Treasure Workflowを使用すると、複数のタスクで構成されるワークフローを作成し、そのワークフローを定期的に実行するようにスケジュールできます。 このトピックでは、TDコンソールでのワークフローの参照および作成について、最も基本的な内容を説明します。
Workflowsページでは、アカウント内にすでに定義されているワークフローを一覧表示することができます。 ワークフローにはユーザー定義ワークフローとシステムワークフローの2種類があります。
ユーザー定義ワークフロー: ユーザーによって作成・管理されるワークフローです。 ユーザー定義ワークフローはカスタムタスクを実行し、ユーザーの特定のニーズと要件に合わせてカスタマイズが可能です。 ユーザー定義ワークフローの例としては、データをTreasure Dataへ取り込むためのETLワークフローや、 取り込んだデータを前処理するためのワークフローが挙げられます。
システムワークフロー: Treasure Dataサービスによって自動的に作成されるワークフローです。 ユーザーはこれらのワークフローを作成または変更することはできませんが、ユーザーインターフェースを通じてアクセスできます。 システムワークフローの例としては、マスターセグメントを更新するaudienceワークフローや、 アクティベーションを実行するsyndicationワークフローが挙げられます。
それぞれを表示するには、Workflowsページの上部にあるセレクターで、表示したいワークフローのタイプを選択します。
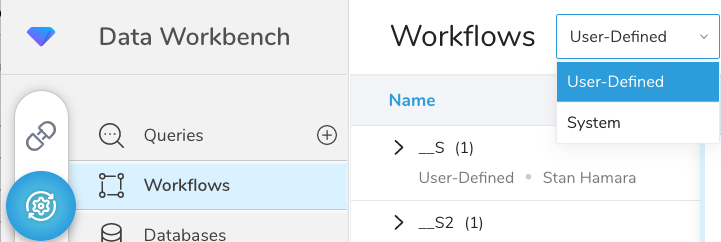
