# 高可用性のためのTD Agentの設定
高トラフィックのウェブサイトで動作する高可用性のTreasure Agent(td-agent)を設定できます。
* [前提条件](#prerequisites)
* [メッセージ配信のセマンティクス](#message-delivery-semantics)
* [ネットワークトポロジ](#network-topology)
* [ログフォワーダーの設定](#log-forwarder-configuration)
* [ログアグリゲーターの設定](#log-aggregator-configuration)
* [障害ケースシナリオ](#failure-case-scenarios)
* [フォワーダーの障害](#forwarder-failure)
* [アグリゲーターの障害](#aggregator-failure)
* [次のステップ](#whats-next)
# 前提条件
* Treasure Dataの基本的な知識。
* td-agentの基本的な知識。
**ミッションクリティカル**なtd-agentの設定が必要ですか?[Scalability Consultation Service](/support/consultation)をご活用ください。
# メッセージ配信のセマンティクス
td-agentは、主にイベントログ配信システム向けに設計されています。
このようなシステムでは、いくつかの配信保証が可能です:
* *At most once*: メッセージは即座に転送されます。転送が成功した場合、メッセージは二度と送信されません。ただし、多くの障害シナリオでメッセージが失われる可能性があります(つまり、書き込み容量がなくなる)
* *At least once*: 各メッセージは少なくとも1回配信されます。障害の場合、メッセージが2回配信される可能性があります。
* *Exactly once*: 各メッセージは1回だけ配信されます。
システムが「単一のイベントも失えない」場合、かつ「*exactly once*」で転送する必要がある場合、システムは書き込み容量がなくなったときにイベントの処理を停止する必要があります。適切なアプローチは、同期ログを使用し、イベントを受け入れられない場合にエラーを返すことです。
そのため、*td-agentは'At most once'転送を保証しています*。アプリケーションのパフォーマンスに影響を与えることなく大量のデータを収集するには、データロガーは非同期でデータを転送する必要があります。パフォーマンスは、潜在的な配信障害のコストで向上します。
ただし、ほとんどの障害シナリオは予防可能です。
# ネットワークトポロジ
高可用性のためにtd-agentを設定するには、ネットワークが'*log forwarders*'と'*log aggregators*'で構成されていることを前提としています。
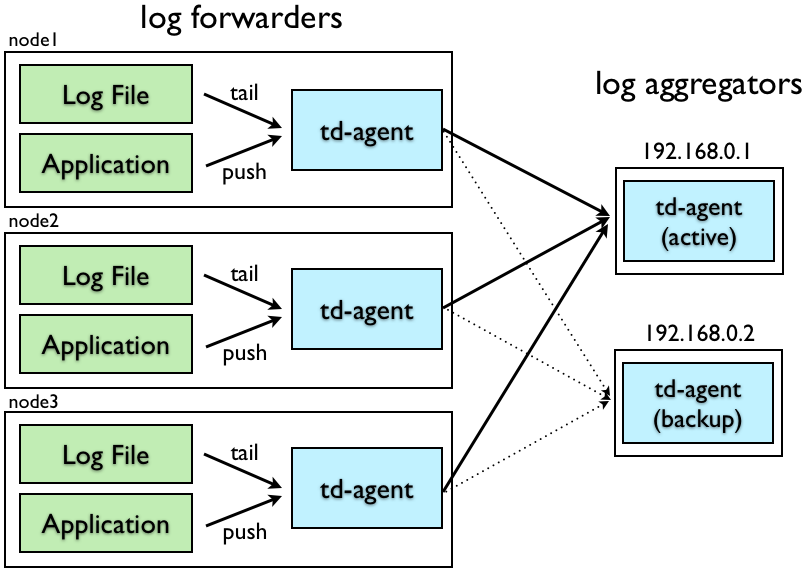
'*log forwarders*'は通常、ローカルイベントを受信するために各ノードにインストールされます。イベントを受信すると、ネットワークを介して'log aggregators'に転送します。
'*log aggregators*'は、log forwardersからイベントを継続的に受信するデーモンです。イベントをバッファリングし、定期的にデータをクラウドにアップロードします。
td-agentは、設定に応じてlog forwarderまたはlog aggregatorのいずれかとして機能できます。以下の情報では、セットアップについて説明します。アクティブなlog aggregatorのIPアドレスが'192.168.0.1'で、バックアップのIPアドレスが'192.168.0.2'であると仮定します。
# ログフォワーダーの設定
log forwardersの/etc/td-agent/td-agent.confファイルに以下の行を追加してください。以下の例は、log forwardersを設定してlog aggregatorsにログを転送する方法を示しています。
