まず、AI Agentを定義しましょう。技術的な定義は「人工知能を使用して環境と対話し、タスクを実行するソフトウェアプログラム」です。しかし、それが_何ができるか_を理解することがより重要です。AI agentはデータを収集し、経験から学習し、目標を達成するために意思決定を行います。
このトピックには以下が含まれます:
効果的なシステムプロンプトの書き方のベストプラクティスについては、エージェントシステムプロンプトのベストプラクティスを参照してください。
- TD Consoleを開きます。
- AI Agent Foundryに移動します。
- プロジェクトを選択します。
- Agents Tabを選択し、Create agentを選択します。
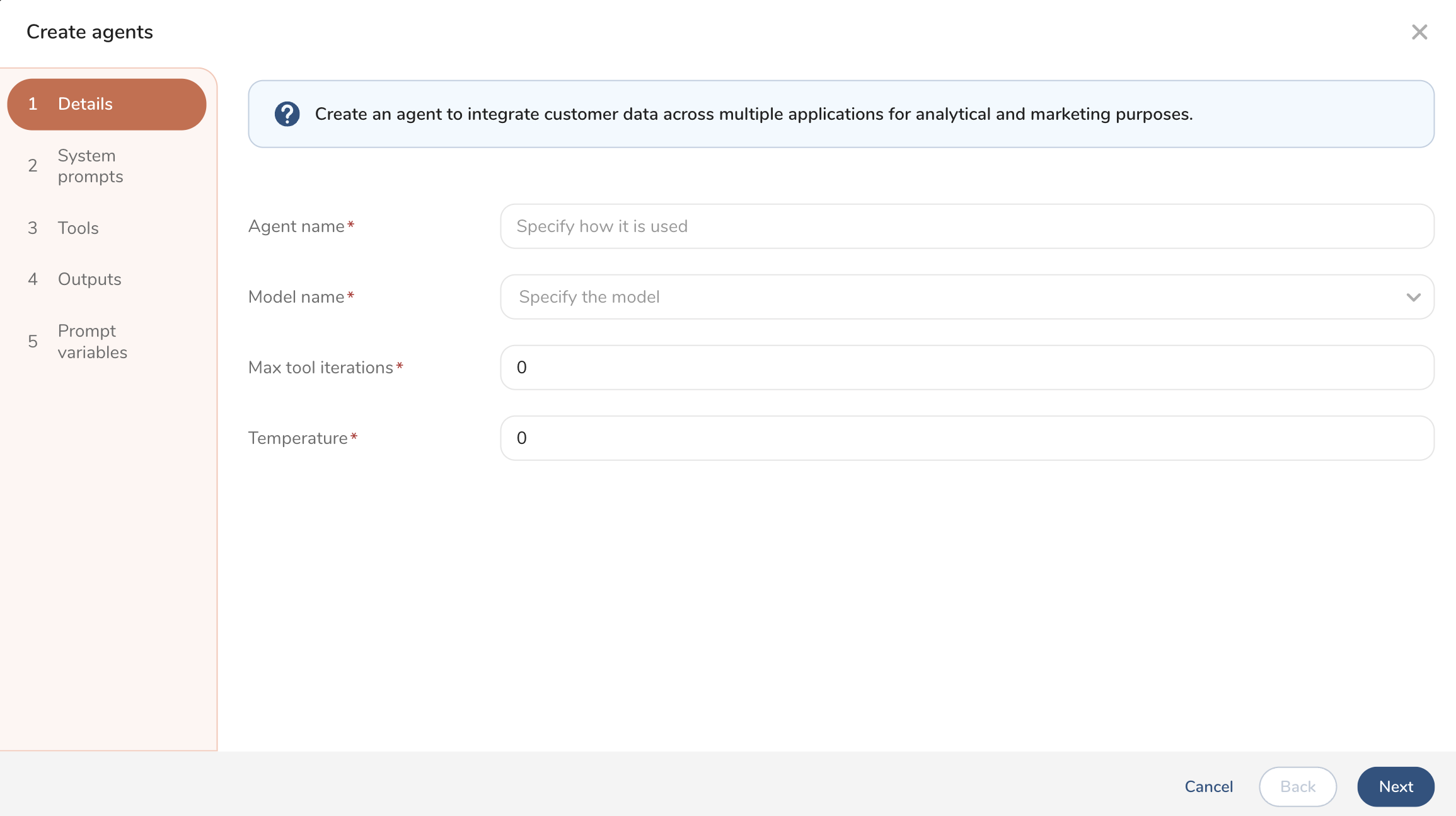
- フォームに入力してagentの詳細を定義します。
| フィールド | 説明 |
|---|---|
| Agent name | ユーザーがagentの用途を理解しやすい名前を作成します。例えば、メールメッセージを書くためのagentを作成し、Email Creatorという名前を付けることができます。 |
| Model name | ドロップダウンリストからモデルを選択します。agentのモデルを特定することで、agentのユーザーに追加情報を提供します。例えば、一部のLLMモデルは高度な推論タスクで優れたパフォーマンスを発揮し、他のモデルは高速応答タスクに優れています。 |
| Max tool iterations | Tool iterationsは、開発サイクルを繰り返すことでtoolを継続的に改良・改善します。agent毎に許可される最大tool iteration数を選択できます。デフォルトは0です。toolsの追加の詳細をご覧ください。 |
| Temperature | temperatureパラメータは、LLMの出力のランダム性を制御します。低い値(例:0.1)は応答をより決定論的にし、高い値(例:0.8)は創造性とバリエーションを高めます。0から1の間の数値を指定します。 |
- Nextを選択します。
System Promptは、LLMモデルがどのように動作するかを自然言語で記述した指示です。構造化された形式で指示することがより適切です。役割、タスク、詳細を定義することで、agentはより期待通りに動作するようになります。
効果的なシステムプロンプトの書き方の詳細なガイダンス(テンプレート、ベストプラクティス、実践的な例を含む)については、エージェントシステムプロンプトのベストプラクティスを参照してください。
- System promptsを選択します。

- テキストボックスにpromptを追加します。
- Nextを選択します。
toolは、knowledge base内のデータの検索やクエリ、他のagentの利用など、agentの機能を表します。
- Toolsを選択し、+ Add toolを選択します。
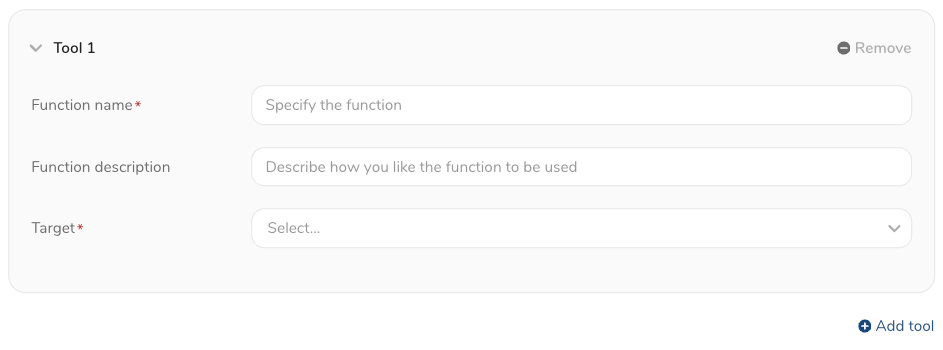
- 関数名と説明を入力します:
- Function Name:関数の一意な名前を入力します。例:list_columns
- Function Description:(オプション)関数の説明を入力します。例:使用可能なテーブルとカラムをリストします。LLMはこの説明を参照します。詳細な説明が定義されていれば、LLMは適切なツールを選択できます。
以下のいずれかを選択します:Knowledge BaseまたはAgent。
データにアクセスしたい場合は、ターゲットとしてKnowledge Baseを選択します。
- ターゲットとしてKnowledge Baseを選択します。
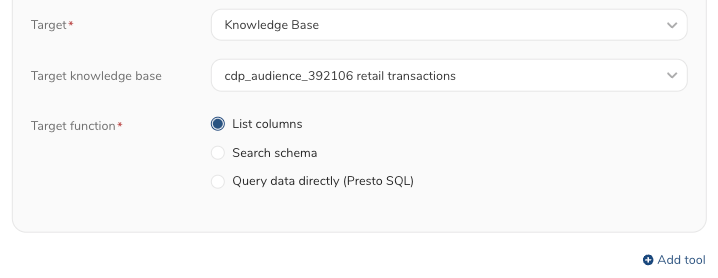