ワークフローランディングページを最初に開くと、Treasure Data は関連するワークフローを含むプロジェクトをツリー構造で表示します。ワークフローを検索するには、各プロジェクトを開いてワークフローを表示できます。オプションで、ワークフローを検索することもできます。
右上で虫眼鏡アイコンを選択します。

検索する文字列を入力します。
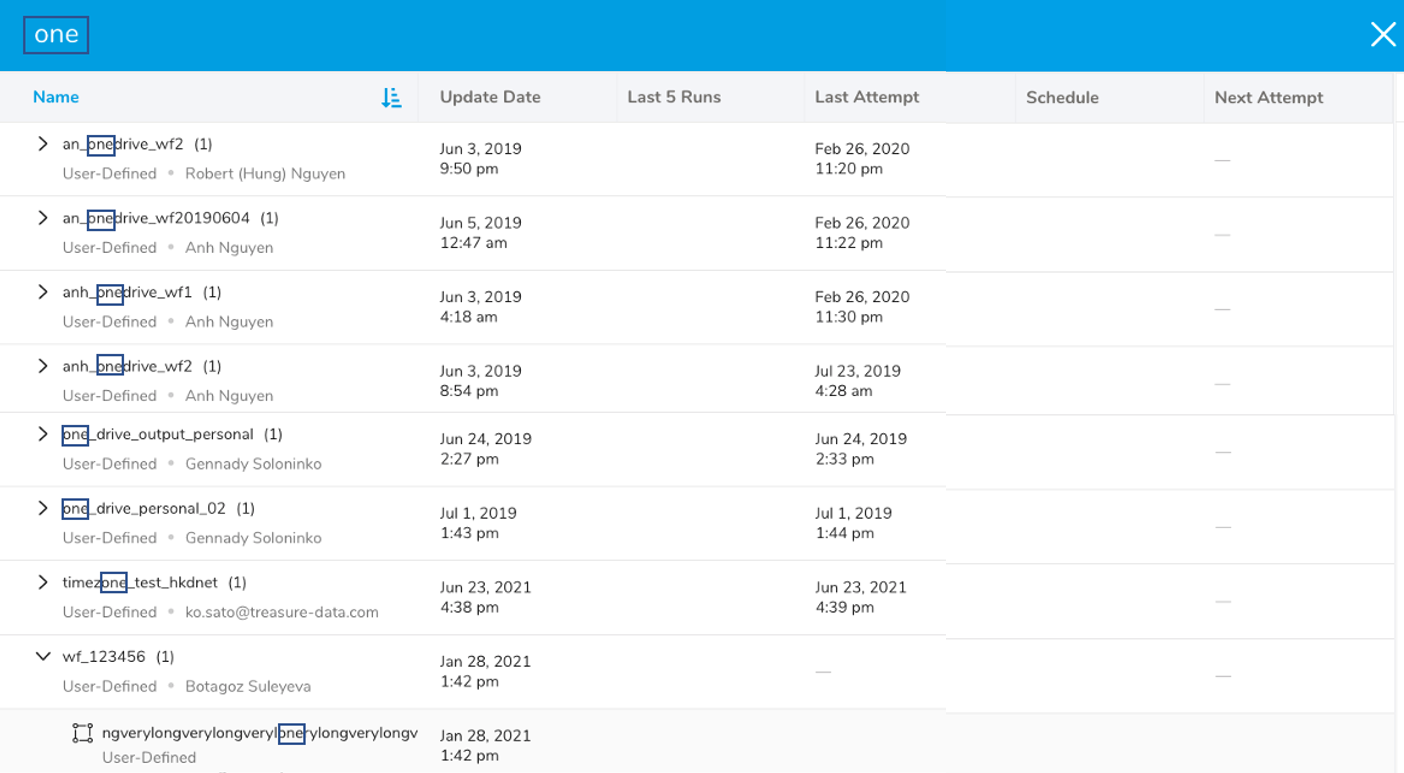
前の例では、「one」という用語を使用して検索しました。最後のエントリでは、ワークフロー名にその文字を含むネストされたワークフローが表示されています。
Name カラムの右にあるソートアイコンを選択します。
Sort workflow across projects by name を選択します。
Sort Ascending または Sort Descending を選択してページを更新します。
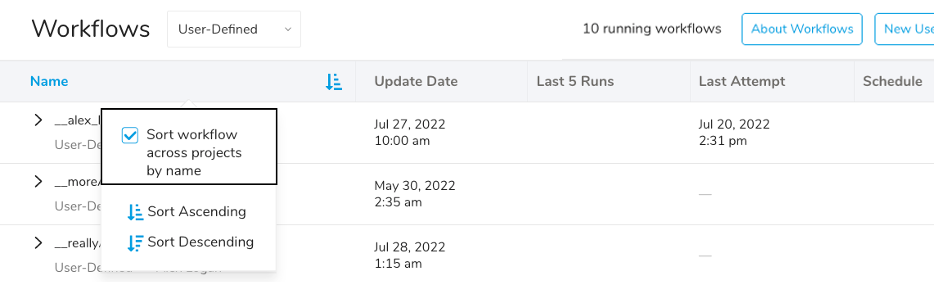
Treasure Data は、プロジェクトと関連づけつつフラットにワークフローを表示します。

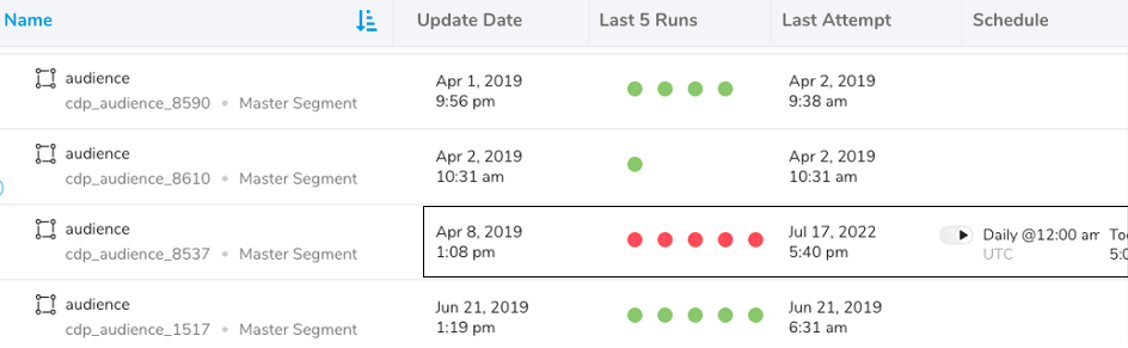
| ステータス名 | アクション | 説明例 |
|---|---|---|
| Update Date | ワークフローが最初に実行された日付を識別します。 | このセグメントは 2019年4月8日午後1時8分に最初に実行されました。 |
| Last 5 Runs | 最後の5回のワークフロー実行試行の成功をすばやく確認します。 | 最後の5回のワークフロー実行はすべて失敗しました。 |
| Last Attempt | 最後に試行されたワークフロー実行を確認します。 | 最後に試行されたワークフロー実行は 2022年7月17日午後5時40分でした。 |
