Salesforce DMP (Krux) から、メディアキャンペーン、ペイドサーチキャンペーン、サイトキャンペーン、ユーザーオーディエンスセグメントマップ、セグメントマッピングファイル、または不同意リストを Treasure Data にインポートできます。
- Treasure Data の基礎知識(Toolbelt および JavaScript SDK を含む)
- アクセスキーIDとシークレットアクセスキーを持つS3認証情報
- Salesforce DMP のクライアント名
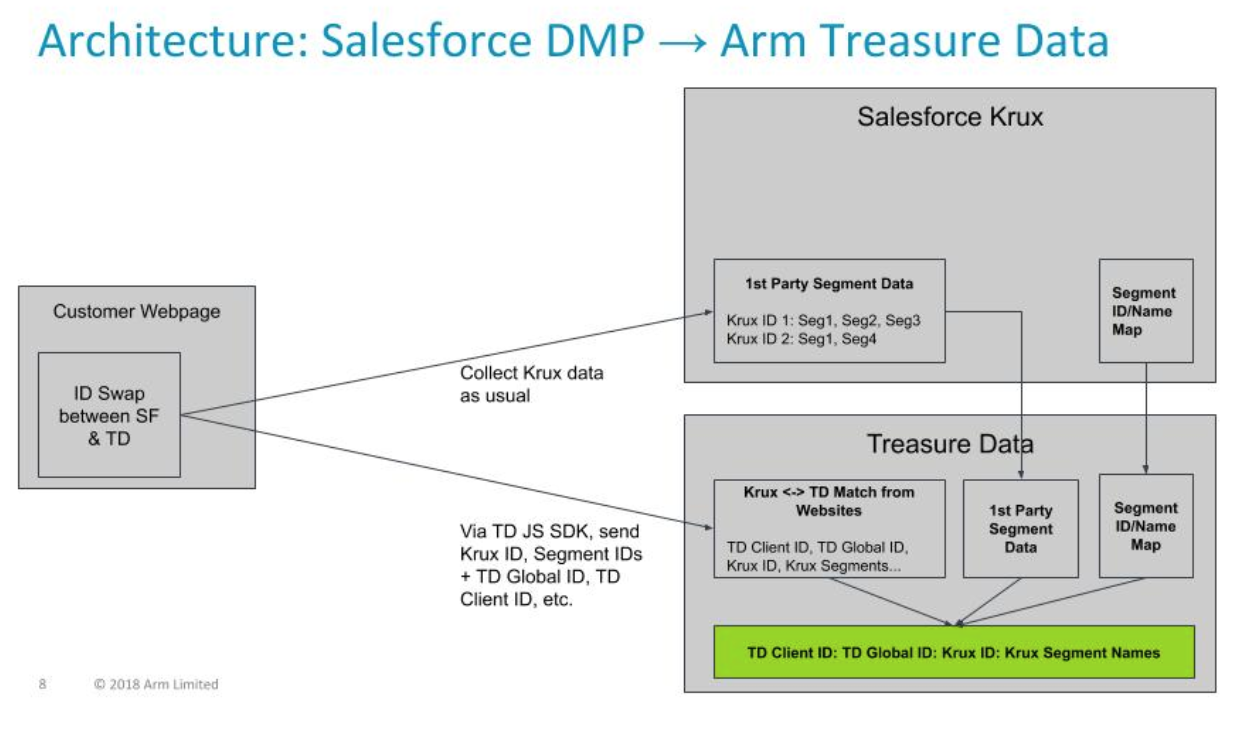
この連携には2つのパートがあります:
- Salesforce DMP と Treasure Data CDP 間の Cookie 同期: Salesforce DMP ID と Treasure Data ID の td_global_id および td_client_id 間のマッピングを作成するために必要です
- Salesforce DMP から Treasure Data CDP へのデータインポート: 取り込み可能な様々なデータフィードがあります。データエンリッチメントの目的では、セグメントIDとその名前のマッピングが重要なファイルです。
まず、ウェブサイトトラッキングの開始 の「ウェブサイトトラッキングの設定と Treasure Data JavaScript SDK のインストール」に記載されているように、Treasure Data の JavaScript タグを設定する必要があります。
次に、Salesforce DMP のタグが既にインストールされているウェブサイトに、以下のコードを追加します。
(function(window, document, td){
var kruxProperties = {};
for ( var k in window.localStorage ) {
if ( k.startsWith('YOUR KRUX PREFIX HERE') ) {
kruxProperties[k] = window.localStorage.getItem(k)
}
}
td.trackEvent('<TD TABLE NAME FOR TRACKING KRUX ID/TD ID map>', kruxProperties);
var successCb = function(tdGlobalId) {
// This is createImage in TDWrapper
var el = document.createElement('img');
el.src = '//beacon.krxd.net/usermatch.gif?partner=treasuredata&partner_uid=' + tdGlobalId;
el.width=1;
el.height=1;
el.style.display='none';
document.body.appendChild(el);
}
function isSafari() {
