるツリーは以下のようになります
Sample TD Segment(TD0002)
├── Child 1(TD0003)
│ └── Child 1.1(TD0007)
│ ├── Child 1.1.2(TD0009)
│ ├── Child 1.1.1(TD0008)
│ └── Child 1.1.3(TD0010)
└── Child 2(TD0004)
├── Child 2.1(TD005)
│ └── Child 2.1.1(TD005_1)
└── Child 2.2(TD0006)
└── Child 2.2.2(TD0006_1)Replace Nodeサブツリーと共に既存のタクソノミーノードを削除します。
検証:
- ツリールート(アカウントルートまたはTDルート)の削除は許可されていません。
ノードはnullであってはならず、アカウントツリーに存在する必要があります。この操作を行うには会社ツリーが存在する必要があります。
例:
以下のようなアカウントツリーがあります
Sample TD Segment(TD0002)
├── Child 1(TD0003)
│ └── Child 1.1(TD0007)
│ └── Child 1.1.1(TD0008)
└── Child 2(TD0004)
├── Child 2.1(TD005)
│ └── Child 2.1.1(TD005_1)
└── Child 2.2(TD0006)
└── Child 2.2.2(TD0006_1)SQLデータからこの階層を構築することを期待します
SELECT parent_id,id,name,type
FROM
(
VALUES
('','TD005_1','Child 2.1.1','SEGMENT')
)tbl (parent_id,id,name,type);期待されるツリーは以下のようになります
Sample TD Segment(TD0002)
├── Child 1(TD0003)
│ └── Child 1.1(TD0007)
│ └── Child 1.1.1(TD0008)
└── Child 2(TD0004)
├── Child 2.1(TD005)
└── Child 2.2(TD0006)
└── Child 2.2.2(TD0006_1)You can use Scheduled Jobs with Result Export to periodically write the output result to a target destination that you specify.
Treasure Data's scheduler feature supports periodic query execution to achieve high availability.
When two specifications provide conflicting schedule specifications, the specification requesting to execute more often is followed while the other schedule specification is ignored.
For example, if the cron schedule is '0 0 1 * 1', then the 'day of month' specification and 'day of week' are discordant because the former specification requires it to run every first day of each month at midnight (00:00), while the latter specification requires it to run every Monday at midnight (00:00). The latter specification is followed.
Navigate to Data Workbench > Queries
Create a new query or select an existing query.
Next to Schedule, select None.

In the drop-down, select one of the following schedule options:
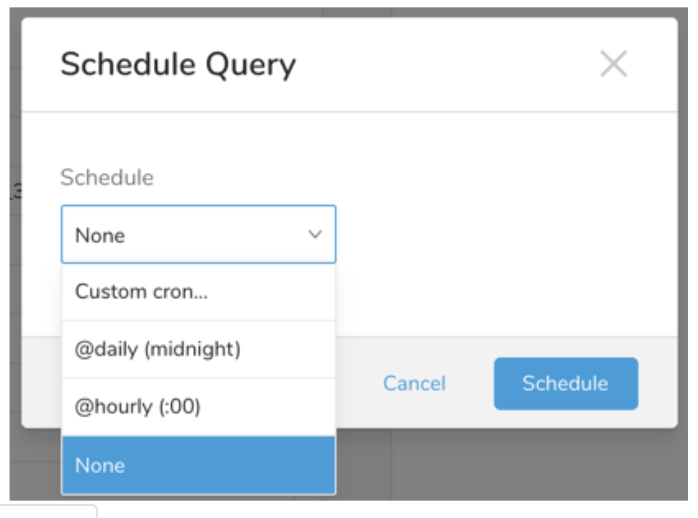
Drop-down Value Description Custom cron... Review Custom cron... details. @daily (midnight) Run once a day at midnight (00:00 am) in the specified time zone. @hourly (:00) Run every hour at 00 minutes. None No schedule.
