オーディエンススタジオでは、マーケターは属性ベースのルールを使用してセグメントを手動で作成し、どの顧客がどのセグメントに属するかを決定できます。これは、マーケターが特定のターゲットキャンペーン向けにペアレントセグメントを異なるグループに分割する方法を正確に把握している場合に有用です。
場合によっては、マーケターはセグメントの自動作成から恩恵を受けることがあります。このクラスタリングノートブックは、k-meansクラスタリングを使用して、顧客の属性に基づいて顧客をグループ化し、顧客セグメントを形成します。このノートブックは、最小クラスタ数と最大クラスタ数の間で複数回クラスタリングを試行し、平均シルエット係数を最大化する理想的なクラスタ数を見つけます。または、自動計算を上書きするために特定のセグメント数を指定することもできます。
このソリューションノートブックは主に顧客セグメンテーションを目的としていますが、一般的なk-meansクラスタリングを実行し、顧客セグメンテーションからアイテムセグメンテーションまで、あらゆる種類のセグメンテーションに適用できます。
このノートブックは、k-meansクラスタリングを使用して input_table に基づいて自動的にセグメント化します。cluster_id が input_table の各行に割り当てられ、拡張されたテーブルは output_table オプションを使用してTreasure Dataテーブルにエクスポートできます。
最適なクラスタ数は、min_clusters と max_clusters の間でシステムによって自動的に導出され、デフォルト値は上書きできます。希望するクラスタ数が事前にわかっている場合は、num_clusters オプションでクラスタ数を明示的に設定できます。
input_table にはあらゆる種類のテーブルを使用できますが、より良いクラスタリングのために、ignore_columns オプションでrowidやuseridなどの意味のない列を除外することが一般的に推奨されます(このノートブックは単一の値を持つ列を自動的に無視します)。
このノートブックは、feature GINI重要度とShapley値を使用して、ランダムフォレスト分類器によるクラスタリングラベルに対する基本的なEDA(探索的データ分析)とXAI(説明可能なAI)を実行します。
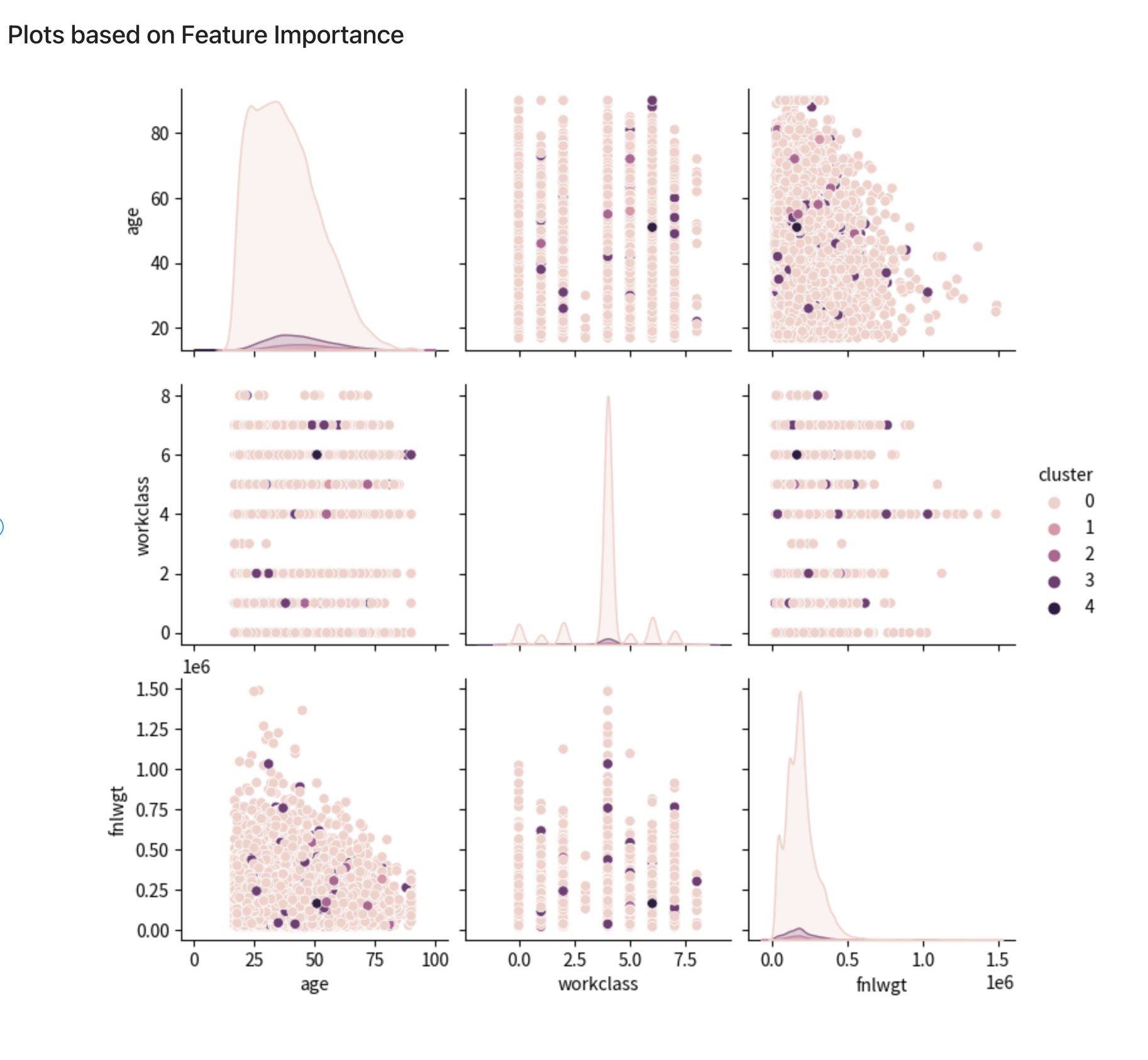
次のプロットグラフは、各クラスタの上位3つの特徴を示しています。
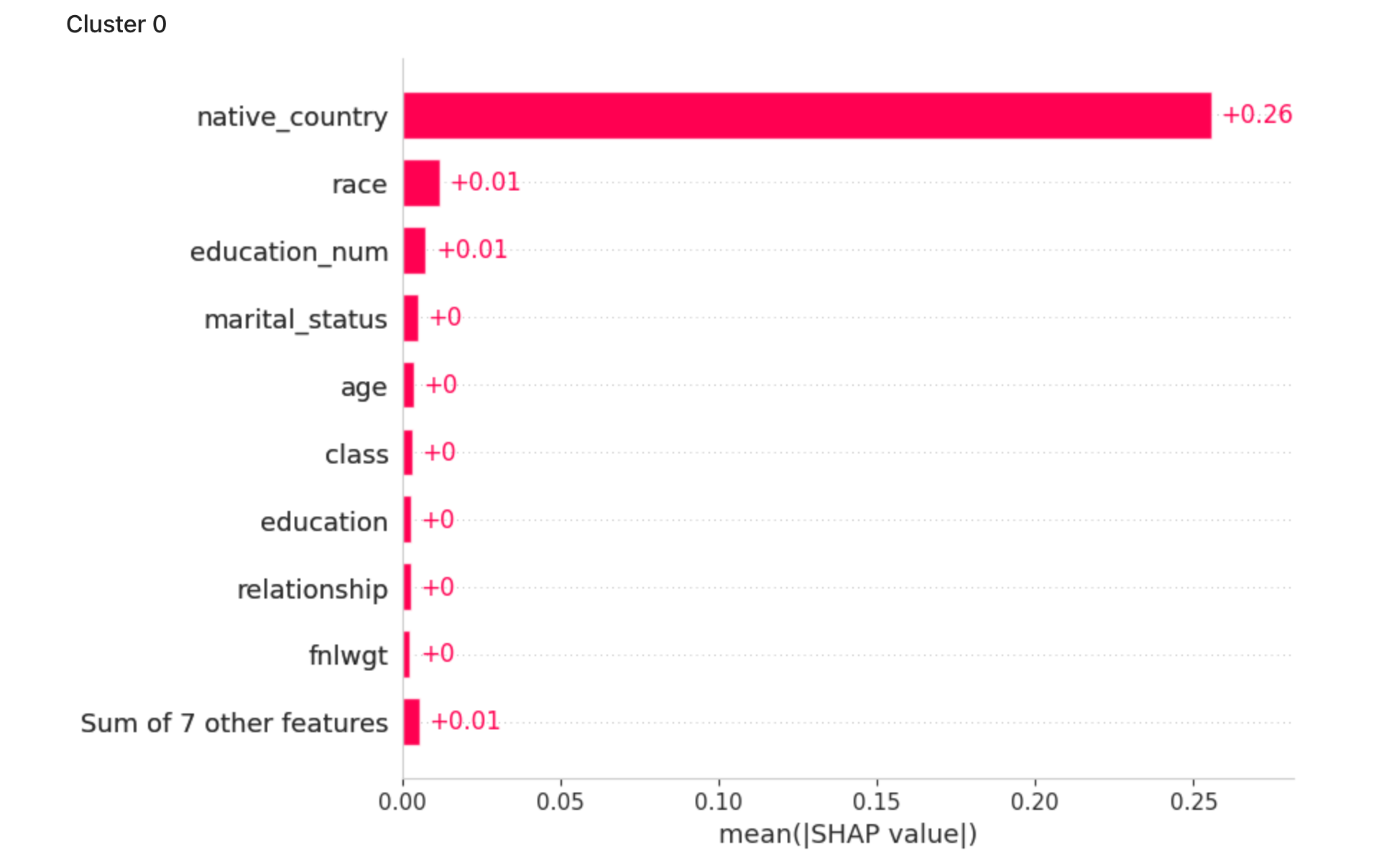
