Treasure Data は、SQL 経由でアクセス可能なクラウドベースの分析インフラストラクチャを提供しています。Trino のようなインタラクティブエンジンを使用すると、数十億のレコードを簡単に処理できます。ただし、データサイエンティストにとって SQL クエリを書くのは時に苦痛であり、結果を視覚化するには Excel や Tableau などの外部ツールを使用する必要があります。Treasure Data を Python ベースのデータ分析ツールである Pandas と組み合わせて使用し、Jupyter Notebook を介してデータをインタラクティブに視覚化できます。
- 前提条件
- Treasure Data API キーの設定
- Treasure Data API エンドポイントの設定
- 必要なパッケージのインストールと環境の設定
- Jupyter の実行と最初のノートブックの作成
- データの探索
- Jupyter でのクエリの実行
- サンプルデータ
Python の基礎知識。
Treasure Data の基礎知識。
Jupyter を起動する前に、マスター API キーを環境変数として設定します。マスター API KEY は、TD Console プロファイルから取得できます。
$ export TD_API_KEY="1234/abcde..."Jupyter Notebook セルで次のようなコマンドを使用して環境変数を設定することもできます。
%env TD_API_KEY = "123c/abcdefghjk..."アカウントが US リージョンに属していない場合は、Treasure Data API エンドポイントを環境変数として設定します。エンドポイント情報はこちらで確認できます。
$ export TD_API_SERVER="https://api.treasuredata.co.jp"Jupyter Notebook セルで次のようなコマンドを使用して環境変数を設定することもできます。
