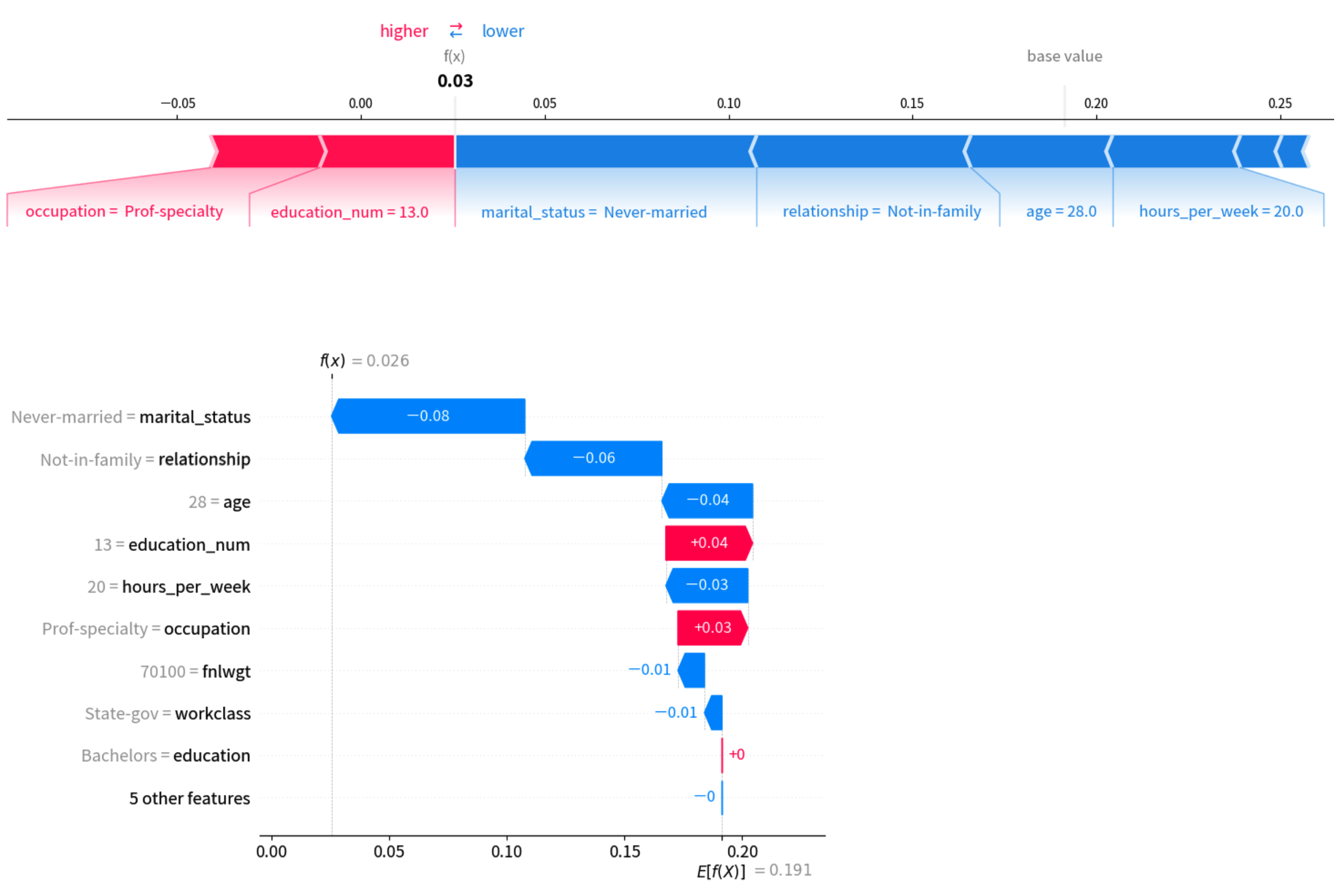
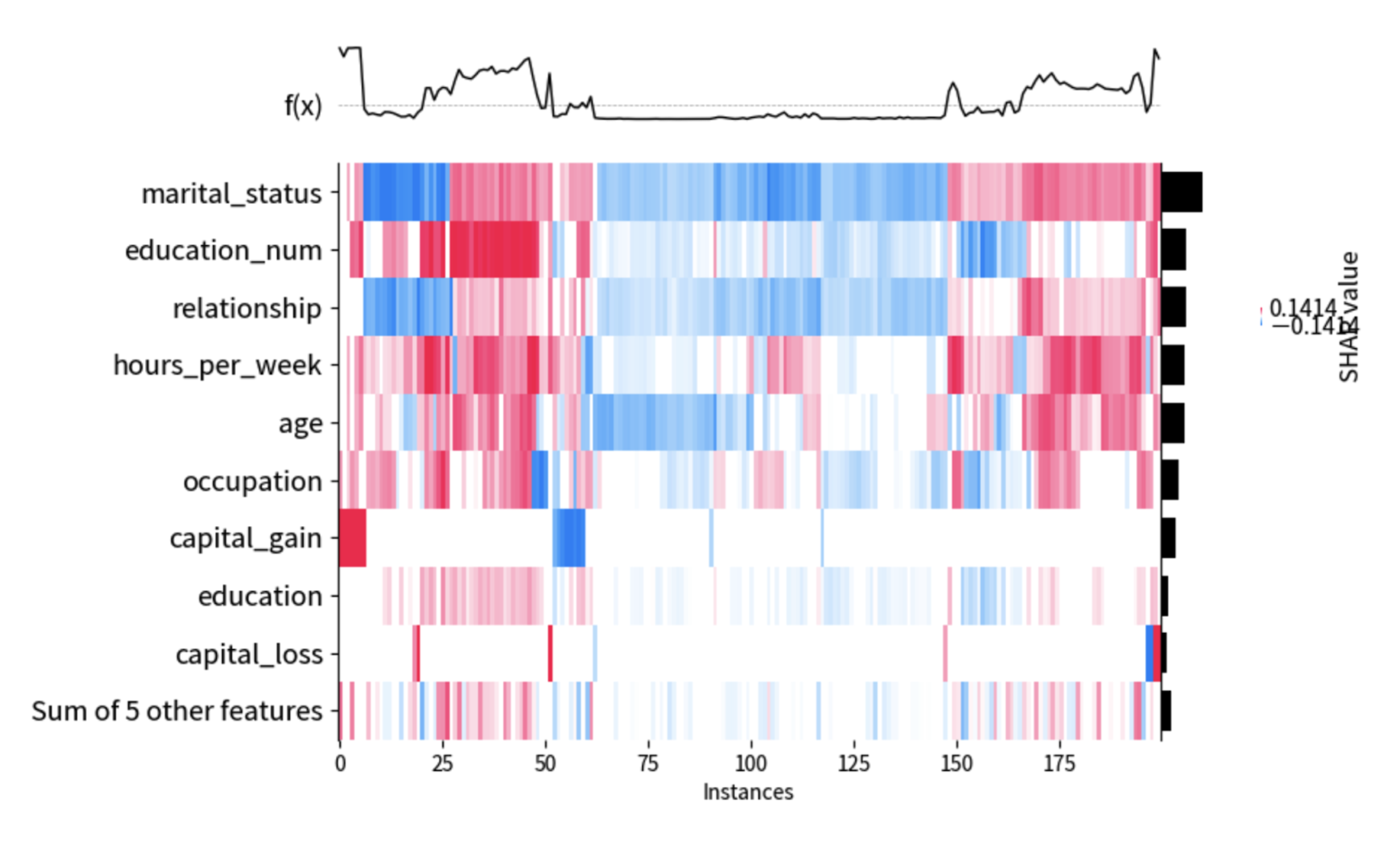
このノートブックは、SHAP(SHapley Additive exPlanations)値を使用して、予測結果における特徴量の相対的な重要度を解釈する方法を示します。SHAP分析の詳細については、こちらのTDブログ記事をご覧ください。
サンプルの可視化は以下の通りです:
 ワークフロー例
ワークフロー例
Treasure Boxesでサンプルワークフローを確認できます。
+explain_predictions_by_shap:
ipynb>:
notebook: shapley
model_name: gluon_model # 予測に使用されるモデル
input_table: ml_test.gluon_test # 予測に使用されるテストデータ| パラメータ名 | コンソール上のパラメータ | 説明 | デフォルト値 |
|---|---|---|---|
| docker.task_name | Docker Task Mem | タスクメモリサイズ。契約プランに応じて、64g、128g(デフォルト)、256g、384g、512gから選択可能 | 128g |
| model_name | Model Name | 予測モデル名 | - |
| input_table | Input Table | dbname.table_name形式でTDテーブルを指定 | - |
| shared_model | Shared Model | 共有モデルのUUIDを指定 | None |
| sampling_threshold | Sampling Threshold | サンプリングに使用される閾値。詳細は実行されたノートブックを参照してください。 | 10_000_000 |
| hide_table_contents | Hide Table Contents | テーブルコンテンツの表示を抑制 | false |
| explain_threshold | Explain Threshold | Shapley値を説明する行数 | 200 |
| interpret_samples | Interpret Samples | 予測を解釈するためのサロゲートモデルを構築するサンプル数 | 100 |
| export_shap_values | Export Shap Values | Shapley値をTDテーブルとしてエクスポート | None |