このドキュメントでは、_インクリメンタル予測_の実装方法について説明し、低レイテンシ要件に対応するためのベストプラクティスを提供します。
予測には3つの主なパターンがあります:
- オンライン
- オフライン
- インクリメンタル
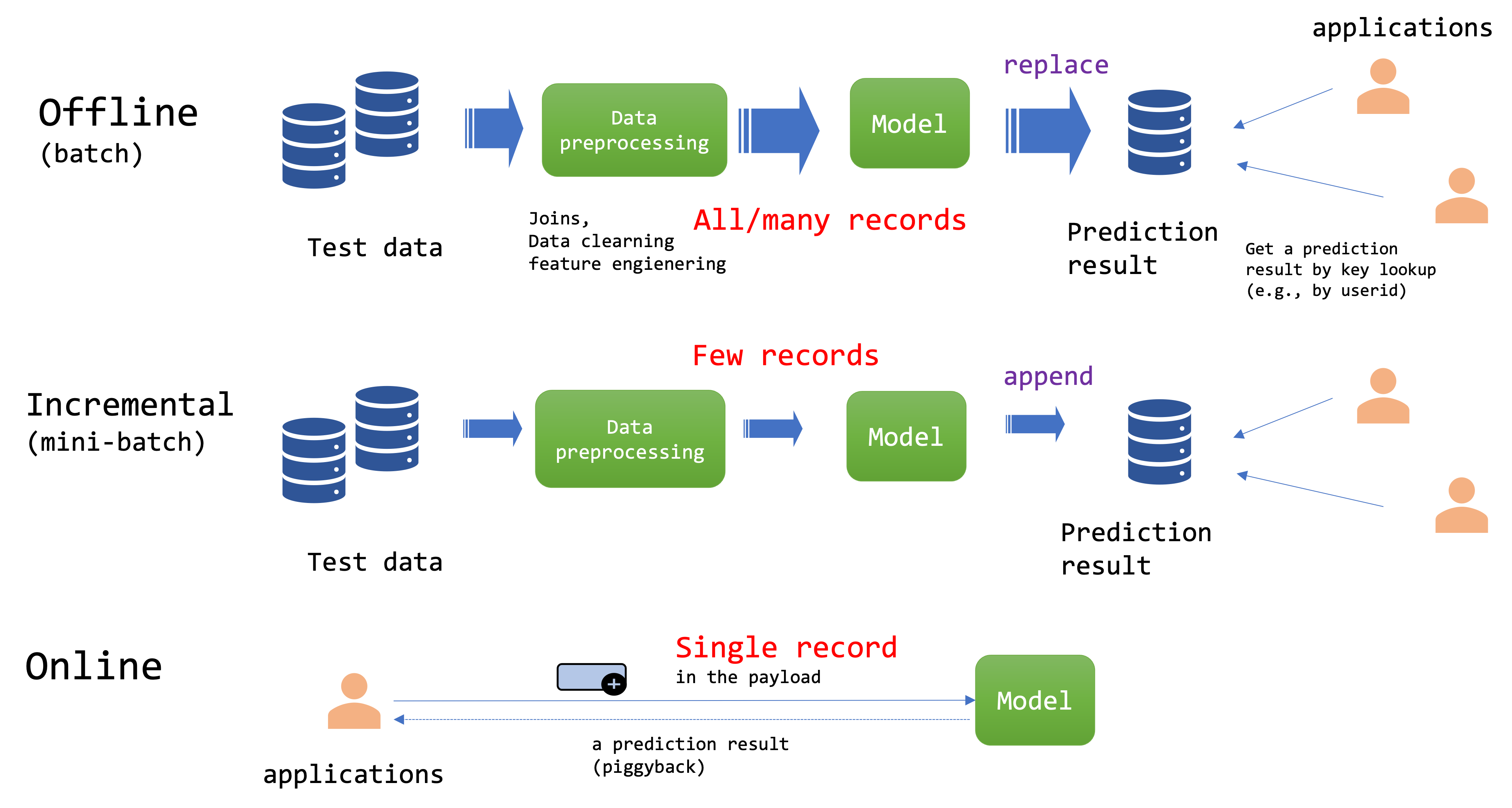
- オンライン予測: 通常、JSON形式のレコードを入力として受け取り、予測結果を返すREST APIとして実装されます。各予測の完了にかかる時間は、ミリ秒から秒単位です。各APIコールのレスポンスは、例えばCookie IDからユーザー属性を解決するなど、複数のJOINが必要になるため、計算が複雑になる可能性があります。アンサンブルモデルは、REST APIコールの低レイテンシ要件を満たせない場合があります。
- オフライン予測: 通常、日次バッチジョブとしてスケジュールされます。予測のための高いスループットを実現できますが、一般的に各バッチの予測を完了するのに数十分から数時間かかります。
- インクリメンタル(ミニバッチ)予測: バッチ予測と似ていますが、タスクをより小さなバッチに分割できる点が異なります。各ミニバッチの予測を完了するのに数秒から数分かかります。厳密なリアルタイム要件には適用できませんが、数分のレイテンシが許容されるセミリアルタイムのシナリオには適用できます。
予測結果をキーバリューストアに保存する場合、レイテンシをミリ秒単位にすることが可能です。
インクリメンタルミニバッチ予測を実装する
保険商品の営業コールバックをリクエストした新規ユーザーにスコアを割り当てるユースケースを考えてみましょう。ただし、ユーザー数が多く、予測されたLTV(顧客生涯価値)スコアによって優先順位をつける必要があります。
5分間のバッチごとに多くの新規顧客を処理する必要があり、一部の既存顧客には追加のレコードがある場合があります。そのため、過去5分間にアクセスしたユーザーの新しいLTVスコアを計算することが期待されます。予測は、次のバッチが開始される前の5分以内に完了する必要があります。
予測結果が${predicted_table}に保存されていると仮定すると、次のSQLクエリを使用して、最新のLTVスコアでソートされたユーザー詳細を取得できます:
各ユーザーの最新LTVスコアを取得する
WITH scores AS (
SELECT
userid,
td_last(time, score) as score # 最新の予測スコアを使用
FROM
${predicted_table}
WHERE
score >= 0.7 -- スコアの閾値でフィルタリング
GROUP BY
userid
)
SELECT
l.userid, l.score,