- ドロップダウンリストからKnowledge Base名を選択します。
- ターゲットの関数を選択します:
- List columns:対象のKnowledge Base内のテーブルスキーマをリストします。
- Search schema:検索キーワードでカラムを検索します。
- Query data directly (Presto SQL):SQL文でデータをクエリします。
Textタイプの Knowledge Baseが選択されている場合、サポートされているターゲット関数はreadのみです
Textタイプの Knowledge Baseが選択されている場合、サポートされているターゲット関数はreadのみです
Use runtime text resourceが有効になっている場合、Project Runtime text Resource KBが表示されます。詳細については、Create a Self-Defined Projectを参照してください。
サポートされているターゲット関数は以下の通りです:
- List segment folders:Parent Segmentに存在するフォルダをリストします
- List by folder:特定のフォルダに存在するインスタンスをリストします。これにはフォルダIDが必要です
- List attributes:Parent Segment設定で構成された属性定義を取得します
- List behaviors:Parent Segment設定で構成された行動定義を取得します
- Get segment:特定のセグメントのメタデータを取得します。これにはセグメントIDが必要です
- Get journey:特定のジャーニーのメタデータを取得します。これにはジャーニーIDが必要です
- Get audience:Parent Segment設定のメタデータを取得します。これにはジャーニーIDが必要です
- Get query:特定のセグメントのカウントSQLを取得します。これにはセグメントIDが必要です
- Query data directly:Parent SegmentデータにSQLを発行します
- Query segment analytics:特定のセグメントを分析するためのSQLを発行します。これにはセグメントIDが必要です
関数が特定のインスタンスIDを必要とする場合、agentはそのIDを取得する必要があります。通常、agentは「List segment folders」および/または「List by folder」関数を呼び出すことでIDを取得できます。
Parent Segment Knowledge Baseは、特定のparent segmentによって作成され、それに関連付けられたマネージドプロジェクトに自動的に作成されます。詳細はマネージドプロジェクトの作成を参照してください。
特定のタスクを既存のagentに委任するには、TargetとしてAgentを選択します。
- TargetとしてAgentを選択します。
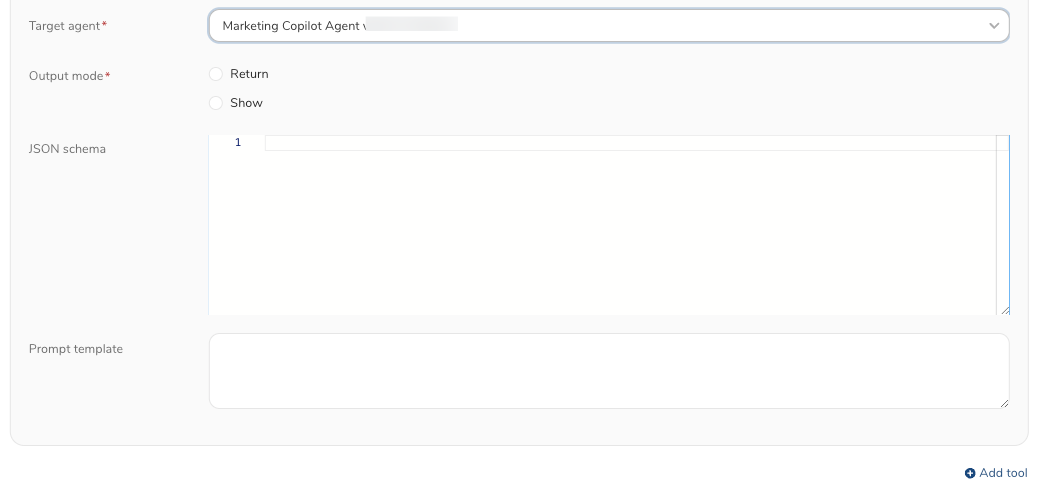
- Target agent: 呼び出すagent。リストからagentを選択します。
- Output mode:
- Return : ターゲットagentは出力を呼び出し元agentに渡し、呼び出し元agentは受け取った出力結果に基づいて生成されたコンテンツを出力します
- Show : ターゲットagentの出力が直接レンダリングされます。
- JSON schema: ツールが呼び出される際の引数構造の定義。
- Prompt template: ターゲットagentが呼び出される際に使用されるユーザープロンプト。"{{parameter_name}}"形式でパラメータを利用できます。_parameter_name_はJSON schemaで定義する必要があります。
