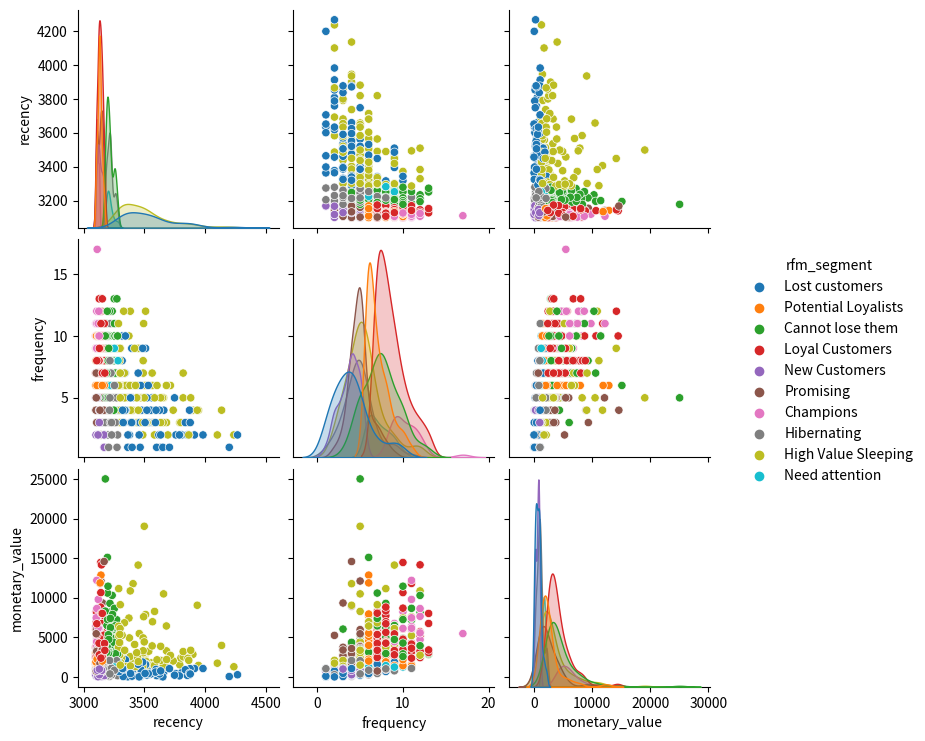
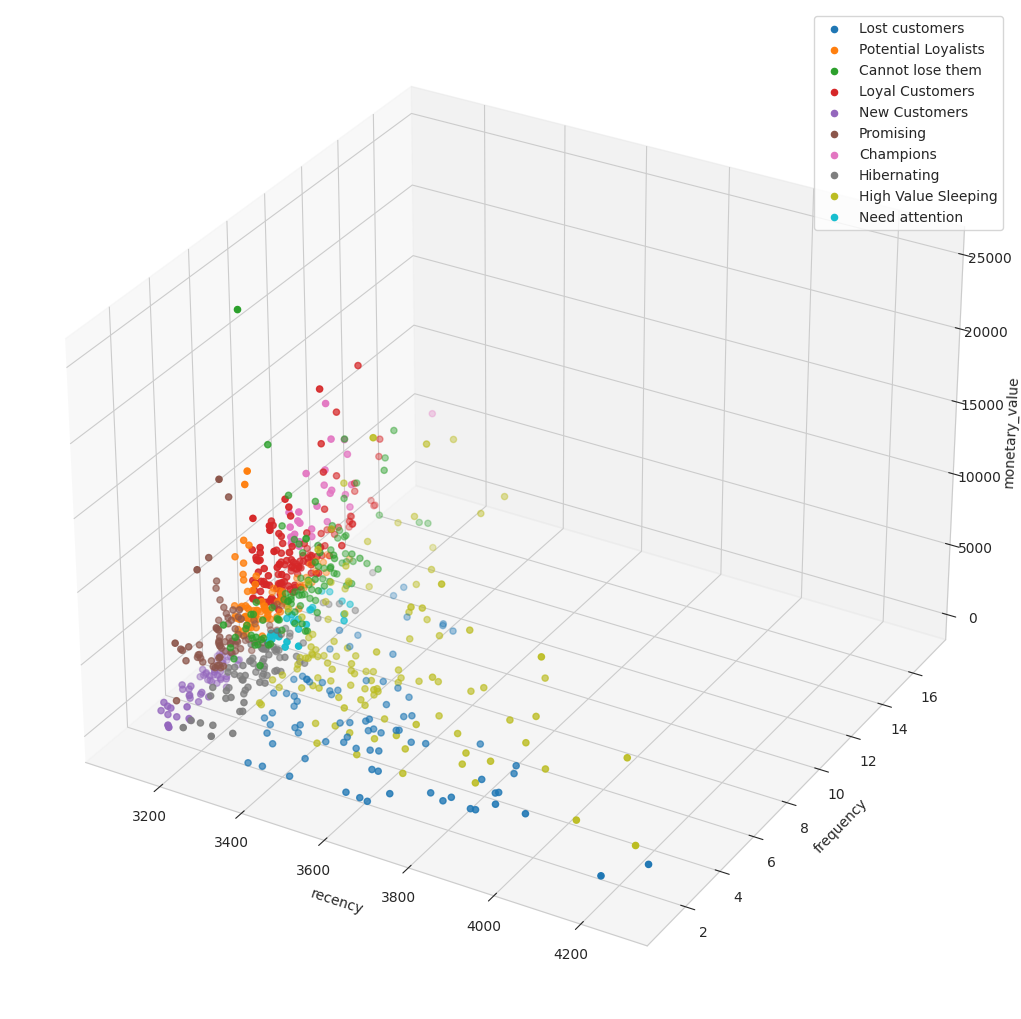
Recency(最終購入日)、Frequency(購入頻度)、Monetary Value(購入金額)(RFM)は、企業の顧客ベースを購入パターンでセグメント化するマーケティング分析モデルです。具体的には、顧客のRecency(最後に購入してからの経過時間)、Frequency(購入頻度)、Monetary Value(支出金額)を評価します。Recency、Frequency、Monetary Valueのそれぞれに対して分位数によるランキングが実行されます。顧客はk-meansアルゴリズムを使用してRFMスコアによってクラスタリングされ、ロイヤリスト、チャンピオン、失われた顧客などのカテゴリに分類されます。
このノートブックは、input_table オプションで指定されたトランザクションテーブルに対してRFM分析を実行します。想定される入力テーブルのスキーマは、パラメータ aggregated_input に依存します。
aggregated_input が False に設定されている場合、input_table のスキーマは次のように想定されます:
| user | tstamp | amount |
|---|---|---|
| 3105285968 | 2011-04-05 | 115 |
| 1850985734 | 2011-11-23 | 1037 |
| 274382808 | 2011-04-25 | 17 |
| 358273144 | 2011-04-02 | 60 |
| ... | ... | ... |
各ユーザーに対して、
- Recencyは最新のtstampからの経過日数によって定義されます
- Frequencyはトランザクション数によって定義されます
- Monetaryは合計金額によって定義されます
Recencyを定義するための基準日として、input_table 内の最大 tstamp 値が使用されます。
aggregated_input が True に設定されている場合、input_table のスキーマは次のように想定されます:
| user | recency | frequency | monetary_value |
|---|---|---|---|
| 3105285968 | 10 | 3 | 200.12 |
| 1850985734 | 20 | 5 | 500.3 |
| 274382808 | 30 | 1 | 50.4 |
| ... | ... | ... |
aggregated_inputがFalseの場合、欠損値処理が実行されます。`aggregated_inputがTrueの場合、欠損値処理は実行されないため、事前に自分で前処理を行う必要があります。
recency、frequency、monetary_value のそれぞれに対して分位数によるランキングが実行されます。r_quartile/f_quartile/m_quartileの分位数ランクは1から4の範囲で、値が高いほど良好です。RFMスコアは (r_quartile + f_quartile + m_quartile) / 3 によって定義されます。
サンプル output_table:
| 61612 | 3181 | 4 | 4115 | 3 | 1 | 4 | R3F1M4 | 2.6667 | Promising | 0 | R3F2M2 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 9549 | 3227 | 8 | 1456 | 2 | 3 | 2 | R2F3M2 | 2.3333 | Need attention | 1 | R1F1M1 |
| 21495 | 3326 | 6 | 2770 | 1 | 2 | 3 | R1F2M3 | 2.0 | High Value Sleeping | 0 | R3F2M2 |