```conf
# TCP input
type forward
port 24224
# HTTP input
type http
port 8888
# Log Forwarding
type forward
host 192.168.0.1
port 24224
# use secondary host
host 192.168.0.2
port 24224
standby
# use tcp for heartbeat
heartbeat_type tcp
# use longer flush_interval to reduce CPU usage.
# note that this is a trade-off against latency.
flush_interval 10s
# use multi-threading to send buffered data in parallel
num_threads 8
# expire DNS cache (required for cloud environment such as EC2)
expire_dns_cache 600
# use file buffer to buffer events on disks.
buffer_type file
buffer_path /var/log/td-agent/buffer/forward
# in case buffer becomes full, have local backup
type file
path /var/log/td-agent/buffer/secondary
compress gzip
```
アクティブなaggregator(192.168.0.1)が停止すると、ログはバックアップaggregator(192.168.0.2)に送信されます。両方のサーバーが停止した場合、ログは対応するforwarderノードのディスクにバッファリングされます。
# ログアグリゲーターの設定
log aggregatorsの/etc/td-agent/td-agent.confファイルに以下の行を追加してください。ログ転送の入力ソースはTCPです。
```conf
# TCP input
type forward
port 24224
# Treasure Data output
type tdlog
endpoint api.treasuredata.com
apikey YOUR_API_KEY_HERE
auto_create_table
buffer_type file
buffer_path /var/log/td-agent/buffer/td
use_ssl true
num_threads 8
# in case buffer becomes full, have local backup
type file
path /var/log/td-agent/buffer/secondary
compress gzip
```
受信したログはバッファリングされ、定期的にクラウドにアップロードされます。アップロードが失敗した場合、ログは再送信が成功するまでローカルディスクに保存されます。
Treasure Dataに加えてファイルにログを書き込む場合は、'copy'出力を使用してください。以下のコードは、TD、ファイル、MongoDBに同時にログを書き込むための設定例です。
```conf
type copy
type tdlog
endpoint api.treasuredata.com
apikey YOUR_API_KEY_HERE
auto_create_table
buffer_type file
buffer_path /var/log/td-agent/buffer/td
use_ssl true
type file
path /var/log/td-agent/myapp.%Y-%m-%d-%H.log
localtime
type mongo_replset
database db
collection logs
nodes host0:27017,host1:27018,host2:27019
```
# 障害ケースシナリオ
## フォワーダーの障害
log forwarderがアプリケーションからイベントを受信すると、イベントは最初にディスクバッファ(buffer_pathで指定)に書き込まれます。flush_intervalごとに、バッファリングされたデータがaggregatorsに転送されます。
このプロセスは、本質的にデータ損失に対して堅牢です。log forwarderのtd-agentプロセスが停止した場合、バッファリングされたデータは再起動後にaggregatorに適切に転送されます。forwardersとaggregators間のネットワークが切断された場合、データ転送は自動的に再試行されます。とはいえ、メッセージ損失の可能性があるシナリオは存在します:
* イベントを受信した直後にプロセスが停止したが、バッファに書き込む前。
* forwarderのディスクが壊れ、ファイルバッファが失われた。
## アグリゲーターの障害
log aggregatorsがlog forwardersからイベントを受信すると、イベントは最初にディスクバッファ(buffer_pathで指定)に書き込まれます。flush_intervalごとに、バッファリングされたデータがクラウドにアップロードされます。
このプロセスは、本質的にデータ損失に対して堅牢です。log aggregatorのtd-agentプロセスが停止した場合、log forwarderからのデータは再起動後に適切に再転送されます。aggregatorsとクラウド間のネットワークが切断された場合、データ転送は自動的に再試行されます。
メッセージ損失の可能性があるシナリオは次のとおりです:
* イベントを受信した直後にプロセスが停止したが、バッファに書き込む前。
* aggregatorのディスクが壊れ、ファイルバッファが失われた。
# 次のステップ
td-agentでのデータ管理の詳細については、以下のドキュメントを参照してください:
* [td-agentの監視](/ja/products/customer-data-platform/integration-hub/streaming/td-agent/monitoring-td-agent)
* [Fluentdドキュメント](https://docs.fluentd.org)(td-agentは`Fluentd`としてオープンソース化されています)
* [td-agent変更ログ](/ja/products/customer-data-platform/integration-hub/streaming/td-agent/td-agent-logs-sent-to-treasure-data)