| Schedule | 繰り返しワークフローの場合、スケジュールが表示されます。 | 毎日 UTC タイムゾーンの午前12時。 |
| Next Attempt | Treasure Data が次にワークフローの実行を試行する時間。 | 本日午後5時。 |
ワークフロー一覧でワークフローをクリックすると詳細ペインが開き、そのワークフローの詳細を確認できます。 この詳細ペインではRun history(実行履歴)、Project Revisions(リビジョン一覧)とSecrets(シークレット)を表示することが可能です。

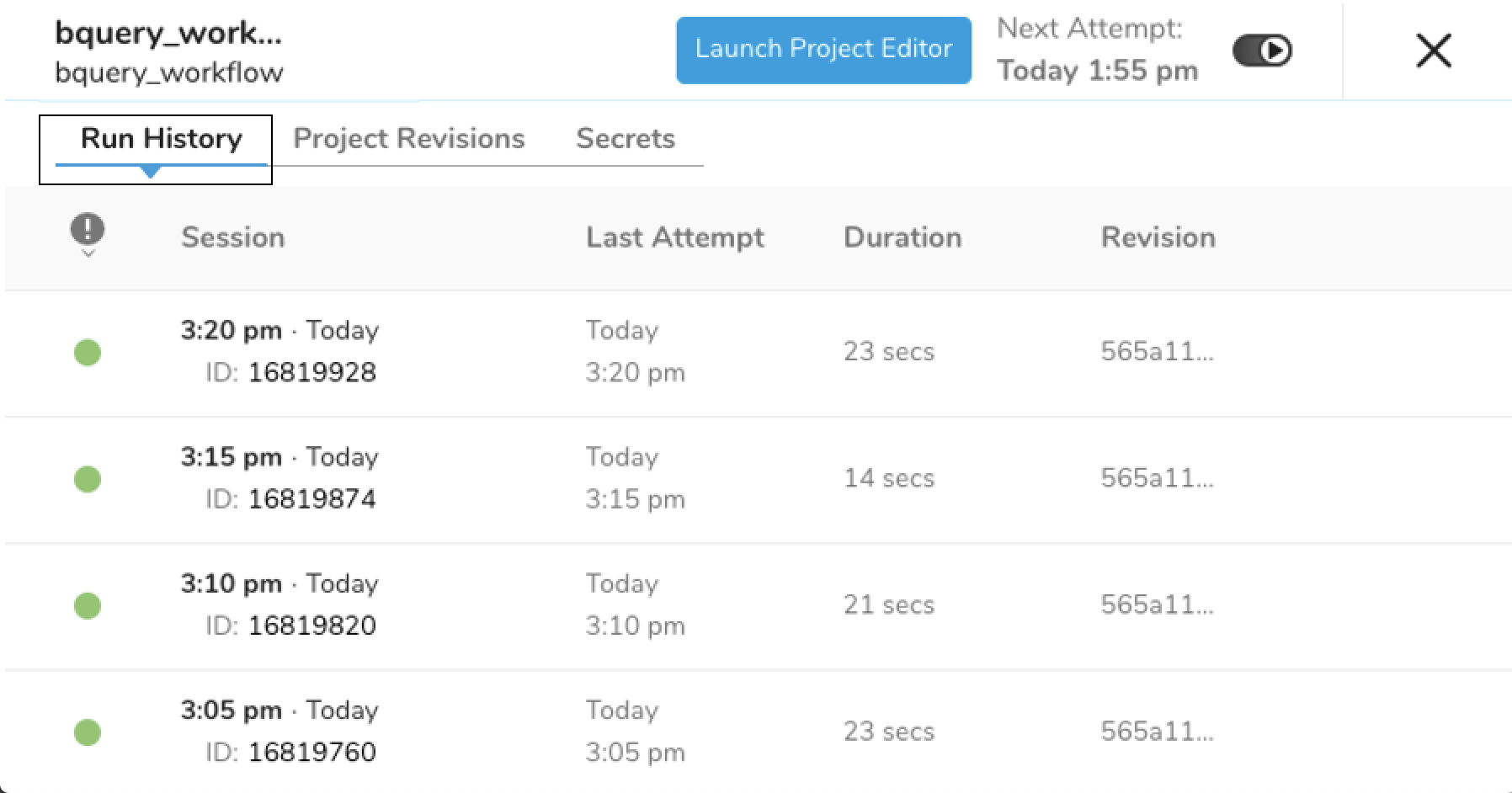
デフォルトのタブはRun History(実行履歴)です。 各行に1セッションが表示され、セッションの実行状況(丸アイコン)、セッション情報(Session)、 最後の実行(Last Attempt)、実行時間(Duration)と実行したワークフローのリビジョン(Revision)を確認できます。
各履歴をクリックすると、それぞれの実行の詳細を開くことができます。
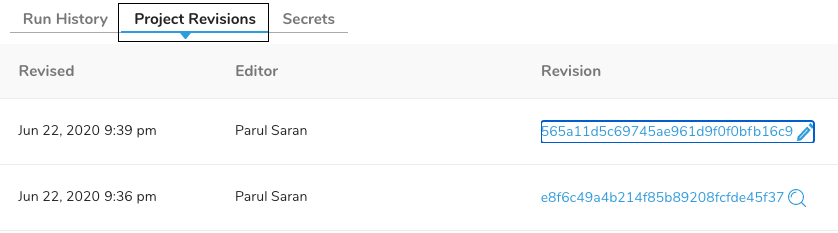
Project Revisionsタブでは、新しい順にワークフローの変更履歴を確認できます。 変更日時(Revised)、変更者(Editor)、変更後のリビジョン(Revision)が見られます。
リビジョン欄に鉛筆のアイコンがある場合は、そのリビジョンにワークフロー(.digファイル)が含まれることを示します。 虫めがねアイコンがある場合は、ワークフローは含まれません。