%env TD_API_SERVER = "https://api.treasuredata.co.jp"詳細情報と手順については、Conda、Pandas、matplotlib、Jupyter Notebook、pytd のインストールを参照してください。
分析プロジェクトのフロントエンドとして Jupyter を使用します。
- 次の構文を使用して Notebook を実行します:
(analysis)$ ipython notebookWeb ブラウザが開きます:
New > Python 3 を選択します。
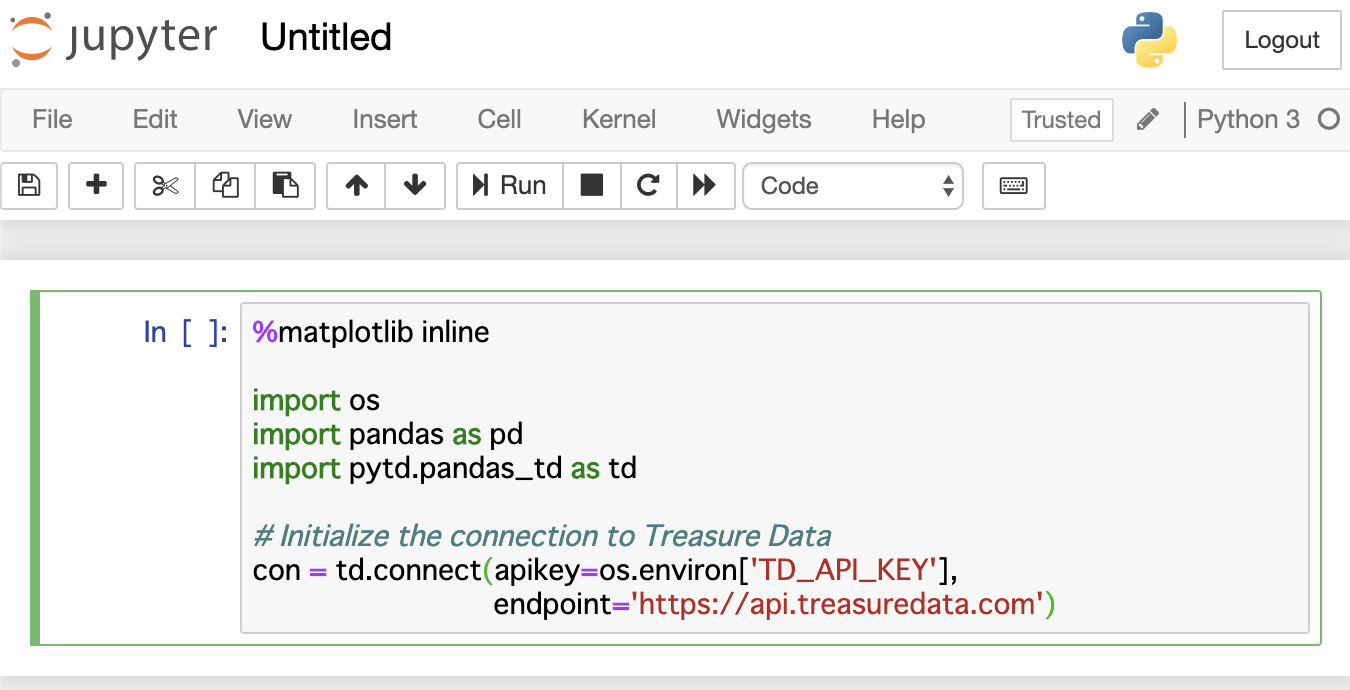
次のテキストをノートブックにコピーして貼り付けます:
%matplotlib inline
import os
import pandas as pd
import pytd.pandas_td as td
# Initialize the connection to Treasure Data
con = td.connect(apikey=os.environ['TD_API_KEY'], endpoint='https://api.treasuredata.com')
- ノートブックは次のようになります
 6. Shift-Enter を押します。 "KeyError: 'TD_API_KEY'" エラーが発生した場合は、"apikey=os.environ['TD_API_KEY']" の代わりに "apikey='your master apikey'" を試してください。 動作する場合、Jupyter は OS からの TD_API_KEY 変数を認識していません。 TD_API_KEY を再度確認し、Jupyter を再起動してください。