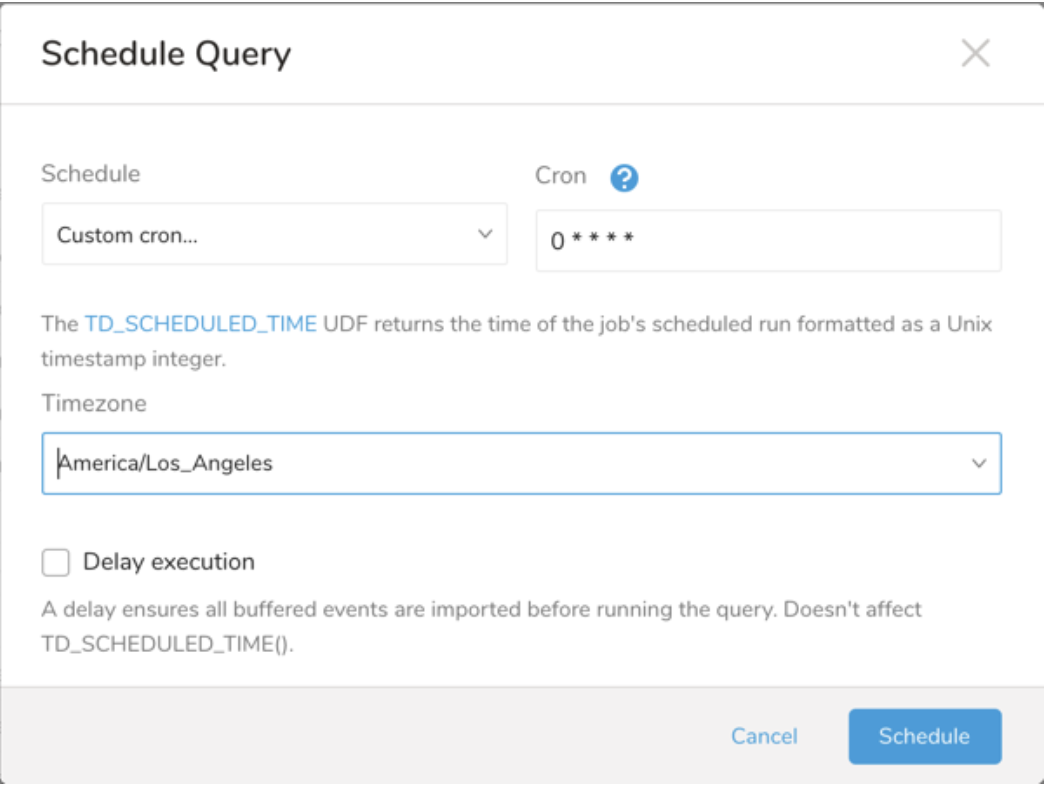
| Cron Value | Description |
|---|---|
0 * * * * | Run once an hour. |
0 0 * * * | Run once a day at midnight. |
0 0 1 * * | Run once a month at midnight on the morning of the first day of the month. |
| "" | Create a job that has no scheduled run time. |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)The following named entries can be used:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
A single space is required between each field. The values for each field can be composed of:
| Field Value | Example | Example Description |
|---|---|---|
| A single value, within the limits displayed above for each field. | ||
A wildcard '*' to indicate no restriction based on the field. | '0 0 1 * *' | Configures the schedule to run at midnight (00:00) on the first day of each month. |
A range '2-5', indicating the range of accepted values for the field. | '0 0 1-10 * *' | Configures the schedule to run at midnight (00:00) on the first 10 days of each month. |
A list of comma-separated values '2,3,4,5', indicating the list of accepted values for the field. | 0 0 1,11,21 * *' | Configures the schedule to run at midnight (00:00) every 1st, 11th, and 21st day of each month. |
A periodicity indicator '*/5' to express how often based on the field's valid range of values a schedule is allowed to run. | '30 */2 1 * *' | Configures the schedule to run on the 1st of every month, every 2 hours starting at 00:30. '0 0 */5 * *' configures the schedule to run at midnight (00:00) every 5 days starting on the 5th of each month. |
A comma-separated list of any of the above except the '*' wildcard is also supported '2,*/5,8-10'. | '0 0 5,*/10,25 * *' | Configures the schedule to run at midnight (00:00) every 5th, 10th, 20th, and 25th day of each month. |
- (Optional) You can delay the start time of a query by enabling the Delay execution.
Save the query with a name and run, or just run the query. Upon successful completion of the query, the query result is automatically exported to the specified destination.
Scheduled jobs that continuously fail due to configuration errors may be disabled on the system side after several notifications.
