Treasure Data は、td-pyspark ドライバで使用される Plazma Public API の新規ユーザーを受け付けなくなりました。代わりに統合用に pytd ライブラリ を使用してください。
td-pyspark を使用して、Databrick でのデータ操作の結果と Treasure Data のデータをブリッジできます。
Databricks は Apache Spark の上に構築されており、Spark にアクセスするための使いやすいインターフェースを提供します。PySpark は Spark 用の Python API です。Treasure Data の td-pyspark は、td-spark に基づいて PySpark と Treasure Data を使用する便利な方法を提供する Python ライブラリです。
この例の手順に従うには、以下のアイテムが必要です:
Treasure Data API キー
td-spark 機能が有効
クラスタを作成し、td-pyspark ライブラリをインストールし、接続コード用のノートブックを設定します。
Cluster アイコンを選択します。
Create Cluster を選択します。
クラスタ名を指定し、Databricks Runtime Version として Spark 2.4.3 以降のバージョンを選択し、Python Version として 3 を選択します。

追加情報と最新のダウンロードについては、Treasure Data Apache Spark Driver Release Notes にアクセスするか、以下のリンクを選択してください。
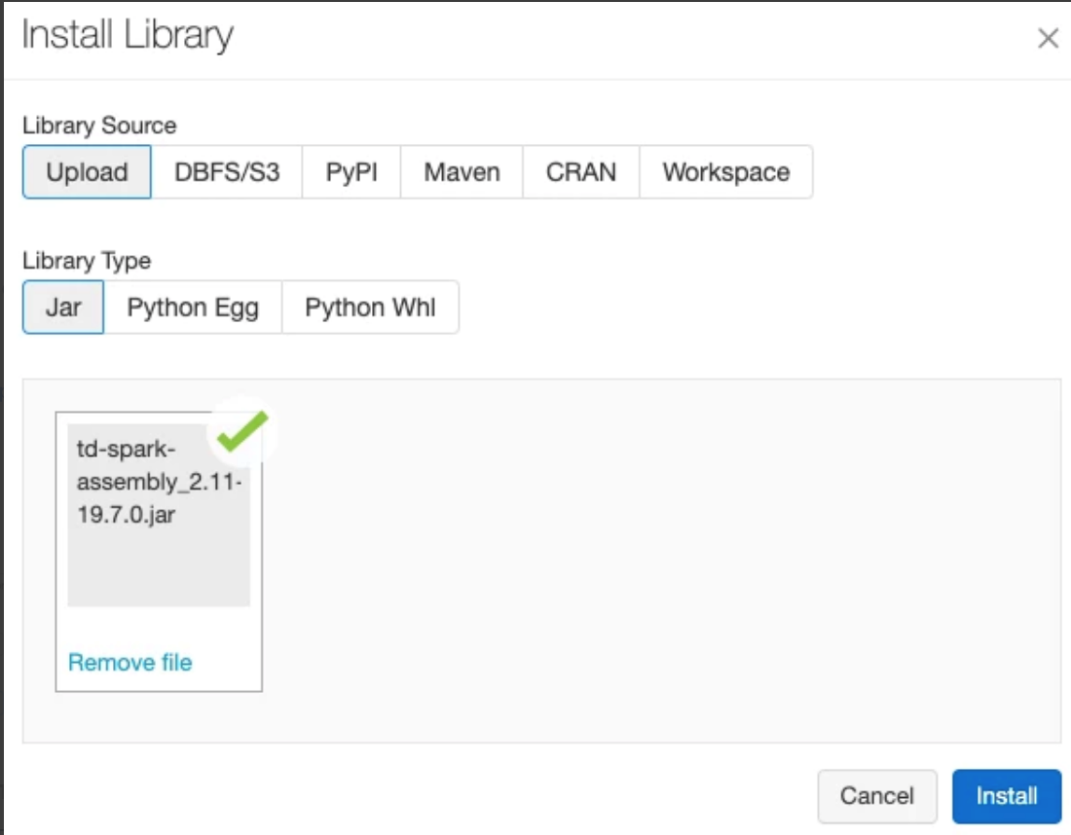
- ダウンロードを選択します
td-spark-assembly-latest_spark2.4.7.jar (Spark 2.4.7、Scala 2.11)
td-spark-assembly-latest_spark3.0.1.jar (Spark 3.0.1、Scala 2.12)
- PyPI を選択します。
ダウンロードが完了すると、次のように表示されます:
Spark 設定で、Treasure Data API キーを指定し、環境変数を入力します。
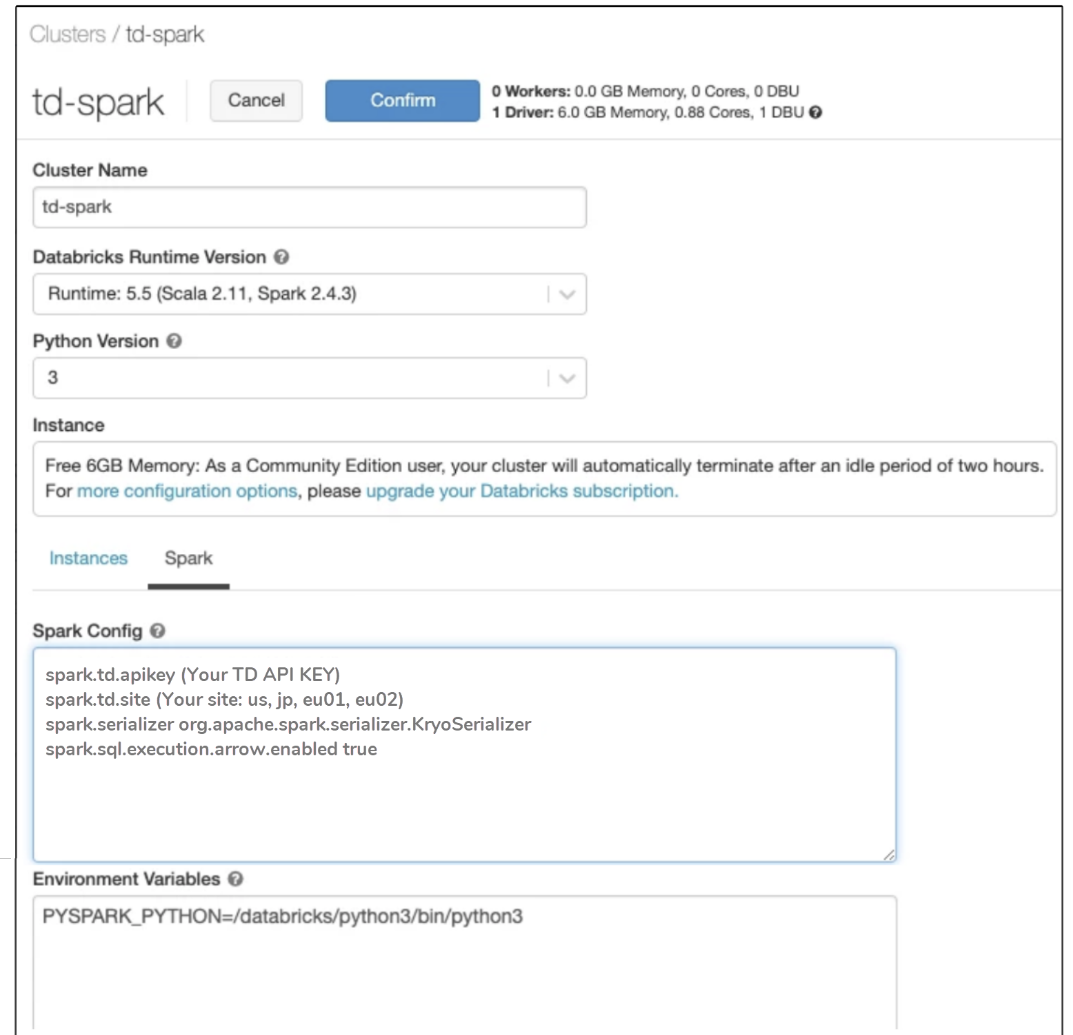
形式の例は次のとおりです。実際の値を指定してください:
spark.td.apikey (TD API KEY)
spark.td.site (サイト: us、jp、eu01、ap02)
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.sql.execution.arrow.enabled trueSpark クラスタを再起動します。ノートブックを作成します。次のコードのようなスクリプトを作成します:
%python
from pyspark.sql import *
import td_pyspark
SAMPLE_TABLE = "sample_datasets.www_access"
td = td_pyspark.TDSparkContext(spark)
df = td.table(SAMPLE_TABLE).within("-10y").df()