次のプロットは、各クラスタの平均SHAP値を示しています。このグラフは、どの属性がクラスタ割り当てに最も寄与しているかを示しています。
Treasure Boxesでサンプルワークフローをご覧いただけます。
+clustering_gluon:
ipynb>:
notebook: clustering
input_table: ml_datasets.gluon_train
output_table: ml_test.gluon_train_clustered_${session_id}| パラメータ名 | コンソール上のパラメータ | 説明 | 必須 | デフォルト値 | 値の例 |
|---|---|---|---|---|---|
| input_table | dbname.table_name形式でクラスタリングに使用するTDテーブルを指定 | はい | 文字列 (dbname.table_name) | ||
| ml_dataset.gluon_train | |||||
| output_table | dbname.table_name形式でクラスタリング結果をエクスポートするTDテーブルを指定 | いいえ | 文字列 (dbname.table_name) | ||
| ml_output.cluster | |||||
| model_name | オプションで保存するモデル名を指定します。通常は設定する必要はありません。 | いいえ | 文字列 | ||
| gluon_model | |||||
| force_refit | 既存の学習済みモデルがある場合でも強制的に適合します。force_refitをfalseに設定することは 実験的 なオプションであることに注意してください。 | いいえ | ブール値 | true | true |
| output_mode | output_tableをエクスポートするための出力モード。通常、指定する必要はありません。 | いいえ | 文字列 (overwrite/replace または append) | overwrite | overwrite |
| min_clusters | 最小クラスタ数を指定 | いいえ | 整数 | 2 | 5 |
| max_clusters | 最大クラスタ数を指定 | いいえ | 整数 | 9 | 25 |
| num_clusters | 固定クラスタ数を指定 | いいえ | 整数 | None | 3 |
