Treasure Data は、データセットを管理するためにリレーショナルデータベース管理システム(RDBMS)と同じ規約を使用します:
- データベース
- テーブル
- スキーマ
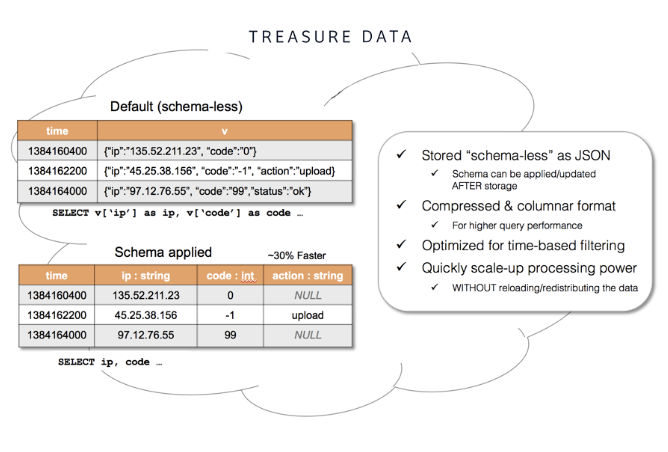
Treasure Data では、スキーマを定義する前にデータを保存できます:
- 従来のウェアハウジングプラットフォーム:プラットフォームはスキーマに依存しており、推測的分析モデルをサポートしています。推測的分析モデルでは、洞察をもたらすと予測されるデータ要素が、データストアスキーマの構造とともに事前に定義されます。
- スキーマ注釈付きデータベース:Treasure Data 内のテーブルにデータをインポートした後にスキーマを割り当てることができます。スキーマの変更は、従来のウェアハウジングプラットフォームへの変更よりも高速に実装されます。さらに、パフォーマンスの考慮事項も初期設計において重要であり、アナリストはクエリのパフォーマンスを確保するために基礎となる構造の知識を持っている必要があります。テーブルに新しい列が追加されると、スキーマを変更する必要があります。
しかし、ビッグデータ分析は主に非推測的です。アナリストは、最初から明らかではなかったデータ内の隠れたパターン、関係、またはイベントを探します。パフォーマンスの考慮事項の負担なしに、データが保存されている場所でクエリを実行でき、探索によって分析の追跡をサポートする新しいレコードの要件が生じる可能性があります。
このモデルスキーマでは、依存関係により、禁止的になる可能性のある大きな負担が追加されます。
このトピックには次が含まれます:
- TD Toolbelt を含む Treasure Data の基本的な知識。
- いくつかのデータを含むテーブル。クエリの実行と結果のダウンロード を参照してください。
TD データベースにテーブルが作成されると、次の列で作成されます:
- time:各エントリが生成された時刻(int64 UNIX time)
カスタムスキーマを定義することを強くお勧めします。さまざまなタイプのデータの列を追加できます。
スキーマを定義する前に、データで使用されるさまざまなデータタイプを特定してください。