df.show()TDSparkContext は、td_pyspark の機能にアクセスするためのエントリポイントです。前述のコードサンプルに示されているように、TDSparkContext を作成するには、SparkSession (spark) を TDSparkContext に渡します:
td = TDSparkContext(spark)次のような結果が表示されます:
接続が機能しています。
Databricks では、Treasure Data に対して select および insert クエリを実行したり、Treasure Data からデータをクエリバックしたりできます。また、データベースとテーブルを作成および削除することもできます。
Databricks では次のコマンドを使用できます:
テーブルを読み込むには、td.table (table_name) を使用します:
df = td.table("sample_datasets.www_access").df()
df.show()コンテキストデータベースを変更するには、td.use (database_name) を使用します:
td.use("sample_datasets")
# sample_datasets.www_access へのアクセス
df = td.table("www_access").df().df() を呼び出すことで、テーブルデータが Spark の DataFrame として読み込まれます。DataFrame の使用法は PySpark と同じです。PySpark DataFrame ドキュメント も参照してください。
df = td.table("www_access").df()Spark クラスタが小さい場合、すべてのデータをインメモリ DataFrame として読み込むのは困難な場合があります。この場合、分散 SQL クエリエンジンである Trino を使用して、PySpark で処理するデータ量を減らすことができます。
q = td.presto("select code, * from sample_datasets.www_access")
q.show()q = td.presto("select code, count(*) from sample_datasets.www_access group by 1")q.show()次のように表示されます:

td.create_database_if_not_exists("<db_name>")
td.drop_database_if_exists("<db_name>")ローカル DataFrame をテーブルとして保存するには、2つのオプションがあります:
入力 DataFrame のレコードをターゲットテーブルに挿入
入力 DataFrame の内容でターゲットテーブルを作成または置換
td.insert_into(df, "mydb.tbl1")td.create_or_replace(df, "mydb.tbl2")td toolbelt を使用してコマンドラインからデータベースを確認できます。また、TD Console をお持ちの場合は、データベースとクエリを確認できます。データベースとテーブル管理 をお読みください。