Image generatorツールを使用して画像を生成します。
- TargetとしてImage generatorを選択します

- Target image Generator : 使用するimage generator。既存のimage generatorインスタンスから選択します
- Target function :
- Text to Image : テキストプロンプトから画像を作成します。0から1へのケースに適しています
- Outpaint : 指定された領域の周囲を編集します
- Inpaint : 特定領域の内側を編集します
- Image Variation : 与えられた画像から画像のバリエーションを作成します
- Remove Background : 指定された領域の周囲を削除します
Workflow Executorツールを使用してTD workflowを実行します。Workflowはworkflow_idで実行されます。適切なworkflowを実行するには、名前でworkflowを検索し、そのIDを取得してから実行する必要がある場合があります。Search workflowターゲット関数は、agentがworkflowを見つけるのに役立ちます。
Workflowは特定のパラメータで実行できます。システムプロンプトでパラメータのスキーマを定義し、agentがExecute workflowツールを呼び出すときにagentに生成させることができます。
- Workflow Executorを選択します

- Target function :
- Execute workflow : workflow idでworkflowを実行します
- Search workflow : 実行する特定のworkflowを検索します
以下は、Workflow executionツールの使用例です。このagentを実行すると、パラメータを指定してwf_test workflowが呼び出されます。
Outputは、agentがJson schemaの要件を満たすコンテンツを生成する必要がある場合に使用されます。これは、agentが他のagentからツール経由で呼び出される場合に便利です。呼び出し元agentは、呼び出し先agentがoutput関数を定義して呼び出す場合、"return"モードのツールを介して呼び出し先agentから構造化された出力を取得できます。 その他の典型的な使用例は、Ploty.jsライブラリを使用してチャートを描画することです。エージェントが_:plotly:_という名前の出力関数を呼び出すと、チャットインターフェースはPlotly.jsライブラリを使用してチャートを描画します。
エージェントはFunction Nameを使用して出力関数を呼び出すことに注意してください。Output nameはシステムの識別子です。 :plotly:はシステムによって認識される特別な出力名です。
カスタムOutputを作成するには
- Outputsを選択し、次にAdd outputを選択します。

- フォームに入力します。
| フィールド | 説明 |
|---|---|
| Output Name | 一意の名前を入力します。AI Agent Foundryはこの名前を認識に使用します。_:plotly:_はPlotlyチャートのレンダリングに使用される特別な名前です。 |
| Function Name | 関数の名前を入力します。エージェントはこの名前を参照します。 |
| Function Description | (オプション)関数の説明を入力します。 |
| Output Type | CustomまたはArtifactを選択します。
|
| JSON Schema (for Custom) | 出力データ構造のJSON schemaを提供します。エージェントはこの定義に従って出力を作成します。 |