| 39408 | 3290 | 9 | 4893 | 2 | 4 | 4 | R2F4M4 | 3.3333 | Cannot lose them | 0 | R3F2M2 |
| 8120 | 3216 | 5 | 1056 | 2 | 1 | 1 | R2F1M1 | 1.3333 | Hibernating | 1 | R1F1M1 |
| 45110 | 3818 | 2 | 133 | 1 | 1 | 1 | R1F1M1 | 1.0 | Lost customers | 1 | R1F1M1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| user | recency | frequency | monetary_value | r_quartile | f_quartile | m_quartile | rfm_quartile | rfm_score | rfm_segment | rfm_cluster_id | rfm_cluster_rank |
ユーザーはk-meansアルゴリズムを使用してRFMスコアによってクラスタリングされます。rfm_cluster_rank はクラスタの特性を説明します。クラスタサイズが3の場合、クラスタ R3F3M3 は recency、frequency、monetary_value が高く、有望なクラスタであることを表します。一方、R1F1M1 はrecency、frequency、monetary_values が低いことを意味します。
最適なクラスタ数は min_clusters から max_clusters の範囲で自動的に計算されます。num_clusters オプションを設定することで、この計算を上書きできます。
audience_name が指定されている場合、output_table 内の recency、frequency、monetary_values、r_quartile、f_quartile、m_quartile、rfm_score、rfm_segment、rfm_cluster_rank がマスターセグメントの属性列として追加され、rfm_segment と rfm_cluster_rank を使用したセグメントが定義されます。
rfm_segment の名前は、複数のプレイヤーによって使用される業界標準の命名規則に従います。rfm_segment の命名規則については、このツリーマップと疑似コードを参照してください。
10のRFMセグメントの説明については、次の表を参照してください。
| セグメント名 | 説明 | RFM分位数値 |
|---|---|---|
| Champions | 理想的な顧客。最近購入し、頻繁に購入し、最も多く支出しています。 | R4F4M4 |
| Loyal Customers | 多額の支出をしています。プロモーションに反応が良い。これらは非常にアクティブで価値の高い顧客です。 | R4F4M3、R4F3M4、R4F3M3、R3F4M4、R3F4M3、R3F3M4、R3F3M3 |
| Potential Loyalists | 最近の顧客で、適切な金額を支出し、複数回購入しています。 | R4F4M2、R4F3M2、R4F2M4、R4F2M3、R4F2M2、R3F4M2、R3F3M2、R3F2M4、R3F2M3、R3F2M2 |
| Promising | 最近の買い物客で、比較的最近高額で購入したか、頻繁に購入しています。したがって、有望な顧客セグメントです。 | R4F4M1、R4F3M1、R4F2M1、R4F1M4、R4F1M3、R4F1M2、R3F4M1、R3F3M1、R3F2M1、R3F1M4、R3F1M3、R3F1M2 |
| New Customers | 最近購入しましたが、頻繁ではありません。 | R4F1M1、R3F1M1 |
| Cannot lose them | 大きな購入を頻繁に行いましたが、かなり前のことです。このセグメントから大きな収益が得られており、彼らの注意を失わないようにした方が良いでしょう。 | R2F4M4、R2F4M3、R2F3M4、R2F3M3、R2F2M4、R2F2M3、R2F1M4、R2F1M3 |
