この機能はベータ版です。詳細については、カスタマーサクセス担当者にお問い合わせください。
Amazon Redshift向けのLive Connect Zero-Copyにより、お客様はTreasure Data Customer Data Platform (CDP)を使用して、Extract、Transform、Load (ETL)プロセスを必要とせずにRedshift上のデータにアクセスできます。このアプローチは、セキュリティを強化し、データ移動に関連するコストを削減します。Treasure Data環境から直接Redshiftに保存されているデータのシームレスな統合とクエリを可能にします。
RedshiftデータウェアハウスからのZero-Copyの実行は、Treasure Data Redshiftインテグレーションを活用してフェデレーテッドクエリを実行します。データフローは次のようになります:
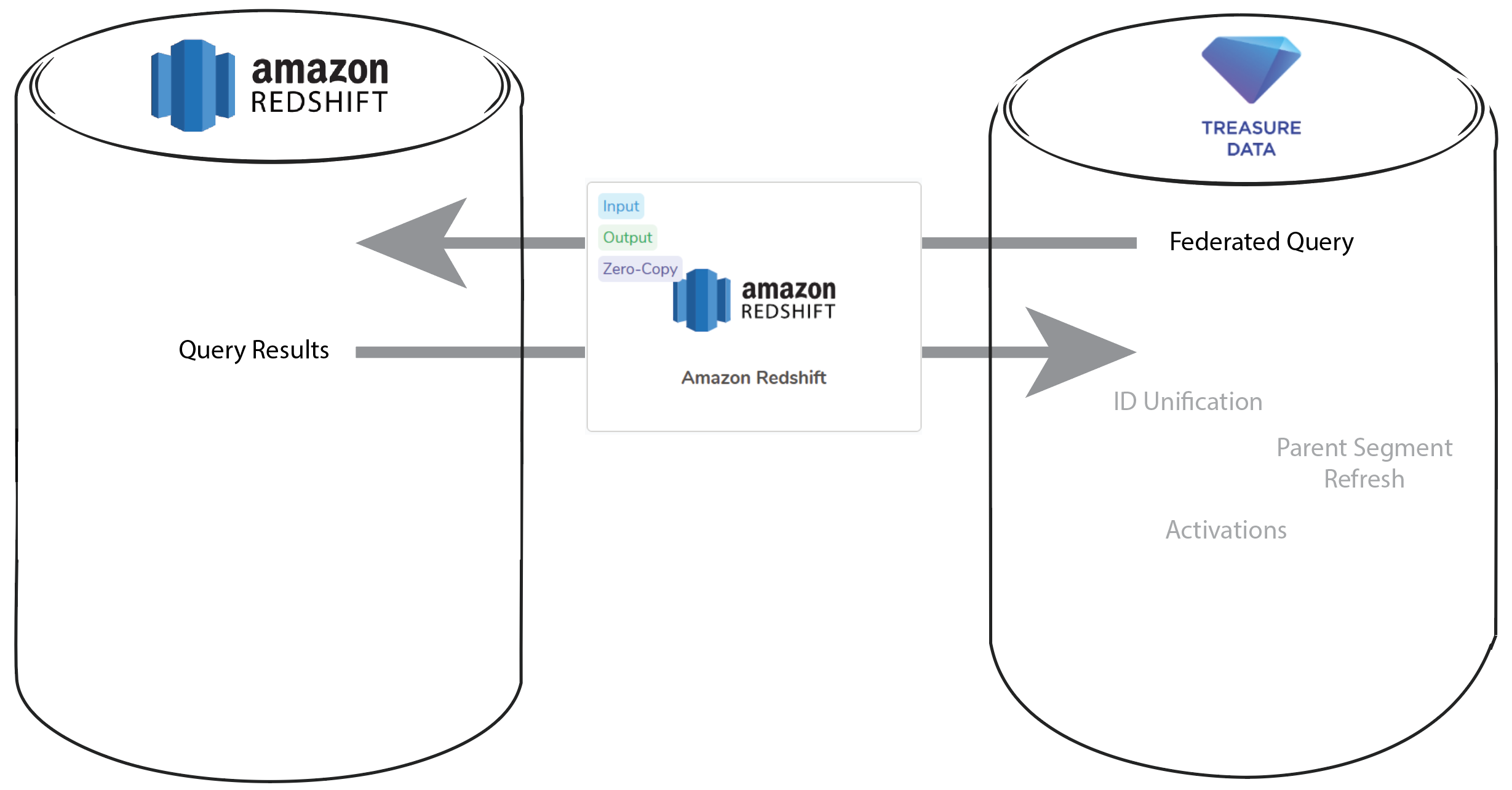
フェデレーテッドクエリにより、データエンジニアは認証情報を使用して外部データウェアハウスに接続し、データにアクセスしてクエリを実行できます。この機能により、迅速なデータ拡張が可能になり、データエンリッチメントプロセスの効率が向上します。フェデレーテッドクエリを使用することで、データエンジニアは現在のニーズに基づいて外部データと内部データを動的にクエリおよび結合でき、柔軟性が提供され、複雑なETLプロセスの必要性が軽減されます。このアプローチにより、リアルタイムのデータアクセス、データガバナンスとセキュリティの向上、およびデータ管理の簡素化も保証されます。
Redshiftでzero-copyを実装するための手順は、概略として以下の通りです:
- TD Integration Hubで、Redshiftインテグレーションを使用して認証を作成します。