| ignore_columns | 予測モデル構築時に無視する列 | いいえ | 文字列 (カンマ区切り) | time | time, rowid |
| dimension_reduction_threshold | 次元削減に使用される閾値。 | いいえ | 整数 | 50 | 30 |
| export_feature_importance | 指定した場合、特徴量重要度をTDテーブルとしてエクスポートします。 | いいえ | 文字列 ([dbname.]table_name) | None | ml_test.feature_importance |
| export_shap_values | 各クラスタのSHAP値をTDテーブルとしてエクスポート | いいえ | 文字列 ([dbname.]table_name) | None | ml_test.shap_values |
| hide_table_contents | テーブルの内容の表示を抑制 | いいえ | ブール値 | false | false |
| audience_name | 属性テーブルをマージするオーディエンス名 | いいえ | 文字列 | None | my_master_segment_name |
| foreign_key | オーディエンス統合に使用されるマスターセグメントの外部キー列名。 | いいえ | 文字列 | None | td_canonical_id |
| rowid_column | input_table内のrowid(主キー)列。オーディエンス統合のための属性テーブル結合キーとして必要であり、使用されます。 | いいえ | 文字列 | None | userid |
オーディエンス統合 CDPマスターセグメントに属性テーブルを追加するには、3つのオプションすべてを設定してください:audience_name、foreign_key、および rowid_column。rowid_column は、オーディエンスマスターテーブル内で結合される output_table の結合キーです。これらのオプションが設定されると、CDPセグメントは各クラスタに対して自動的に生成されます。マーケターは、オーディエンススタジオのルールビルダーでクラスタルールをさらに変更できます。たとえば、他の属性を使用して、生成されたセグメントを追加のルールと組み合わせることができます。
パラメータ force_refit を false に設定し、事前に計算されたモデル(k-meansセントロイド)を使用することは実験的な機能であり、デフォルトの true オプションから変更することは推奨されません。