6. Shift-Enter を押します。 "KeyError: 'TD_API_KEY'" エラーが発生した場合は、"apikey=os.environ['TD_API_KEY']" の代わりに "apikey='your master apikey'" を試してください。 動作する場合、Jupyter は OS からの TD_API_KEY 変数を認識していません。 TD_API_KEY を再度確認し、Jupyter を再起動してください。
- オプションで、ノートブックを保存します。
sample_datasets には2つのテーブルがあります。magic コマンド td_tables を使用して、データベース内のすべてのテーブルを表示できます。

nasdaq テーブルを探索しましょう。
Jupyter で、次の構文を入力します:
engine = td.create_engine("presto:sample_datasets")
client =td.Client(database='sample_datasets')
client.query('select symbol, count(1) as cnt from nasdaq group by 1 order by 1')例:
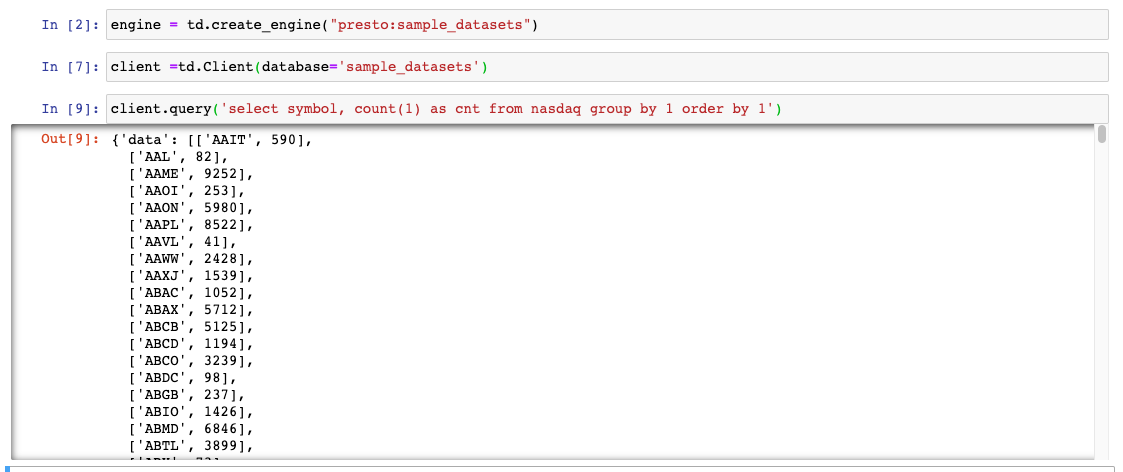
この例の目的上、Trino がこのセッションのクエリエンジンとして使用されます。
Jupyter で、次の構文を入力します:
import pytd.pandas_td as td
con = td.connect(apikey=apikey, endpoint="https://api.treasuredata.com")
engine = td.create_engine("presto:sample_datasets")
