Treasure DataのData Connector用JSON parserプラグインは、JSONデータを解析します。以下のオプションを使用できます:
| オプション | 説明 | 必須? |
|---|---|---|
stop_on_invalid_record | ファイルに無効なレコードが含まれている場合、バルクロードトランザクションを停止します。 | デフォルトはfalse |
| invalid_string_escapes | 無効なJSON文字列のエスケープ戦略(以下を参照) | デフォルトはPASSTHROUGH |
| root | JSON Pointer式を使用してレコードとしてJSONオブジェクト値を指定する場合に使用 | オプション |
| flatten_json_array | JSON配列内の要素を複数のレコードとして扱いたい場合はtrueに設定します。 | デフォルトはfalse |
| columns | カラム(以下を参照) | オプション |
flatten_json_arrayを設定すると、パーサーは処理前にJSON配列全体を読み込んで保存するために大量のメモリを必要とするため、ジョブが失敗する可能性があります。大きなJSON配列が1つだけある場合、Treasure DataはJSON配列内のJSONオブジェクトの数を減らすか、以下の例のようにJSONオブジェクトを抽出して保存することをお勧めします:
{"time":1455829282,"ip":"93.184.216.34","name":"frsyuki"}
{"time":1455829282,"ip":"172.36.8.109","name":"sadayuki"}
{"time":1455829284,"ip":"example.com","name":"Treasure Data"}
{"time":1455829282,"ip":"10.98.43.1","name":"MessagePack"}invalid_string_escapesを設定し、パーサーが無効なJSON文字列に遭遇した場合、以下のアクションを実行します:
| invalid_string_escapes | 変換先 |
|---|---|
| PASSTHROUGH | \a |
| SKIP | 空文字列 |
| UNESCAPE | a |
columnsオプションはカラムのリストを宣言し、パーサーがJSON値をカラムに抽出する方法を指定します。
| 名前 | 説明 |
|---|---|
| name | カラムの名前。element_atが指定されていない場合、この名前のJSON値が抽出されます。 |
| type | カラムの型(CSV parserで使用されるものと同じ) |
| element_at | カラムとして抽出する子孫要素。相対JSON Pointerとして表現(オプション) |
| format | 要素がtimestamp型の場合のタイムスタンプの形式 |
guessコマンドを使用してload.ymlを生成することで、パーサーを自動的にJSONに設定できます。または、load.ymlのparserセクションのtypeをjsonに設定します。例:
in:
...
parser:
type: json
out:
...以下の例は、ソースファイルがJSONデータの場合と.ymlファイルの設定方法を示しています。
- ソースデータの例
{"time":1455829282,"ip":"93.184.216.34","name":"frsyuki"}
{"time":1455829282,"ip":"172.36.8.109","name":"sadayuki"}
{"time":1455829284,"ip":"example.com","name":"Treasure Data"}
{"time":1455829282,"ip":"10.98.43.1","name":"MessagePack"}load.ymlの例は以下の通りです。
in:
...