var ua = window.navigator.userAgent.toLowerCase();
return ua.indexOf('safari') !== -1 && ua.indexOf('chrome') === -1 && ua.indexOf('edge') === -1;
}
if (isSafari() ) {
// TODO: Safari-specific handling due to ITP 2.1
} else {
td.fetchGlobalID(successCb, function(err) { console.log(err) });
}
})(window, document, td);上記のコードサンプルには、Safari ブラウザ向けの Cookie 同期は含まれていません。Safari の Intelligent Tracking Prevention (ITP) 機能により、サードパーティドメインの Cookie ベースの訪問者識別の信頼性が低下しています。私たちはこの問題に対するソリューションを積極的に計画しています。
Integrations Hub > Catalog に移動し、Salesforce DMP を検索して選択します。

Create を選択します。認証済み接続を作成しています。
以下のダイアログが開きます。
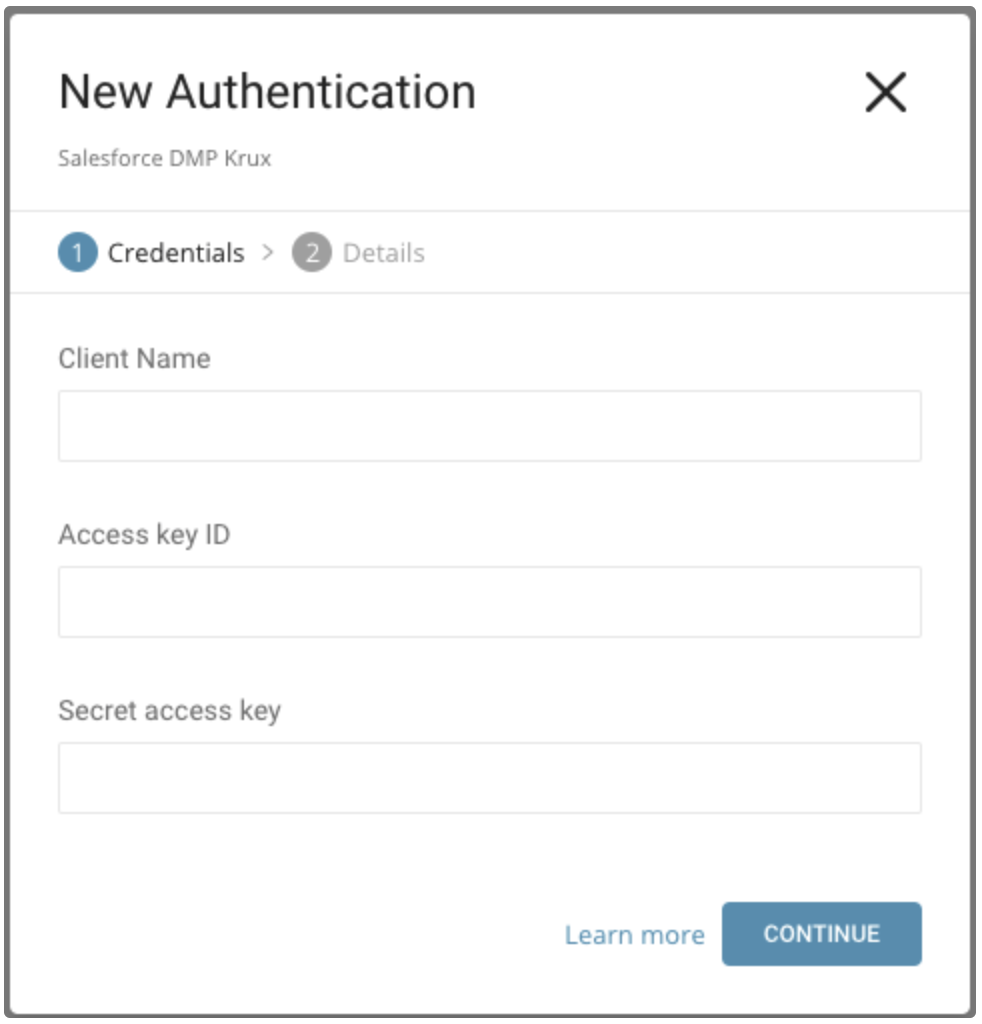
Salesforce DMP から取得したクライアント名、アクセスキーID、およびシークレットアクセスキーを編集します。
Continue を選択します。
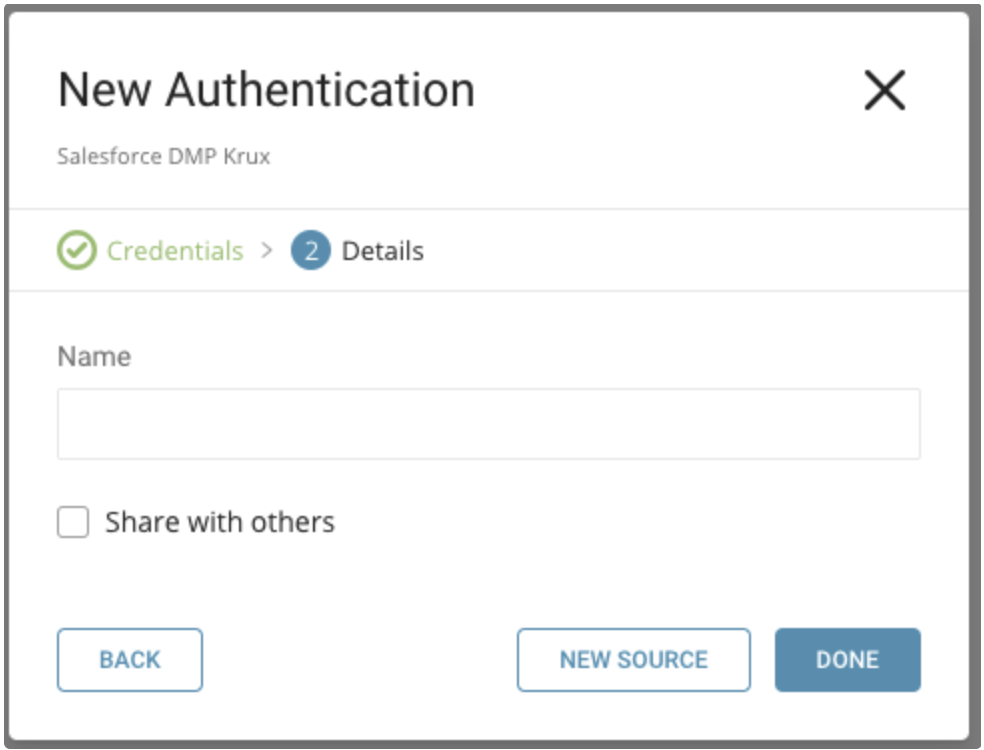
新しい Salesforce DMP 接続に名前を付けます。Done を選択します。
認証済み接続を作成すると、自動的に Authentications タブに移動します。作成した接続を探して New Source を選択します。
インポートするデータを指定します:
- セグメントマッピングファイル
- ユーザーオーディエンスセグメントマップ
- メディアキャンペーン、ペイドサーチキャンペーン、サイトキャンペーン、または不同意リスト
Source には、セグメントマッピングファイルを選択します。
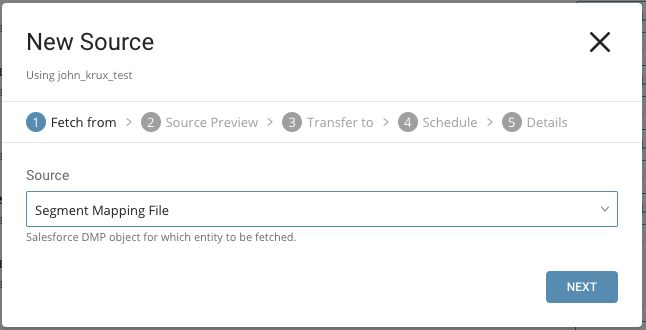
Source には、ユーザーオーディエンスセグメントマップを選択します。
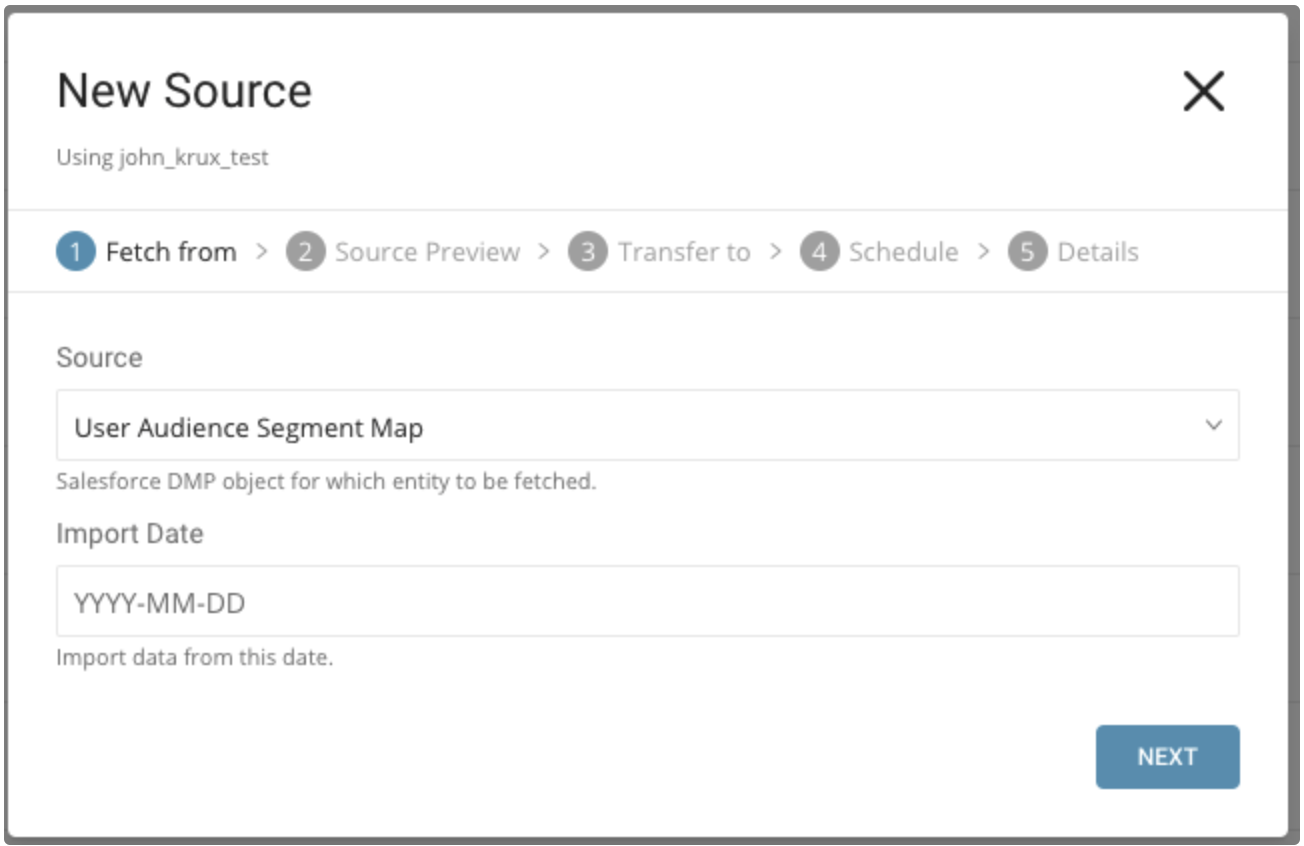
パラメータ:
- Import Date: この日付から作成されたデータをインポートします。
Source には、メディアキャンペーン、ペイドサーチキャンペーン、サイトキャンペーン、または不同意リストを選択します。
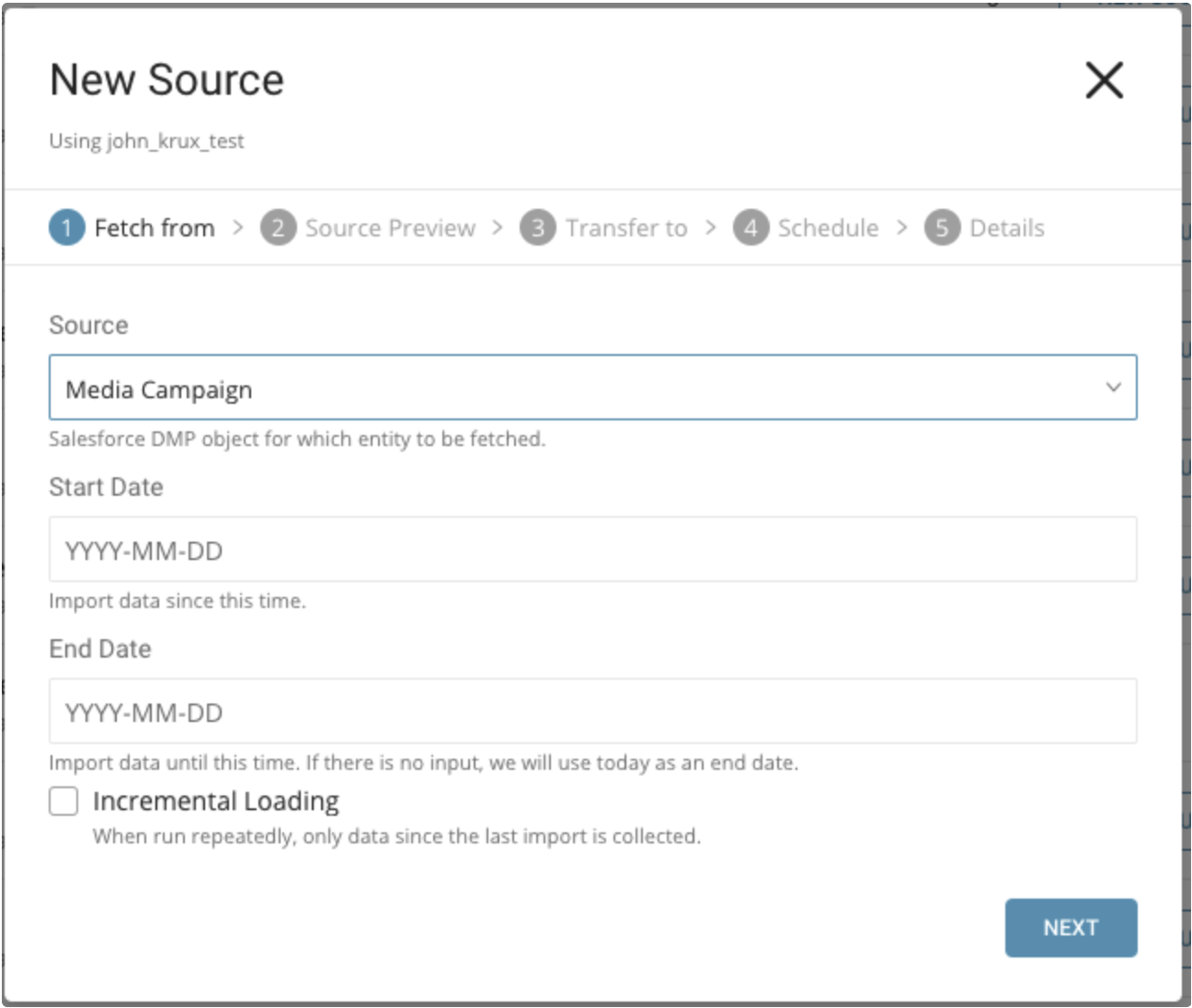
パラメータ:
- Start Date: この日付以降に作成されたデータをインポートします。
- End Date: この日付までに作成されたデータをインポートします。