td.read_td_query(query, engine, index_col=None, parse_dates=None, distributed_join=False, params=None)time_range パラメータを使用して、特定の時間範囲内のデータを取得することもできます:
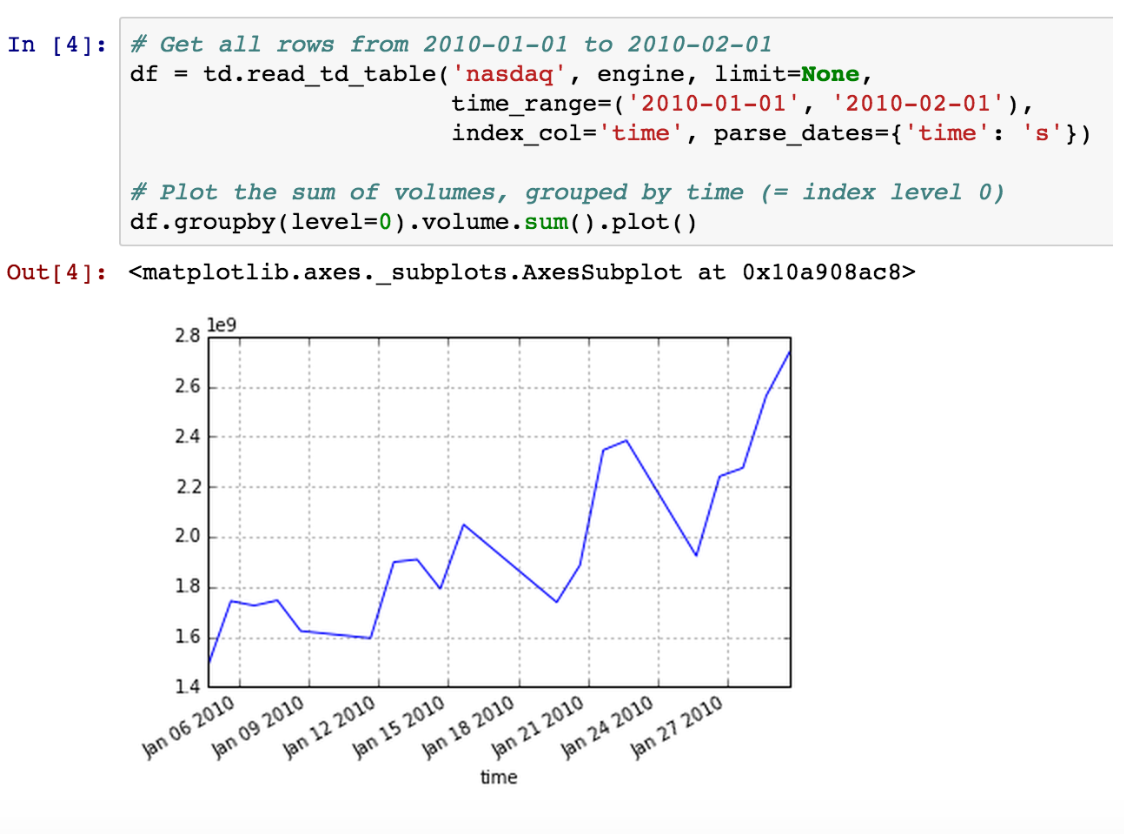
データは DataFrame としてローカル変数 df に格納されます。データはコンピュータのローカルメモリにあるため、Pandas と Jupyter の力を使ってインタラクティブに分析できます。時系列データの詳細については、Time Series / Date functionality を参照してください。
データセットが非常に大きくなると、前のステップの方法はあまり拡張性がありません。メモリの制限や遅いネットワーク転送のため、一度に数百万行以上を取得することはお勧めしません。大量のデータを分析する場合は、転送されるデータ量を制限する必要があります。
これを行うには2つの方法があります:
- データをサンプリングできます。たとえば、「Nasdaq」テーブルには 8,807,278 行があります。100000 の制限を設定すると 100,000 行になり、これは取得するのに妥当なサイズです:

- SQL を記述してサーバー側からデータを制限します。たとえば、「AAPL」に関連するデータのみに興味がある場合、
read_td_queryを使用してレコード数をカウントしましょう:
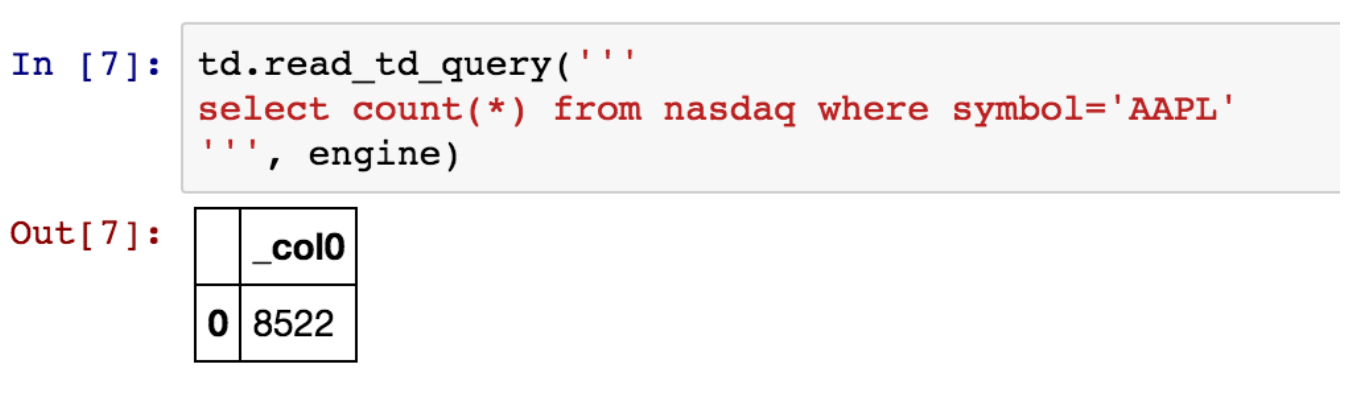
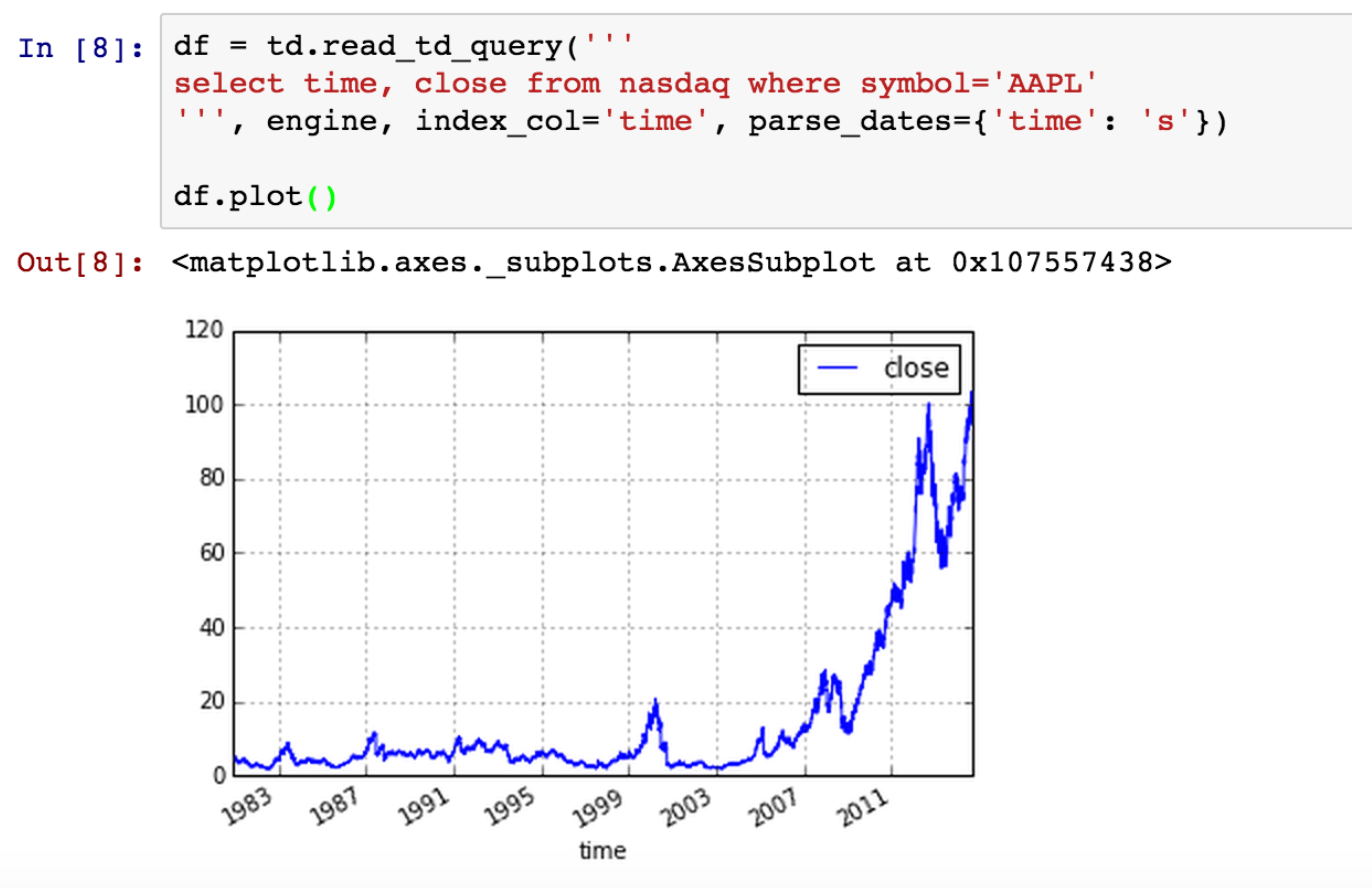
十分に小さいので、すべての行を取得してデータの分析を開始できます:
詳細については、以下の内容を参照してください。
Jupyter Notebook は GitHub でサポートされており、分析セッションの結果をチームと共有できます: