Treasure Dataコネクタを使用して、ジョブ結果をTreasure Dataデータベースに書き込むことができます。通常、このコネクタは、あるTreasure DataアカウントからTreasure Dataアカウントにデータをエクスポートするために使用されます。
あるTDアカウントから別のTDアカウントへのジョブ結果の書き込みに関するサンプルワークフローについては、Treasure Boxesを参照してください。
アカウント内のあるテーブルから同じアカウント内の別のテーブルにデータを書き込むためにこのコネクタを使用することは強くお勧めしません。代わりに、最高のパフォーマンスを得るために「INSERT INTO」クエリまたは「INSERT OVERWRITE/CREATE TABLE AS SELECT」クエリを使用してください。
Presto:「CREATE TABLE AS SELECT」または「INSERT INTO」
Hive:「INSERT INTO/OVERWRITE」
- TD Toolbeltを含むTreasure Dataの基本的な知識。
- もしエクスポート元とエクスポート先でTreasure Dataアカウントのリージョンが異なり、かつ本機能の設定で利用するAPI Keyを所有するユーザーのアクセスがIP Allowlist機能によって制限されている場合、IP Allowlistでエクスポート元のTreasure Dataリージョンが利用するIPアドレスを登録する必要があります。ドキュメントを確認し、エクスポート元リージョンのIPアドレス表においてExport Integrations列に記載されているIPアドレスをIP Allowlistに登録してください。
TD ConsoleまたはCLIから接続を設定できます。
TD Console内から接続を設定できます。アカウント間転送を完了するには、ターゲットのTreasure Dataアカウントから開始します。ターゲットアカウントプロファイルからAPI Key情報をコピーする必要があります。
TD Console > My Settingsに移動します。管理者権限が必要です。

API Keysを選択します。
必要に応じてアクセスを検証します。
検証が完了してプロファイルに戻ると、マスターキーと書き込み専用キーの両方が表示されます。Write-only API keyをハイライトします。それを選択すると、自動的にクリップボードにコピーされます。
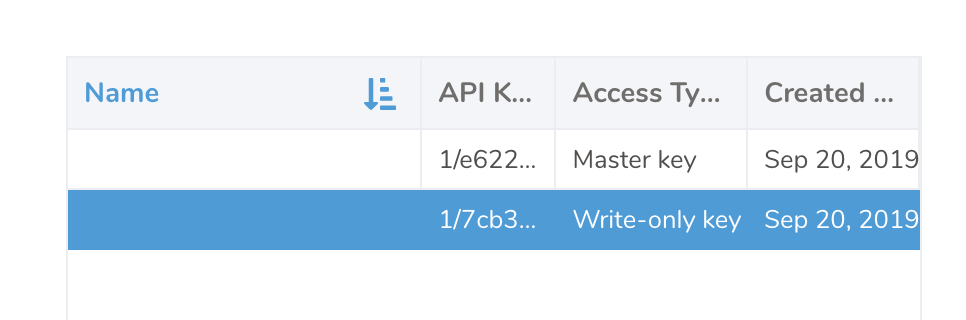

データ転送がmode=replaceなどで既存のデータを更新する場合は、書き込み専用キーの代わりにマスターキーを使用する必要があります。
データ接続を設定する際、統合にアクセスするための認証を提供します。Treasure Dataでは、認証を設定してからソース情報を指定します。
TD Consoleを開きます。
Integrations Hub > Catalogに移動します。
Treasure Dataタイルを検索して選択します。

Createを選択します。ターゲットアカウントから書き込み専用API Keyを入力します。API Hostnameには、エクスポートに使用するサーバーを入力します。フィールドを空白のままにして、リージョンのデフォルトサーバーを使用できます。または、次のいずれかの値を入力できます:
- US: api.treasuredata.com
- JP: api.treasuredata.co.jp
- EU01: api.eu01.treasuredata.com
- AP02 (Korea): api.api02.treasuredata.com
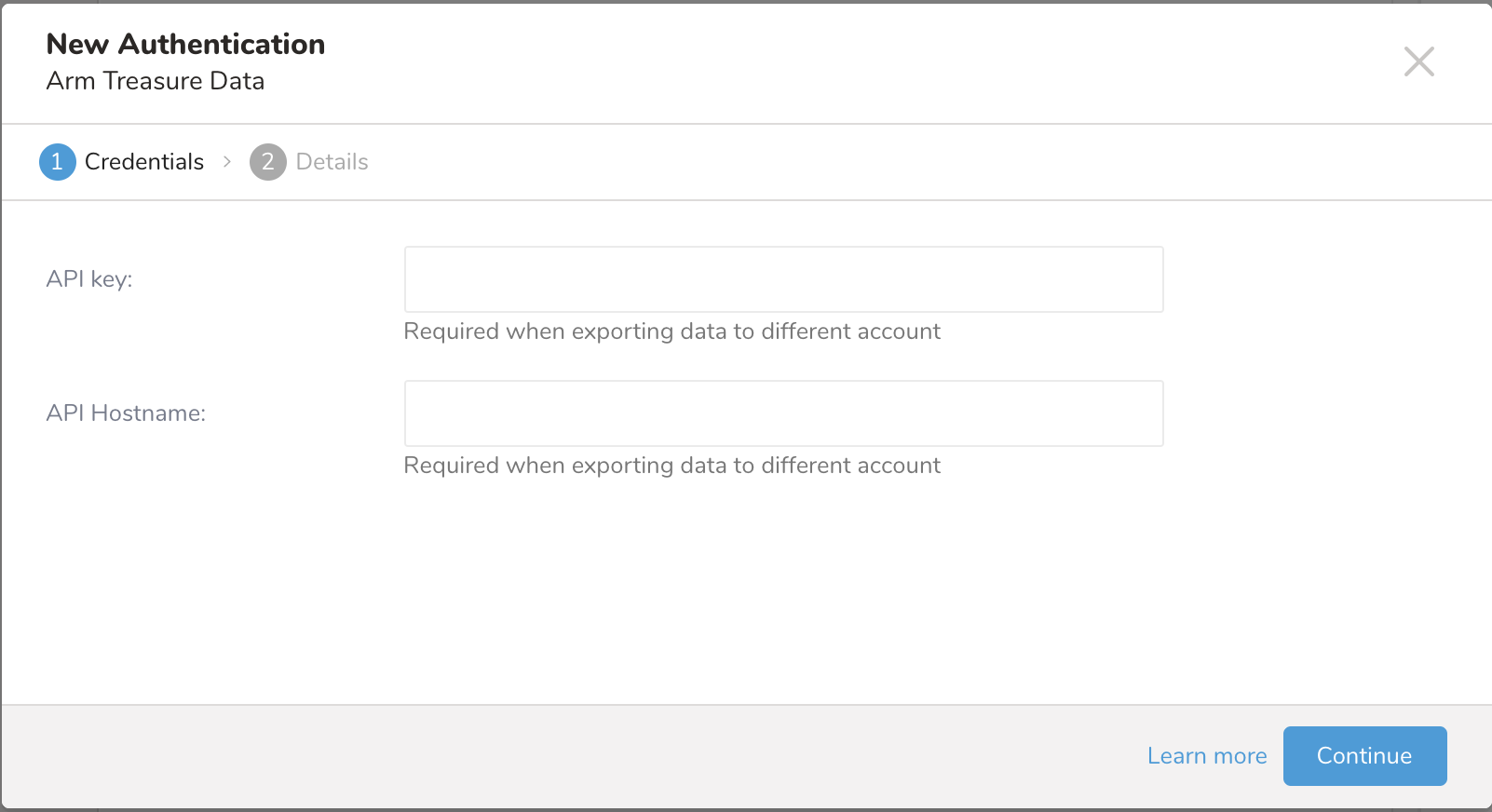
- Continueを選択します。接続に名前を付けてCreate Connectionを選択します。
あるリージョンから別のリージョンにデータを書き込む場合、例えばAWS USからAWS JPの場合、API Hostnameフィールドは必須です。
転送を作成するには、データ接続を設定するクエリを作成または再利用します。
TD Consoleを開きます。
Data Workbench > Queriesに移動します。データをエクスポートするために使用する予定のクエリをハイライトします。
クエリエディタの右上にあるExport Resultsを選択します。