Secretタブではそのプロジェクトに紐付けられたシークレット一覧を見ることができます。 シークレットはパスワードやアクセストークンのような秘密の文字列です。 このタブで "+" アイコンをクリックすることで、新しいシークレットを追加することもできます。
Workflowsページから新しいワークフローを作成することができます。 以下の手順に従って、最初のワークフローを作成、編集、実行してみましょう。 このワークフローはデータをTreasure DataへロードしてSQLで処理するワークフローです。
このワークフローを実行するには、Treasure Data上にデータベースとテーブルが必要です。
まず、Workflowsページで「New User-Defined Workflow」ボタンをクリックします。

「Create Workflow」ペインが開くので、Workflow Name欄にワークフロー名を入力します。 このチュートリアルでは「my_first_workflow」としておきましょう。
Project Name欄のプロジェクト名はデフォルトでワークフロー名と同じになります。 そのままにしても構いませんし、別の名前に変更することもできます。 このチュートリアルではワークフロー名と同じにしておきます。
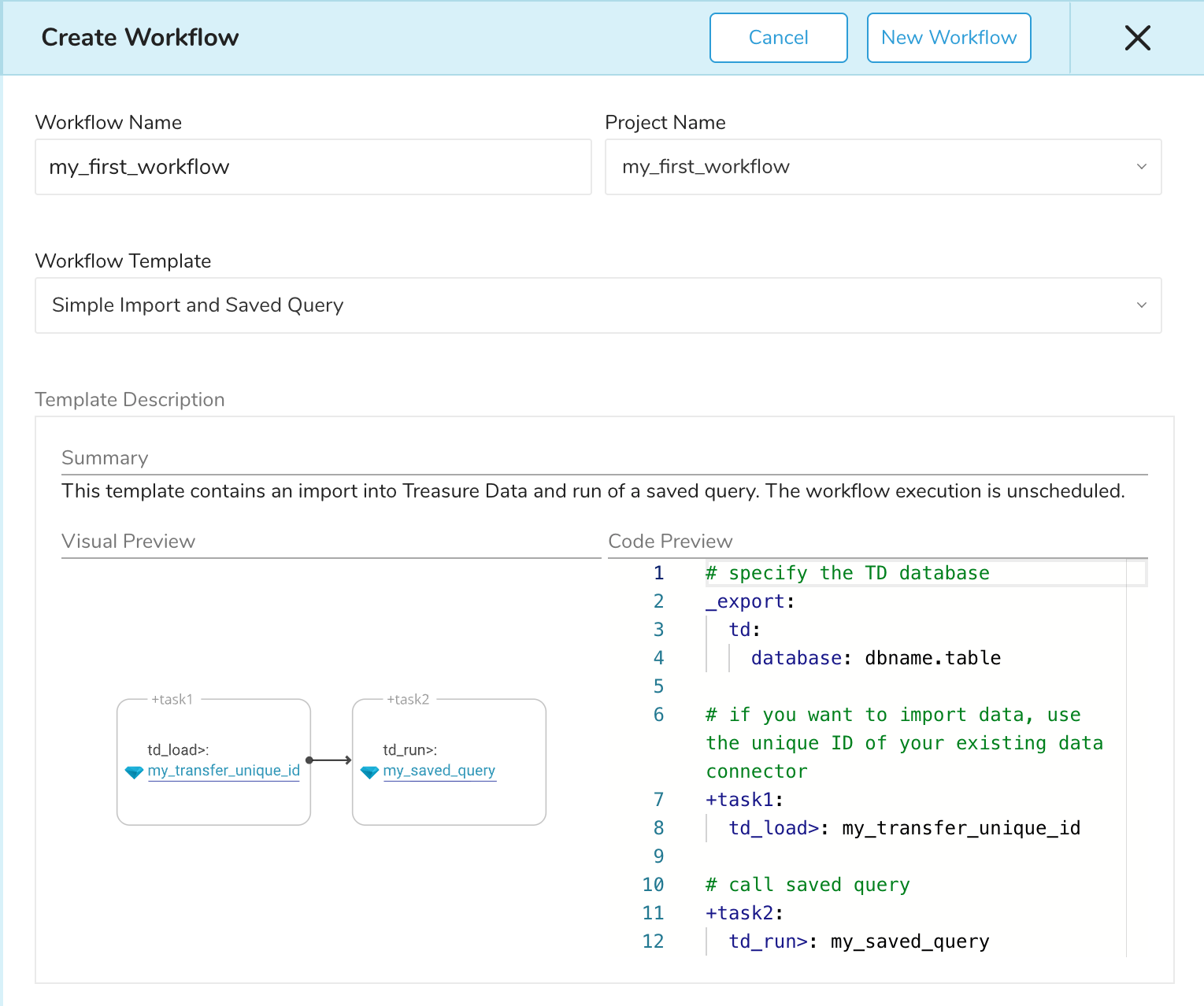
「Workflow Template」欄から、ワークフローのテンプレートを選ぶことができます。 このチュートリアルでは "Simple Import and Saved Query" テンプレートを選択してください。 なお、環境によってはわかりにくいですが、このテンプレートリストはスクロールできます。