| Artifact | チャット会話から個別のオブジェクトとして出力を永続化します。フォームタイプのインターフェースはartifact出力のみをサポートします。
|

- + Add outputを選択して別の出力を追加するか、Saveを選択してAgentを保存します。
_:plotly:_を以下のように定義します。AgentがnewPlot関数を呼び出すと、plotlyチャートが出力としてレンダリングされます。
| フィールド | 説明 |
|---|---|
| Output Name | :plotly: |
| Function Name | newPlot |
| Function Description | Plotly.jsを使用してチャートをレンダリングします。 |
| JSON Schema | 出力データ構造のJSON schemaの例: |
{
"type": "object",
"properties": {
"data": {
"type": "array",
"description": "Plotly.js data JSON objects",
"items": {
"type": "object"
}
},
"layout": {
"type": "object",
"description": "Plotly.js レイアウト JSON オブジェクト"
}
},
"required": [
"data"
]
}Treasure Data は prompt variables をサポートしています。これは、実行時に必要なデータを system prompt に埋め込むための概念です。
Prompt variables を選択し、次に Add prompt vriable を選択します。
フォームに入力します。

| フィールド | 説明 |
|---|---|
| Variable Name | 一意の名前を入力します。この名前は system prompt 内で参照されます |
| Target knowledge base | 使用する knowledge base 名を入力します |
| Target function | List columns のみ利用可能です |
| List of variables | 対象のテーブルとカラムを指定する式のリスト |
文字列は、式をカンマ区切りで列挙したリストです (expression-1, expression-2, ...)
式は以下のいずれかです:
テーブル名: 式に . や * などの特殊文字が含まれていない場合、それはテーブル名です。TABLE_NAME.* と同じです。
"" を含むパターン: 式に特殊文字が含まれている場合、それはマッチングルールであり、 は任意の文字列にマッチします。
!expression: 式が ! で始まる場合、後続の式を否定します。式は上記のいずれかです。
例
| 例 | 結果 |
|---|---|
customers, behavior_pageviews, behavior_clicks | customers、behavior_pageviews、behavior_clicks テーブルのすべてのカラム。 |
customers.*, behavior_pageviews.*, behavior_clicks.* | 上記と同じ。 |
customers.*, !customers.time, behavior_*.*, products.{id,name}, !*.email | customers テーブルの "time" を除くすべてのカラム、すべての behavior テーブルのすべてのカラム、products テーブルの id と name カラム。ただし、すべてのテーブルから "email" カラムを除外します。 |
次のステップは user prompts. の定義です。