- Incremental Loading: スケジュールに基づいてデータをインポートする場合、取得されるデータの時間枠は実行ごとに自動的に前進します。例えば、初期の開始日を1月1日、終了日を1月10日に指定した場合、最初の実行では1月1日から1月10日までのデータを取得し、2回目の実行では1月11日から1月20日までのデータを取得するといった具合です。
データプレビューはオプションであり、必要に応じて Next をクリックしてダイアログの次のページに進むことができます。
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示します。
データプレビューに表示されるデータは、ソースから近似されたものです。実際にインポートされるデータではありません。
データが期待通りであることを確認します。
Next を選択します。
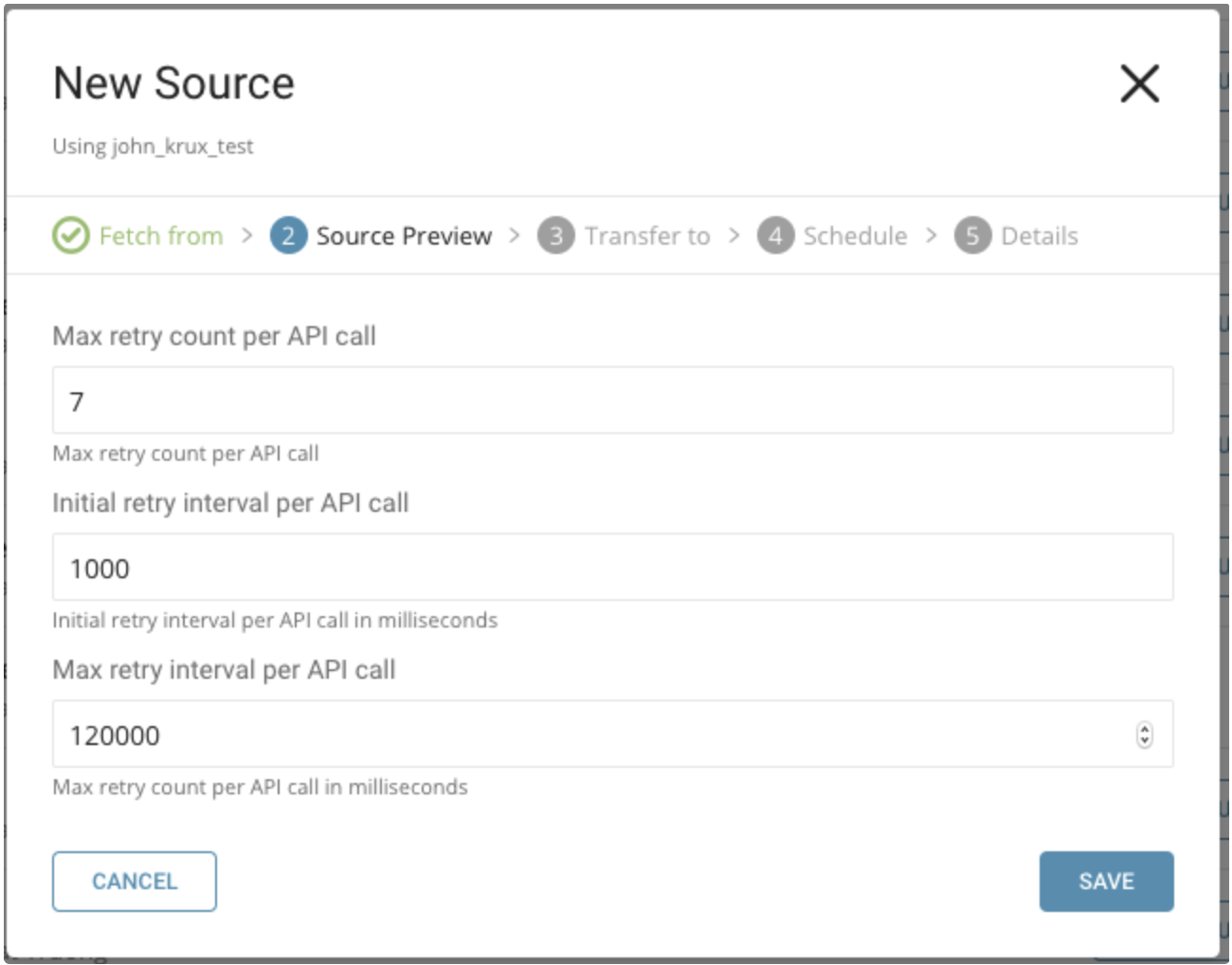
以下のパラメータを指定できます:
- Maximum retry times. 各APIコールの最大リトライ回数を指定します。
- 型: number
- デフォルト: 7
- Initial retry interval millisecond. 最初のリトライの待機時間を指定します。
- 型: number
- デフォルト: 1000
- Maximum retry interval milliseconds. リトライ間の最大待機時間を指定します。
- 型: number
- デフォルト: 120000
既存のものを選択するか、新しいデータベースとテーブルを作成します。
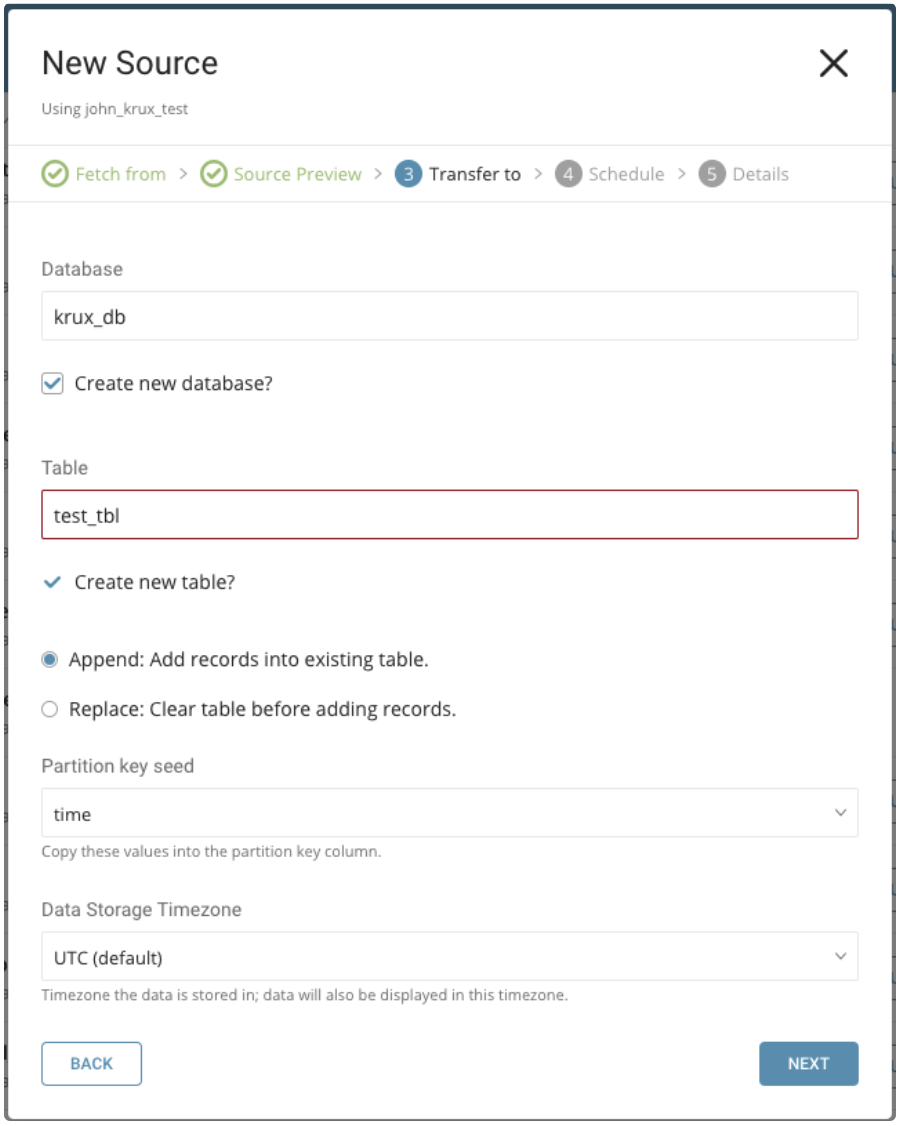
新しいデータベースを作成し、データベース名を付けます。Create new table についても同様の手順を実行します。
既存のテーブルにレコードを append(追加)するか、既存のテーブルを replace(置換)するかを選択します。
デフォルトキーではなく、異なる partition key seed を設定したい場合は、ポップアップメニューを使用して指定できます。
When タブでは、1回限りの転送を指定するか、自動的に繰り返される転送をスケジュールすることができます。
パラメータ
Once now: 1回限りのジョブを設定します。
Repeat…
- Schedule: @hourly、@daily、@monthly の3つのオプションとカスタム cron を使用できます。
- Delay Transfer: 実行時間の遅延を追加します。
TimeZone: 'Asia/Tokyo' などの拡張タイムゾーン形式をサポートしています。
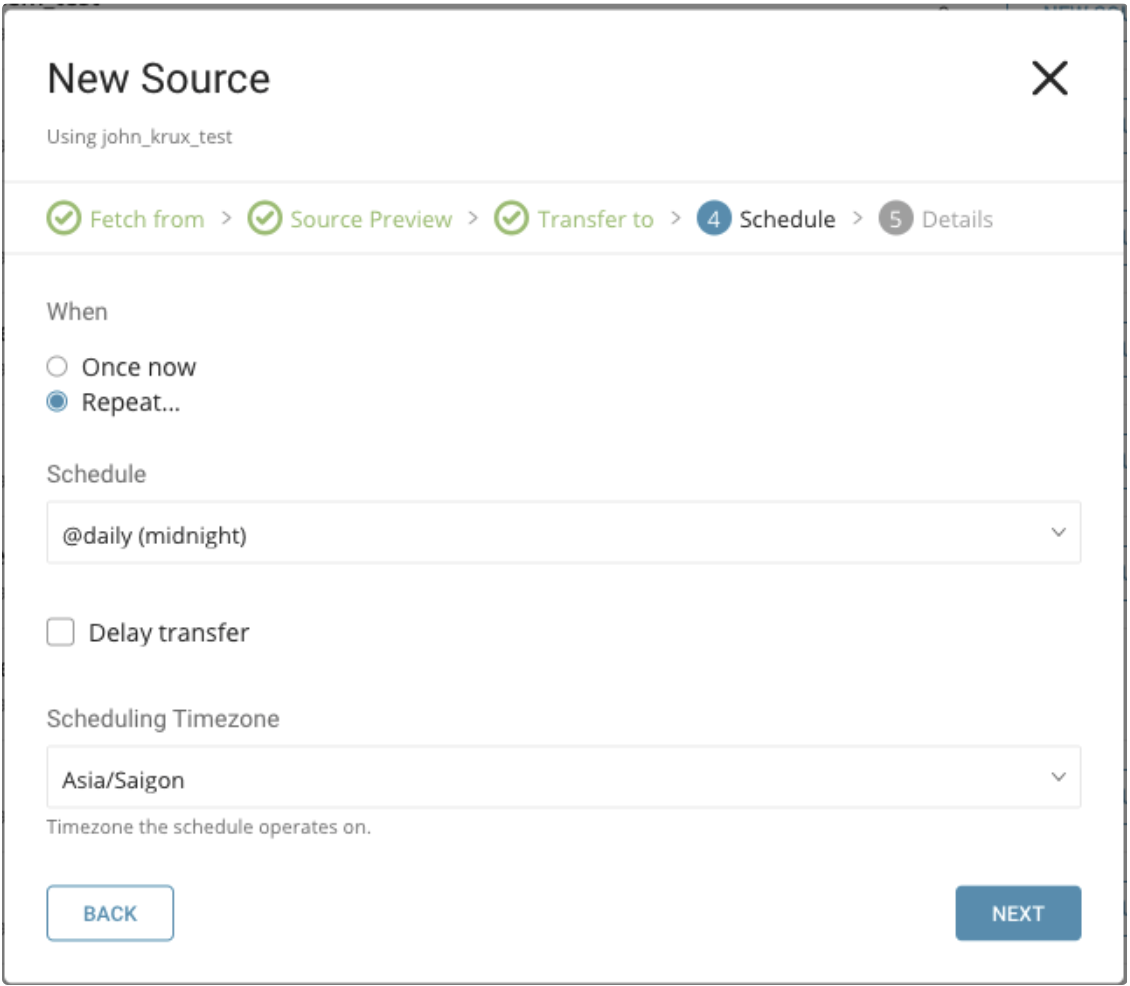
Transfer に名前を付けて Done を選択して開始します。
Transfer の実行後、Databases タブで Transfer の結果を確認できます。
TD Console を使用して接続を設定できます。