- 新しいZero-Copyソースを作成し、Redshift認証情報と接続情報を指定します。
- TD Data Workbenchで、新しいQueryを作成します。クエリするテーブル名の前に、作成したばかりのzero-copyソースの名前を付けます。例えば、次のように設定されたsnowflake_connという名前のZero-Copy (Federated Query)設定がある場合:
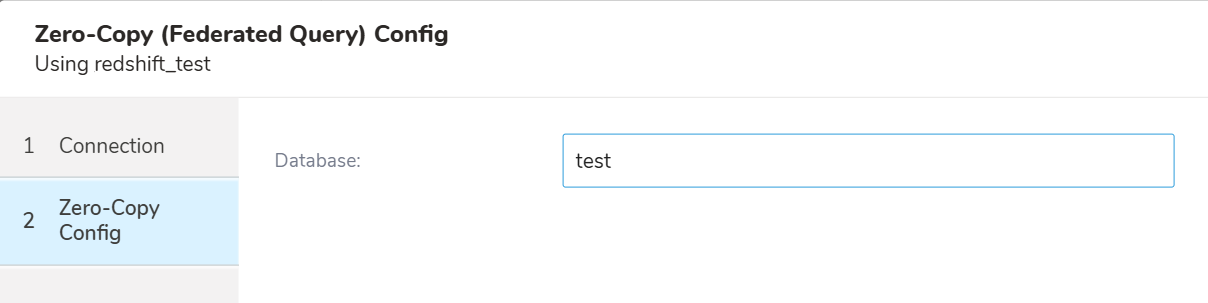 次のように、testデータベースのtable1のクエリを指定できます:
次のように、testデータベースのtable1のクエリを指定できます:
select * from redshift_test.test_schema.table1
test_schemaはRedshiftのスキーマ名です。
- クエリを実行した後、結果を処理して既存のオーディエンスプロファイルを更新または拡張します。
Treasure Dataがクエリ結果の処理を完了した後、クエリ結果は7日後に削除されます。ただし、INSERT INTOオプションを使用して、クエリ結果をTreasure Dataに保存できます。
RedshiftでのZero-Copyには、以下の制限があります:
- カタログ名の長さは64文字を超えることはできません。
- カタログ名のプレフィックスはredshift_で始まる必要があります。
- 同じアカウントのすべてのDWHにわたって200を超える「Zero-Copy (Federated Query) Configs」を持つことはできません。
- フェデレーテッドクエリはTrinoでのみ利用可能です。
- クエリあたりの入力サイズ制限は10GBです。(Trinoプレビュークラスターでは利用できません。)
- カタログ反映時間:最大5分(新しく作成されたzero-copyカタログまたはカタログの変更が反映されるまで最大5分かかります。)