最後に「New Workflow」ボタンをクリックしてワークフロープロジェクトを作成してください。
ワークフロープロジェクトを作成すると、プロジェクトを編集するためのエディターが表示されます。
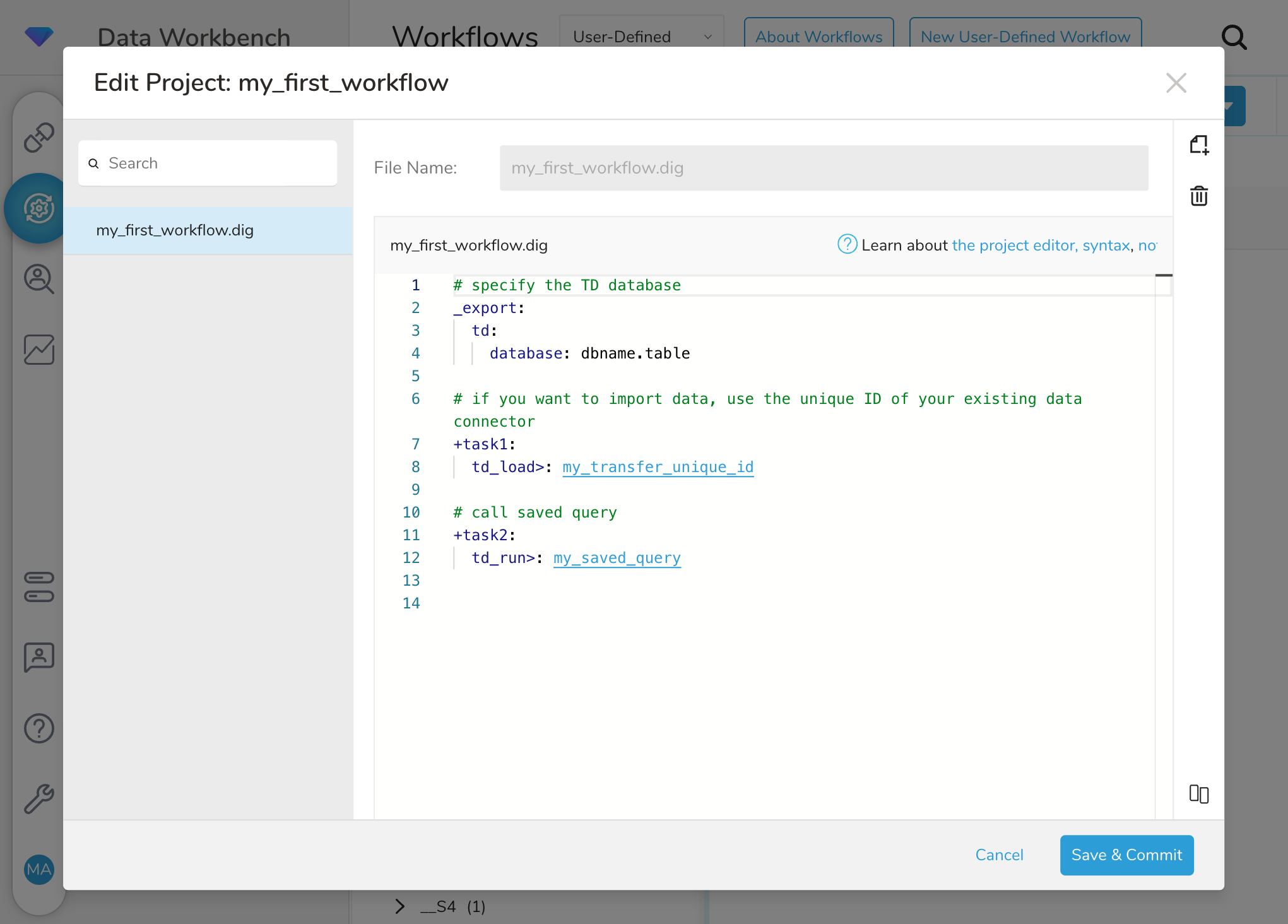
このプロジェクトエディターではワークフロー(.digファイル)を含む様々なファイルをプロジェクトに追加し、 編集することができます。
デフォルトではプロジェクト内の最初のファイルが開かれています。 現在はプロジェクトにワークフローファイルmy_first_workflow.digだけが存在するので、そのファイルが開かれているはずです。
各コードセクションには、ハッシュタグ(#)から始まる行で説明が含まれています。 これらの行はすべてコメントで、ワークフローの実行時には無視されます。
Workflowコンソールでは、いきなりファイルの内容を変更しはじめることはできません。 ワークフローの編集を開始するには、まず "Edit Files" ボタンをクリックして、プロジェクトエディターを編集モードにします。
最初に、ワークフロー内の td.database 欄に記載されている「dbname.table」を自分のデータベース名に書き換えましょう。 td.database は、ワークフロー内のクエリーが実行されるときのTDデータベースを指定する変数です。 例えばクエリーをmy_databaseというデータベース内で実行したいならば、次のように記述します。
_export:
td:
database: my_database編集を終えて変更を保存(コミット)するときは、 "Save & Commit" ボタンをクリックします。 これでワークフロープロジェクトの新しいバージョン(revision)が保存されます。