最新の TD Toolbelt をインストールします。
設定ファイルには、Salesforce DMP からコネクタに入力される内容を指定する in: セクションと、コネクタから Treasure Data のデータベースに出力される内容を指定する out: セクションが含まれます。利用可能な out モードの詳細については、付録を参照してください。
次の例は、インクリメンタルスケジューリングなしで Media Campaign をインポートする方法を示しています。
in:
type: krux_dmp
access_key_id: xxxxxxxxxxx
secret_access_key: xxxxxxxxxxx client_name: xxxxxxxxxxx
target: mc
start_date: 2019-01-17
end_date: 2019-01-27
incremental: false
out: mode: append次の例は、インクリメンタルスケジューリングありで Media Campaign をインポートする方法を示しています。
in:
type: krux_dmp
access_key_id: xxxxxxxxxxx
secret_access_key: xxxxxxxxxxx
client_name: xxxxxxxxxxx
target: mc
start_date: 2019-01-17
end_date: 2019-01-27
incremental: true
out: mode: append次の例は、インクリメンタルスケジューリングなしで Paid Search Campaign をインポートする方法を示しています。
in:
type: krux_dmp
access_key_id: xxxxxxxxxxx
secret_access_key: xxxxxxxxxxx
client_name: xxxxxxxxxxx
target: psc
start_date: 2019-01-17
end_date: 2019-01-27
incremental: false
out: mode: append次の例は、インクリメンタルスケジューリングありで Paid Search Campaign をインポートする方法を示しています。
in:
type: krux_dmp
access_key_id: xxxxxxxxxxx
secret_access_key: xxxxxxxxxxx
client_name: xxxxxxxxxxx
target: psc
start_date: 2019-01-17
end_date: 2019-01-27
incremental: true
out: mode: append次の例は、インクリメンタルスケジューリングなしで Site Campaign をインポートする方法を示しています。
in:
type: krux_dmp
access_key_id: xxxxxxxxxxx
secret_access_key: xxxxxxxxxxx
client_name: xxxxxxxxxxx
