Treasure Dataには、定期的なクエリ実行をサポートするスケジューラー機能があります。
- 前提条件
- TD Toolbeltを使用した新規スケジュールの作成
- TD Toolbeltを使用したスケジュールジョブの優先度設定
- 例:定期的な集約
- TD Toolbeltを使用したスケジュールの表示
- ジョブの履歴の表示
- スケジュールの更新
- ジョブのスケジュール解除
- スケジュールの削除
TD Toolbeltを含むTreasure Dataの基礎知識
データが格納されているテーブル
新しいスケジュールは、td sched:createコマンドを使用して作成できます。スケジュールの名前、cron形式のスケジュール、クエリ、およびデータベース名が必要です。
$ td sched:create <name> <cron> [sql]options:
-d, --database DB_NAME データベースを使用(必須)
-t, --timezone TZ タイムゾーンの名前。拡張タイムゾーンのみサポート
-D, --delay SECONDS スケジュールの遅延時間
-r, --result RESULT_URL 結果をURLに書き込む(result:createサブコマンドも参照)
-u, --user NAME 結果URLのユーザー名を設定
-p, --password 結果URLのパスワードを要求
-P, --priority PRIORITY 優先度を設定
-q, --query PATH インラインクエリの代わりにファイルを使用
-R, --retry COUNT 自動再試行回数
-T, --type TYPE クエリタイプを設定(hive)例:

ジョブの優先度を変更するには、次を使用します:
td sched:update <job_name> -P <#>
| 優先度 | 構文オプション値 |
|---|---|
| 非常に高い | -P 2 |
| 通常 | -P 0 |
| 非常に低い | -P -2 |
例:
td sched:update 111_beta_query_01 -P 2
一般的なパターンは、メインテーブルから別のテーブルにデータを定期的に要約することです。この例では、アクセスログからのWebリクエスト結果を1時間ごとに集約します。集約の適切な時間範囲を設定するために、Presto(またはHive)のいくつかの一般的な関数を使用しています。
SELECT
USER,
code,
method,
PATH,
agent,
HOST,
AVG(SIZE)
FROM
www_access
WHERE
TD_TIME_RANGE(time,
TD_TIME_ADD(TD_SCHEDULED_TIME(), '-1h'),
TD_SCHEDULED_TIME())
GROUP BY
USER,
code,
method,
PATH,
agent,
HOSTクエリを1時間ごとに実行するように設定を完了するには、スケジュールされたクエリを作成します:
$ td sched:create \
hourly_agg \
"@hourly" \
-d testdb \
-D 1800 \
"SELECT USER, code, method, PATH, agent, HOST, AVG(SIZE) FROM www_access WHERE TD_TIME_RANGE(time, TD_TIME_ADD(TD_SCHEDULED_TIME(), '-1h'), TD_SCHEDULED_TIME()) GROUP BY USER, code, method, PATH, agent, HOST"前述の例では、@hourlyはcronの0 * * * *と同じです。-Dパラメータを使用すると、遅延時間を秒単位で指定できます。この例では、1800秒(または30分の遅延)が設定されています。ジョブは毎時30分後に実行されます。
既存のスケジュールエントリのリストを表示するには、td sched:listを使用します。
td sched:historyは、スケジュールエントリのジョブ履歴を表示します。個々のジョブの結果を調査するには、td job <jobid>を使用します。
定義されたスケジュールに従って実行されるジョブのリストを取得するには、次を使用します:
td sched:list
定義されたスケジュールを持つジョブの1つの履歴を表示するには、次を使用します:
td sched:history <name> [max]
例:
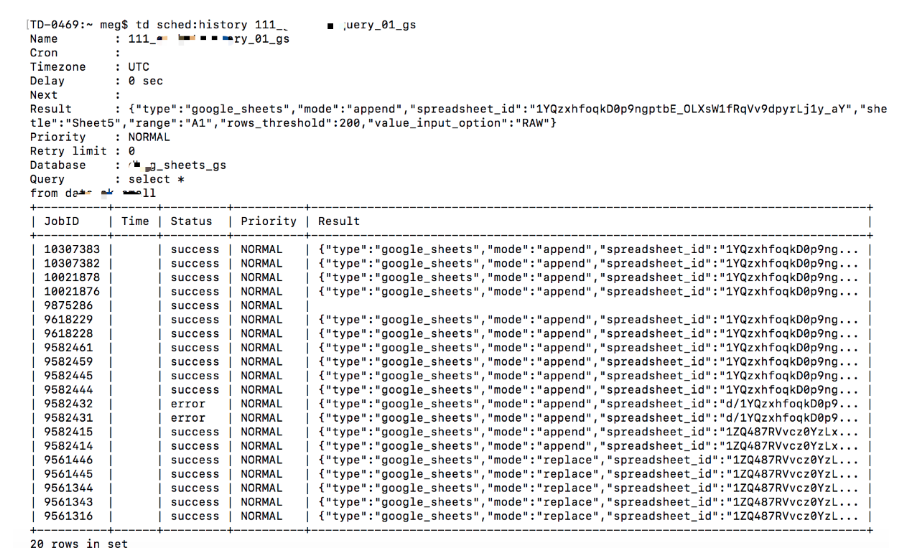
スケジュールされたクエリのほとんどの設定は、いつでも更新または再設定できます。「次回のスケジュール実行時刻」(「次回」または「次回のスケジュール」とも呼ばれます)は、ブラウザのタイムゾーンの現在時刻、cronスケジュール、および遅延設定に基づいて自動更新される推定設定です。
スケジュールされたクエリが更新されると、更新された設定は、「次回のスケジュール実行時刻 + 遅延」(遅延が>0、<0、または0の場合)に発生する次回のスケジュール実行にすぐに適用されます。
td sched:update <name>
例:
td sched:update sched1 -s "0 */2 * * *" -d my_db -t "Asia/Tokyo" -D 3600
options:
-n, --newname NAME スケジュールの名前を変更
-s, --schedule CRON スケジュールを変更
-q, --query SQL クエリを変更
-d, --database DB_NAME データベースを変更
-r, --result RESULT_URL 結果のターゲットを変更(result:createサブコマンドも参照)
-t, --timezone TZ タイムゾーンの名前。拡張タイムゾーンのみサポート
-D, --delay SECONDS スケジュールの遅延時間を変更
-P, --priority PRIORITY 優先度を設定
-R, --retry COUNT 自動再試行回数
-T, --type TYPE クエリタイプを設定(hive)特定のジョブのスケジュールを解除するには、次を使用します:
"* * * * *"の代わりに""
例:
$ td sched:update sched1 -s "" -d my_db -t "Asia/Tokyo" -D 3600
または
$ td sched:create non_scheduled_query "" "select count(*) from www_access" -d sample_datasets
特定のジョブからスケジュールを削除するには、次を使用します:
td sched:delete <name>
例:
$ td sched:delete hourly_count