(Optional) You can delay the start time of a query by enabling the Delay execution.
You can also send segment data to the target platform by creating an activation in the Audience Studio.
- Navigate to Audience Studio.
- Select a parent segment.
- Open the target segment, right-mouse click, and then select Create Activation.
- In the Details panel, enter an Activation name and configure the activation according to the previous section on Configuration Parameters.
- Customize the activation output in the Output Mapping panel.

- Attribute Columns
- Select Export All Columns to export all columns without making any changes.
- Select + Add Columns to add specific columns for the export. The Output Column Name pre-populates with the same Source column name. You can update the Output Column Name. Continue to select + Add Columnsto add new columns for your activation output.
- String Builder
- + Add string to create strings for export. Select from the following values:
- String: Choose any value; use text to create a custom value.
- Timestamp: The date and time of the export.
- Segment Id: The segment ID number.
- Segment Name: The segment name.
- Audience Id: The parent segment number.
- + Add string to create strings for export. Select from the following values:
- Set a Schedule.

- Select the values to define your schedule and optionally include email notifications.
- Select Create.
If you need to create an activation for a batch journey, review Creating a Batch Journey Activation.
Treasure Workflow内で、このデータコネクタを使用してデータをエクスポートすることを指定できます。
詳細はUsing Workflows to Export Data with the TD Toolbeltを参照してください。
| Name | Type | Required | Description |
|---|---|---|---|
| type | String | Yes | verizon_media |
| mdm_id | String | Yes | 会社のMDM ID |
| upload_mode | String | Yes | PARTNER_MATCH, TAXONOMY, AUDIENCE_UPLOAD, OPT_OUT |
| taxonomy_mode | String | Taxonomyアップロードにのみ適用 | |
| urn_type | String | Yes | Audienceアップロードにのみ適用 |
| partner_match_urn_type | String | Yes | Partner Matchモードにのみ適用 |
| opt_out_urn_type | String | Yes | Opt-outモードにのみ適用 |
| target_segment_id | String | このセグメントにオーディエンスをアップロード | |
| gdpr | Boolean | デフォルトtrue | |
| taxonomy_dry_run | Boolean | Taxonomyアップロードジョブの実行のみを検証(実際のデータを変更せずに)。デフォルトfalse |
_export:
td:
database: td.database
+verizon_media_export_task:
td>: export_verizon_media.sql
database: ${td.database}
result_connection: verizon_media
result_settings:
type: verizon_media
upload_mode: audience
urn_type: EmailTD Toolbeltが提供するCLIを使用して、クエリ結果をYahoo!にエクスポートすることもできます。
td queryコマンドを使用する場合、--result RESULT_URLオプションでLINE変換サーバーURLを指定します。詳細については、td queryを参照してください。
オプションの形式はJSONで、一般的な構造は以下のとおりです。
{
"type": "verizon_media",
"mdm_id": "100",
"upload_mode": "taxonomy",
"taxonomy_mode": "append_node"
}パラメータ
| Name | Type | Required | Description |
|---|---|---|---|
| type | String | Yes | verizon_media |
| mdm_id | String | Yes | 会社のMDM ID |
| upload_mode | String | Yes | PARTNER_MATCH, TAXONOMY, AUDIENCE_UPLOAD, OPT_OUT |
| taxonomy_mode | String | Taxonomyアップロードにのみ適用。値: - whole_structure - append_node, - replace_node - delete_node | |
| urn_type | String | Yes | Audienceアップロードにのみ適用 |
| partner_match_urn_type | String | Yes | Partner Matchモードにのみ適用 |
| opt_out_urn_type | String | Yes | Opt-outモードにのみ適用 |
| target_segment_id | String | このセグメントにオーディエンスをアップロード | |
| gdpr | Boolean | デフォルトtrue | |
| taxonomy_dry_run | Boolean | Taxonomyアップロードジョブの実行のみを検証(実際のデータを変更せずに)。デフォルトfalse |
td query \
--result '{
"type": "verizon_media",
"upload_mode": "taxonomy",
"taxonomy_mode": "append_node",
"mdm_id": "100"
}' \
-d sample_datasets \
"SELECT * FROM verizon_media_tbl" \
-T presto