target: sc
start_date: 2019-01-17
end_date: 2019-01-27
incremental: false
out:
mode: append次の例は、インクリメンタルスケジューリングありで Site Campaign をインポートする方法を示しています。
in:
type: krux_dmp
access_key_id: xxxxxxxxxxx
secret_access_key: xxxxxxxxxxx
client_name: xxxxxxxxxxx
target: sc
start_date: 2019-01-17
end_date: 2019-01-27
incremental: true
out:
mode: append次の例は、インクリメンタルスケジューリングなしで Dissent Lists をインポートする方法を示しています。
in:
type: krux_dmp
access_key_id: xxxxxxxxxxx
secret_access_key: xxxxxxxxxxx
client_name: xxxxxxxxxxx
target: dl
start_date: 2019-01-17
end_date: 2019-01-27
incremental: false
out:
mode: append次の例は、インクリメンタルスケジューリングありで Dissent Lists をインポートする方法を示しています。
in:
type: krux_dmp
access_key_id: xxxxxxxxxxx
secret_access_key: xxxxxxxxxxx
client_name: xxxxxxxxxxx
target: dl
start_date: 2019-01-17
end_date: 2019-01-27
incremental: true
out:
mode: append次の例は、User Audience Segment Map をインポートする方法を示しています。
in:
type: krux_dmp
access_key_id: xxxxxxxxxxx
secret_access_key: xxxxxxxxxxx
client_name: xxxxxxxxxxx
target: uasm
import_date: 2019-01-17
out:
mode: append次の例は、Segment Mapping File をインポートする方法を示しています。
in:
type: krux_dmp
access_key_id: xxxxxxxxxxx
secret_access_key: xxxxxxxxxxx
client_name: xxxxxxxxxxx
target: smf
out:
mode: appendtd connector:previewコマンドを使用して、インポートするデータをプレビューできます。
$ td connector:preview load.ymltd connector:issueを使用してジョブを実行します。
ロードジョブを実行する前に、データを保存するデータベースとテーブルを指定する必要があります。例:td_sample_db、td_sample_table
$ td connector:issue load.yml \ --database td_sample_db \ --table td_sample_table \ --time-column date_time_columnTreasure Dataのストレージは時間によってパーティション化されているため、--time-columnオプションを指定することを推奨します。このオプションが指定されていない場合、データコネクタは最初のlong型またはtimestamp型のカラムをパーティショニング時間として選択します。--time-columnで指定するカラムのタイプは、long型またはtimestamp型のいずれかである必要があります(使用可能なカラム名とタイプを確認するには、プレビュー結果を使用してください。一般的に、ほとんどのデータタイプにはlast_modified_dateカラムがあります)。
データに時間カラムがない場合は、add_timeフィルタオプションを使用してカラムを追加できます。詳細については、add_timeフィルタプラグインを参照してください。
td connector:issueは、データベース(sample_db)とテーブル(sample_table)がすでに作成されていることを前提としています。データベースまたはテーブルがTDに存在しない場合、td connector:issueは失敗します。そのため、データベースとテーブルを手動で作成するか、td connector:issueで--auto-create-tableを使用してデータベースとテーブルを自動的に作成する必要があります。
$ td connector:issue load.yml \ --database td_sample_db \ --table td_sample_table \ --time-column date_time_column \ --auto-create-tableコマンドラインから、ロードジョブを送信します。データサイズに応じて、処理に数時間かかる場合があります。
定期的なMedia Campaign、Paid Search Campaign、Site Campaignのインポートのために、データコネクタの定期実行をスケジュールできます。高可用性を確保するために、スケジューラを慎重に構成しています。この機能を使用することで、ローカルデータセンターにcronデーモンを用意する必要がなくなります。
スケジュール実行では、Salesforce DMPからデータを取得する際のデータコネクタの動作を制御する設定パラメータをサポートしています:
incrementalこの設定は、ロードモードを制御するために使用されます。これは、各オブジェクトに関連付けられたネイティブタイムスタンプフィールドの1つに基づいて、データコネクタがSalesforce DMPからデータを取得する方法を管理します。columnsこの設定は、Treasure Dataにインポートされるデータのカスタムスキーマを定義するために使用されます。ここでは、関心のあるカラムのみを定義できますが、取得するオブジェクトに存在することを確認してください。そうでない場合、これらのカラムは結果に含まれません。last_recordこの設定は、前回のロードジョブからの最後のレコードを制御するために使用されます。オブジェクトには、カラム名のkeyとカラムの値のvalueを含める必要があります。keyは、Salesforce DMPデータのカラム名と一致する必要があります。
詳細と例については、「インクリメンタルローディングの仕組み」を参照してください。
td connector:createコマンドを使用して、新しいスケジュールを作成できます。スケジュールの名前、cron形式のスケジュール、データが保存されるデータベースとテーブル、およびデータコネクタ設定ファイルが必要です。
cronパラメータは、次のオプションを受け入れます:@hourly、@daily、@monthly。
デフォルトでは、スケジュールはUTCタイムゾーンで設定されます。-tまたは--timezoneオプションを使用して、タイムゾーンでスケジュールを設定できます。--timezoneオプションは、'Asia/Tokyo'、'America/Los_Angeles'などの拡張タイムゾーン形式のみをサポートしています。PST、CSTなどのタイムゾーンの略語は*サポートされておらず*、予期しないスケジュールにつながる可能性があります。
$ td connector:create \
daily_import \
"10 0 * * *" \
td_sample_db \
td_sample_table \
load.ymlTreasure Dataのストレージは時間によってパーティション化されているため、--time-columnオプションを指定することも推奨されます。
$ td connector:create \
daily_import \
"10 0 * * *" \
td_sample_db \
td_sample_table \
load.yml \
--time-column created_attd connector:listコマンドを入力すると、スケジュールされたエントリのリストを表示できます。
$ td connector:listtd connector:showは、スケジュールエントリの実行設定を表示します。
td connector:show daily_importtd connector:historyは、スケジュールエントリの実行履歴を表示します。個々の実行の結果を調査するには、td job jobidを使用します。
td connector:history daily_importtd connector:deleteは、スケジュールを削除します。
$ td connector:delete daily_importインクリメンタルローディングは、ファイルの最後のインポート日を使用してレコードを単調にロードし、最新の実行後のファイルを挿入または更新します。