| Need attention | 潜在的なロイヤリストが注意を失いつつあります。したがって、注意が必要です。 | R2F4M2、R2F3M2、R2F2M2 |
| Hibernating | 低支出、低頻度、かなり前に購入。彼らに注意を払う価値はありません。 | R2F4M1、R2F3M1、R2F2M1、R2F1M2、R2F1M1 |
| High Value Sleeping | 過去の潜在的ロイヤリストが眠っています。失われつつある関心を再び呼び覚ます価値があります。 | R1F4M4、R1F4M3、R1F4M2、R1F3M4、R1F3M3、R1F3M2、R1F2M4、R1F2M3、R1F2M2、R1F1M4、R1F1M3 |
| Lost customers | 最も低いRecency、Frequency、Monetaryスコア。このセグメントは最も優先度が低いです。 | R1F4M1、R1F3M1、R1F2M1、R1F1M2、R1F1M1 |

サンプルワークフローはTreasure Boxesにあります。
+rfm:
ipynb>:
notebook: RFM
input_table: ml_datasets.cosmetics_store
user_column: user_id
tstamp_column: event_time
amount_column: price| パラメータ名 | 説明 | 必須 | データ型 | デフォルト値 | 値の例 |
|---|---|---|---|---|---|
| input_table | dbname.table_nameのような形式でRFM分析に使用するTDテーブルを指定します | はい | string(dbname.table_name) | ||
| ml_dataset.td_rfm | |||||
| user_column | ユーザーのカラム名を指定します | いいえ | string | user | user |
| tstamp_column | タイムスタンプのカラム名を指定します | いいえ | string | tstamp | time |
| amount_column | 購入金額などのトランザクション金額のカラム名を指定します | いいえ | string | amount | purchase_amount |
| output_table | RFM結果をエクスポートするTDテーブルをdbname.table_nameとして指定します | いいえ | string(dbname.table_name) | ||
| ml_output.rfm | |||||
| min_clusters | クラスタの最小数を指定します | いいえ | integer | 2 | 5 |
| max_clusters | クラスタの最大数を指定します | いいえ | integer | 8 | 25 |
| num_clusters | クラスタの固定数を指定します | いいえ | integer | None | 3 |
| hide_table_contents | テーブルコンテンツの表示を抑制します | いいえ | boolean | false | false |
| audience_name | 属性テーブルをマージするためのオーディエンス名 | いいえ | string | None | master_segment_name |
| foreign_key | オーディエンス統合に使用されるマスターセグメントの外部キーカラム名。設定されていない場合はuser_column値が使用されます。 | いいえ | string | None | td_canonical_id |
| disable_clustering | クラスタリングを無効にします | いいえ | boolean | false | false |
| aggregated_input | 集約されたテーブルの入力を許可します | いいえ | boolean | false | false |