parser:
type: json
...previewコマンドで解析されたJSONデータを表示できます。以下の例ではrecordカラムと名付けられています。
$ td connector:preview load.yml+---------------------------------------------------------------------------+
| record:json |
+---------------------------------------------------------------------------+
| "{\"ip\":\"93.184.216.34\",\"time\":1455829282,\"name\":\"frsyuki\"}" |
| "{\"ip\":\"172.36.8.109\",\"time\":1455829282,\"name\":\"sadayuki\"}" |
| "{\"ip\":\"example.com\",\"time\":1455829284,\"name\":\"Treasure Data\"}" |
| "{\"ip\":\"10.98.43.1\",\"time\":1455829282,\"name\":\"MessagePack\"}" |
+---------------------------------------------------------------------------+- Treasure Dataテーブルにインポートします。
$ td connector:issue load.yml --database <database name> --table <table name> --auto-create-table結果のテーブルは以下の通りです:
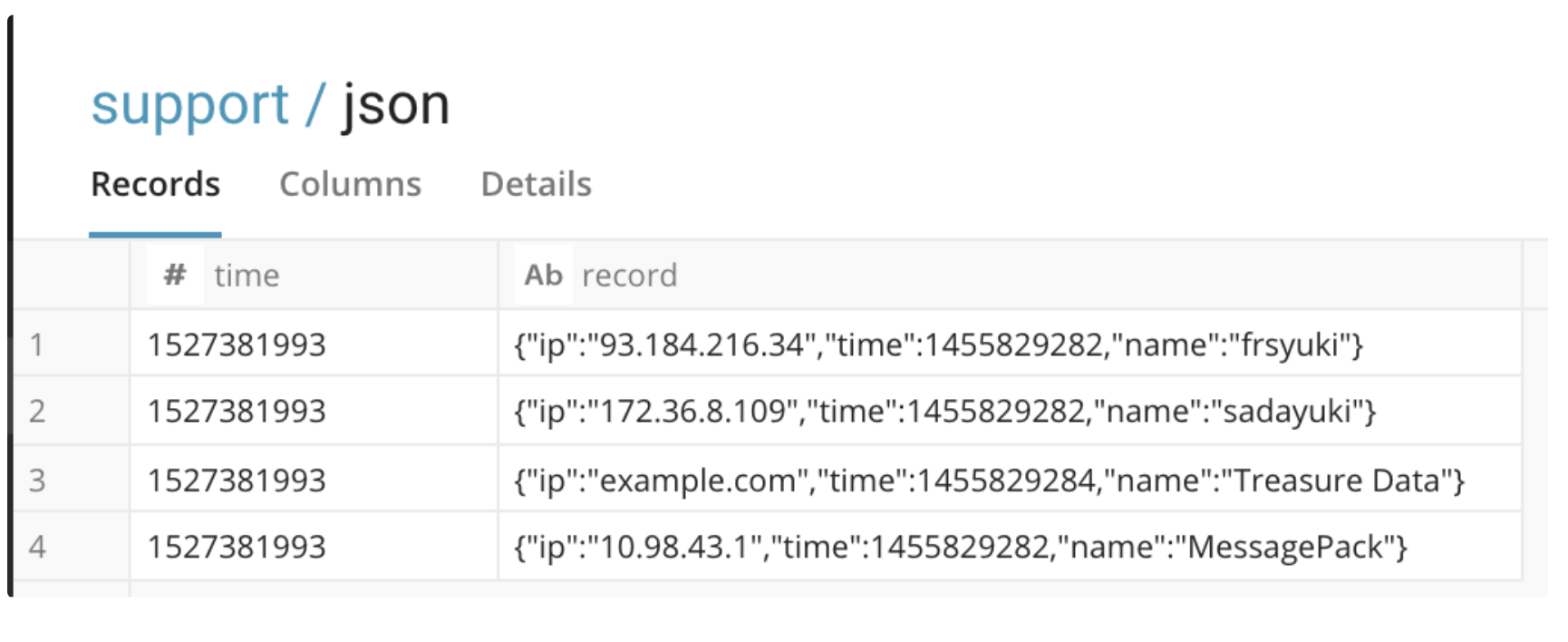
JSONデータはstring型として表示されますが、JSON Functionsを以下のように使用できます:
SELECT
json_extract(
record,
'$.ip'
) AS IP
FROM
jsonip
"93.184.216.34" "172.36.8.109" "example.com" "10.98.43.1"
以下の例は、ソースファイルがJSONデータの場合と.ymlファイルの設定方法を示しています。
ソースデータの例
{"time":1455829282,"user_info":{"ip":"93.184.216.34","name":"frsyuki"}}
{"time":1455829282,"user_info":{"ip":"172.36.8.109","name":"sadayuki"}}
{"time":1455829284,"user_info":{"ip":"example.com","name":"Treasure Data"}}
{"time":1455829282,"user_info":{"ip":"10.98.43.1","name":"MessagePack"}}サブJSONは以下の通りです:
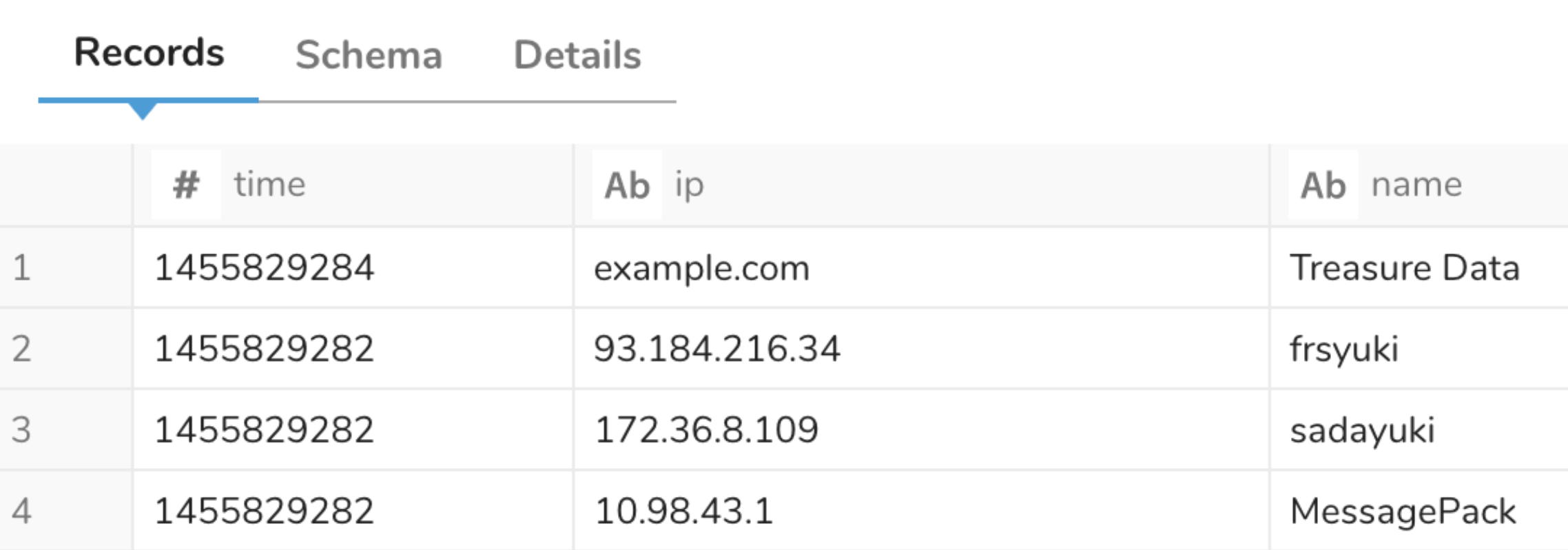
{"ip":"93.184.216.34","name":"frsyuki"}ファイルを展開するようにData Connectorを設定できます。
in:
...
parser:
type: json
columns:
- name: time
type: long
- name: ip
type: string
element_at: /user_info/ip
- name: name
type: string
element_at: /user_info/name
out:
...結果は以下の通りです:
flatten_json_arrayをtrueに設定することで、JSON配列をフラット化できます。
in:
...
parser:
type: json
flatten_json_array: true
root: /records- 入力例
{
"records": [
{"col1":1,"col2":"test1"},
{"col1":2,"col2":"test2"}
]
}以下のようにJSON配列をフラット化することで2つのレコードを確認できます。
$ td connector:preview load.yml+-----------------------------------+
| record:json |
+-----------------------------------+
| "{\"col1\":1,\"col2\":\"test1\"}" |
| "{\"col1\":2,\"col2\":\"test2\"}" |
+-----------------------------------+
2 rows in set