最初の実行時、このコネクタはFilename RegexとModified Afterに一致するすべてのファイルをロードします。incremental: trueが設定されている場合、最新の変更日時が新しいModified After値として保存されます。
例:
インポートフォルダに含まれるファイル:
+--------------+--------------------------+ | Filename | Last update | +--------------+--------------------------+ | File0001.csv | 2019-05-04T10:00:00.123Z | | File0011.csv | 2019-05-05T10:00:00.123Z | | File0012.csv | 2019-05-06T10:00:00.123Z | | File0013.csv | 2019-05-07T10:00:00.123Z | | File0014.csv | 2019-05-08T10:00:00.123Z |Filename Regex: File001.*.csv
Modified After: 2019-05-01T10:00:00.00Z
この場合、File0011.csv、File0012.csv、File0013.csv、File0014.csvのファイルがインポートされます。これらはFilename Regexに一致し、すべて最終更新日 > 2019-05-01T10:00:00.00Zです。
ジョブが終了すると、新しいModified After = 2019-05-08T10:00:00.123Zが保存されます。
次回の実行時には、最終更新日 > 2019-05-08T10:00:00.123Zのファイルのみがインポートされます。
例:
インポートフォルダに新しく更新および追加されたファイル:
+--------------+--------------------------+ | Filename | Last update | +--------------+--------------------------+ | File0001.csv | 2019-05-04T10:00:00.123Z | | File0011.csv | 2019-05-05T10:00:00.123Z | | File0012.csv | 2019-05-06T10:00:00.123Z | | File0013.csv | 2019-05-09T10:00:00.123Z | | File0014.csv | 2019-05-08T10:00:00.123Z | | File0015.csv | 2019-05-09T10:00:00.123Z |Filename Regex: File001.*.csv
Modified After: 2019-05-08T10:00:00.123Z
この場合、File0013.csvとFile0015.csvのファイルのみがインポートされます。