SELECT code, COUNT(1) FROM www_access GROUP BY codeChoose Integrationダイアログが開きます。

Use Existing Integrationを選択し、保存された認証の名前を検索します。
認証を選択した後、Nextを選択します。Export Resultsダイアログが開きます。
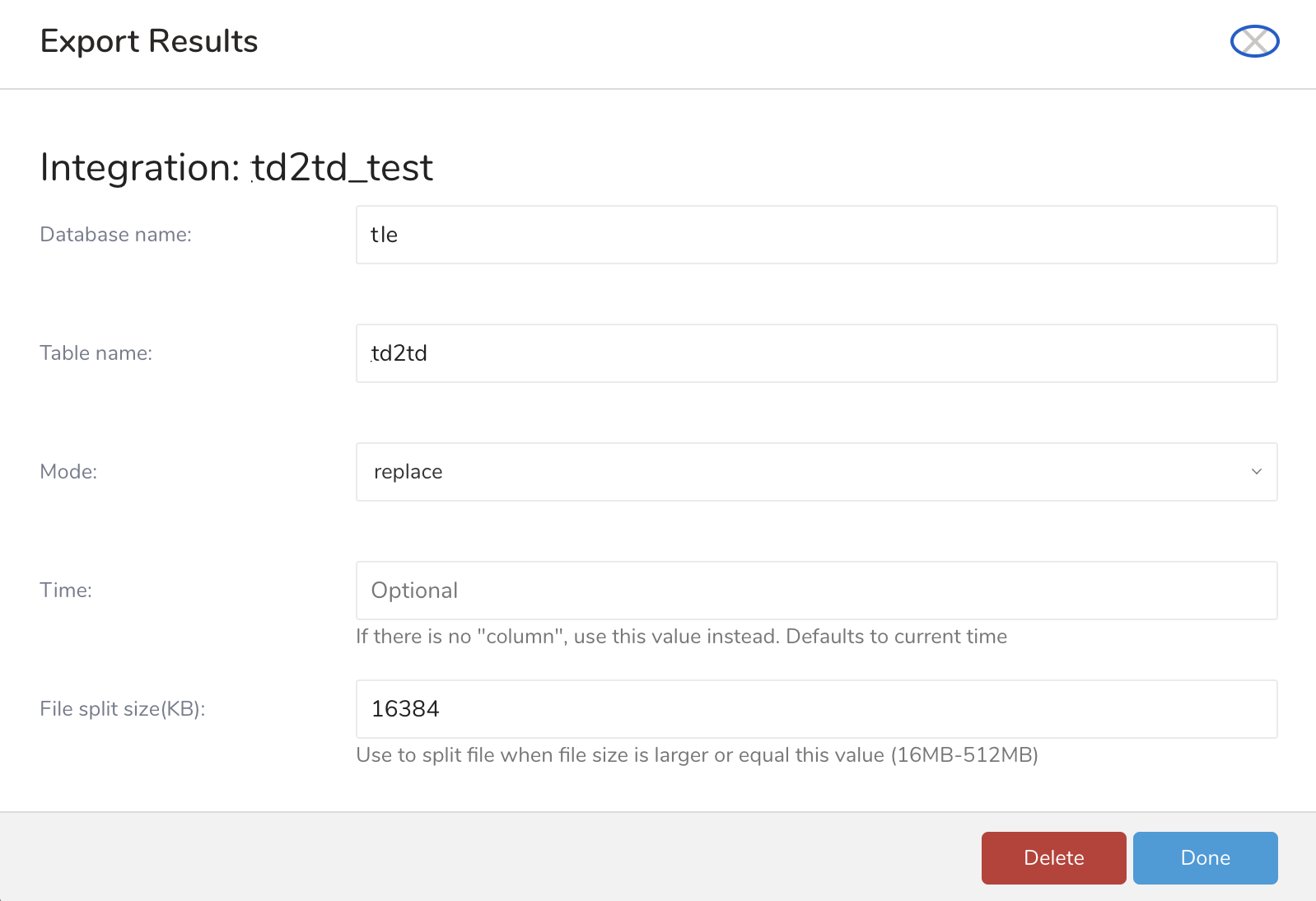
パラメータを指定し、Doneを選択します。
| Parameters | Description |
|---|---|
| Database name (required) | 既存のデータベースの名前。 |
| Table name (required) | テーブル名。テーブルが存在しない場合は新しいテーブルが作成されます。 |
| Mode (required) | データをインポートするためのAppendまたはReplaceメソッドを選択します。
|
| Time (optional) | ユーザー定義の時間値。クエリ結果に時間カラムがない場合に適用されます。 |
| File split size (KB) | ファイルサイズがこの値以上の場合にファイルを分割するために使用します(16MB-512MB) |
Scheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
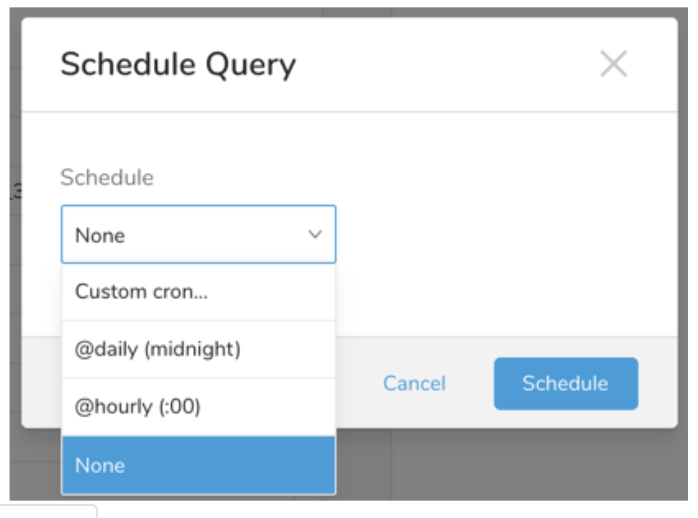
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
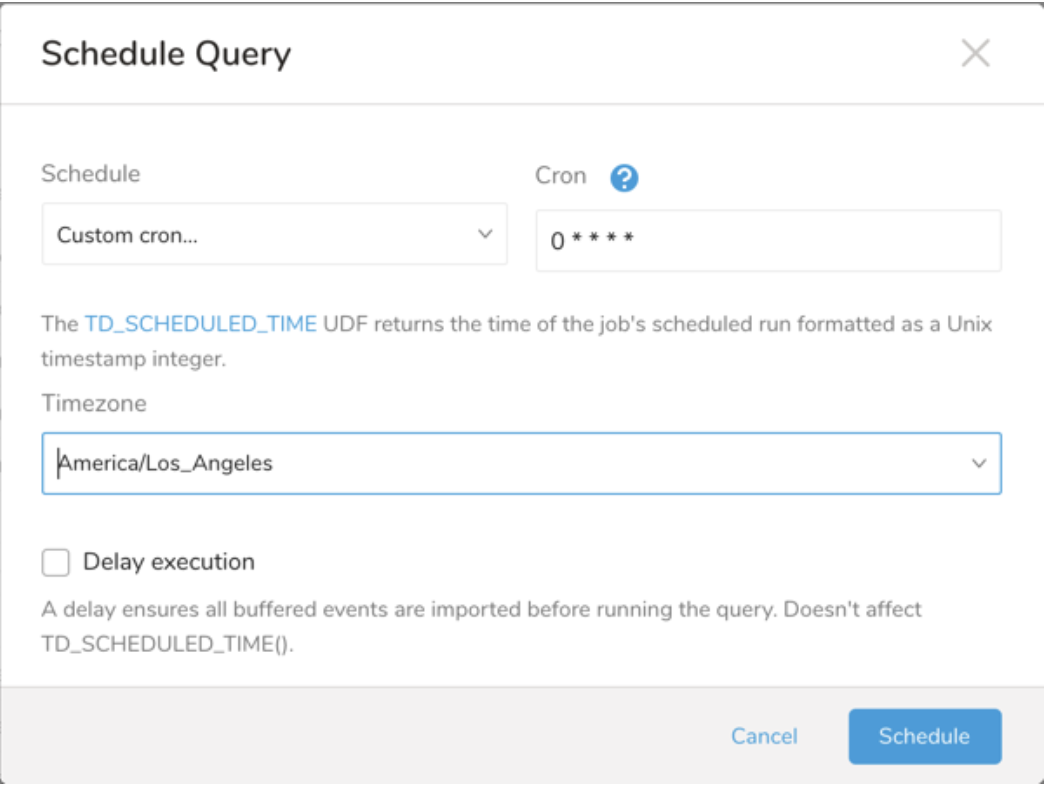
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
クエリに名前を付けて保存して実行するか、単にクエリを実行します。クエリが正常に完了すると、クエリ結果は指定された宛先に自動的にエクスポートされます。
設定エラーにより継続的に失敗するスケジュールジョブは、複数回通知された後、システム側で無効化される場合があります。
(オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
オンデマンドジョブの場合は、td queryコマンドに--resultオプションを追加するだけです。ジョブが完了すると、結果はtestdbデータベース内のoutput_tableに書き込まれます。
$ td query --result 'td://@/testdb/output_table' \
-w -d testdb \
"SELECT code, COUNT(1) FROM www_access GROUP BY code"スケジュールされたジョブの場合は、ジョブをスケジュールするときに--resultオプションを追加するだけです。ジョブが実行されるたびに、結果はoutput_tableに書き込まれます。
$ td result:create mydb td://@/testdb
$ td sched:create hourly_count_example "0 * * * *" \
-d testdb "select count(*) from www_access" \
--result mydb:output_table2つの方法でデータを追加または削除できます:
- append
- replace
td://@/testdb/output_table # append
td://@/testdb/output_table?mode=append # append
td://@/testdb/output_table?mode=replace # replaceこれはデフォルトモードです。クエリ結果はテーブルに追加されます。テーブルがまだ存在しない場合は、新しいテーブルが作成されます。この操作は冪等ではありません。同じ呼び出しを繰り返し行っても同じ結果を生成することはできません。このモードはatomicではありません。
テーブルがすでに存在する場合、既存のテーブルの行はクエリ結果で置き換えられます。テーブルがまだ存在しない場合は、新しいテーブルが作成されます。
次の3つのステップを単一のトランザクションで実行することにより、atomicity(テーブルの消費者が常に一貫したデータを持つように)を実現します。
- 一時テーブルを作成します。
- 一時テーブルに書き込みます。
- 既存のテーブルを一時テーブルでアトミックに置き換えます。