Treasure WorkflowはYAML構文を使用します。インデントやコロンの使用に十分注意してください。 特に記号はすべて半角文字でなければならず、全角の「:」や「{」、全角空白などはすべてエラーになります。 全角文字が使える個所を理解するまでは、IMEをオフにしておいたほうが無難です。
Treasure Dataはtd_loadオペレーターを使用して、ストレージ、他のデータベース、またはサービスからデータを読み込みます。 この例では、データコネクタのUnique IDを参照します。
TDコンソールで、Integrations Hub > Sourcesに移動します。
コネクタを選択し、次にもっと見るメニュー(…)を選択します。
"Copy Unique ID" をクリックして、Unique IDをコピーします。
これで使用するUnique IDがわかったので、Workflowsページに戻り、 作成中のワークフローをプロジェクトエディターで開きます。
再度 "Edit Files" を選択し、編集モードにしたら、td_load>: の値をUnique IDの値に置き換えます。 最後に再度 "Save & Commit" ボタンをクリックしてワークフローを保存して完了です。
ワークフローはすぐに実行することも、スケジュールを作成して定期的に実行することもできます。 すぐワークフローを実行するには、"New Run" ボタンをクリックします。
これでワークフローが実行されます。 実行状況をモニタリングしたいときは、Run Historyタブから実行中の行をクリックしてください。 詳細画面が開き、タスク実行の様子をモニタリングできます。