r.user_name, r.user_age, r.user_email, r.user_tel_no
FROM
scores l
JOIN user_info r ON (l.userid=r.userid)
ORDER BY
score DESC
-- LIMIT 100次のワークフローを使用して、過去5分間にアクセスしたユーザーにLTVスコアを追加するミニバッチ予測をスケジュールできます。
ミニバッチ予測を実行するワークフロー
# 5分ごとに予測を実行
timezone: Asia/Tokyo
schedule:
cron>: */5 * * * *
# 過去5分間にアクセスしたユーザーをリストアップ
+list_users:
td>: queries/list_users.sql
store_last_results: true
# ミニバッチ予測を実行
+gluon_predict:
ml_predict>:
notebook: gluon_predict
model_name: ${model_name}
input_table: ${input_database}.${input_table}
output_table: ${output_database}.${output_table}
output_mode: append # output_tableにスコアを追加
rowid_column: userid
rowid_filter: ${td.last.results.users}${model_name}で指定された予測モデルは、月次ベースで作成され、検証済みの良好なパフォーマンスを持つモデルが予測に使用されることを想定しています。
"queries/list_users.sql"では、過去5分間にアクセスしたユーザーのIDを次のようにリストアップできます:
queries/list_users.sql
SELECT
-- カンマ区切りのユーザーリスト: '111','222'
array_join(transform(array_agg(DISTINCT userid), x -> '''' || x || ''''), ',') as users
FROM
session
WHERE
time >= TD_TIME_ADD(TD_SCHEDULED_TIME(), '-5m', 'JST') -- 過去5分間のアクセス"rowid_column"と"rowid_filter"は、次のSQLクエリを発行するために使用され、一致する行のみが予測に使用されます。
SELECT * FROM ${input_database}.{input_table}
WHERE {rowid_column} in ({rowid_filter})